Bilder sind die neue Währung im digitalen Business: Artikel mit passenden Visuals erzielen 94% mehr Aufrufe und visuelle Unterstützung steigert die Nutzerproduktivität um 15%. In einem Internet, das einem Bildlabyrinth gleicht, ist hochwertiger visueller Content laut HubSpot längst kein “Nice-to-have” mehr, sondern ein entscheidender Wettbewerbsvorteil.
Doch wie gelangt man effizient an diese Mengen an Bilddaten, ohne wertvolle Zeit mit manuellem Speichern zu verlieren? In diesem Artikel zeigen wir Ihnen fünf effektive Methoden zum Scrapen von Bildern vor: Von benutzerfreundlichen Tools wie Octoparse bis hin zu Python-Skripten für Fortgeschrittene.
Persönliche Erfahrung: Vergleich verschiedener Scraping-Tools
Ich selbst habe Octoparse ausprobiert, als ich für meinen kleinen Online-Shop Produktbilder von mehreren Lieferantenseiten gesammelt habe. Am Anfang war ich skeptisch, denn ich dachte, es ist ein bisschen zu technisch für mich. Ich war aber schnell überrascht, wie einfach die Bedienung ist. Besonders die Auto-Detection-Funktion hat mir viel Zeit gespart. Statt jede Seite manuell zu durchsuchen, konnte ich alle Bilder in wenigen Minuten herunterladen. Auch das automatische Speichern in Ordnern hat super funktioniert. Beim Sortieren gab es bei mir absolut kein Chaos, was mich ehrlich gesagt, selbst ein wenig überrascht hat.
Im Laufe der Zeit habe ich mehrere Tools getestet. Darunter Image Cyborg, Extract.pics und ein paar Browser-Erweiterungen. Für kleine Aufgaben reichen diese aus. Aber sobald man regelmäßig oder größere Datenmengen scrapen möchte, kommt ist Octoparse besser und vor allem auch schneller. Besonders die Möglichkeit, Scraping-Prozesse in der Cloud zu planen, ist Gold wert, wenn man wiederkehrende Aufgaben automatisieren will.
| Tool/ Methode | Benutzerfreundlichkeit | Automatisierung | Export-Optionen | Ideal für |
|---|---|---|---|---|
| Octoparse | ⭐⭐⭐⭐⭐ (Drag-and-Drop) | ⭐⭐⭐⭐⭐ (Cloud-basiert) | Excel, CSV, ZIP | Einsteiger & Massen-Scraping |
| Image Cyborg | ⭐⭐⭐⭐ (Web-App) | ⭐⭐ (Manuell) | ZIP | Schnelle URL-Listen |
| Extract.pics | ⭐⭐⭐ (Vorschau) | ⭐⭐ (Limits) | Download | Kostenlose Tests |
| Browser-Erweiterungen | ⭐⭐⭐ (Einfach) | ⭐ (Manuell) | Ordner | Gelegentliche Downloads |
| Python-Skript | ⭐⭐ (Coding nötig) | ⭐⭐⭐⭐ (Automatisiert) | Dateien | Entwickler & Custom-Jobs |
Octoparse – Das beste Image-Scraping-Tool (empfohlen)
Octoparse ist Ihr Go-to-Tool für automatisiertes Scrapen von Bildern. Es erkennt Bilder automatisch, handhabt Paginierung und unendliches Scrollen – ideal für E-Commerce-Seiten. Unterstützt Formate wie JPG, PNG, GIF und sogar PDFs.
Vorteile:
- Kein Coding nötig (Auto-Detection).
- IP-Rotation gegen Blocks.
- Cloud-Automatisierung für tägliche Runs.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Schritt-für-Schritt-Anleitung: Bilder mit Octoparse scrapen
1. URL eingeben: Starten Sie Octoparse und fügen Sie die Ziel-URL ein.
2. Bild auswählen: Klicken Sie auf ein Bild und wählen Sie „Ähnliche Elemente auswählen“.
3. Bild-URL extrahieren: Wählen Sie „Bilddatei“ – Vorschau zeigt URLs und Pfade.
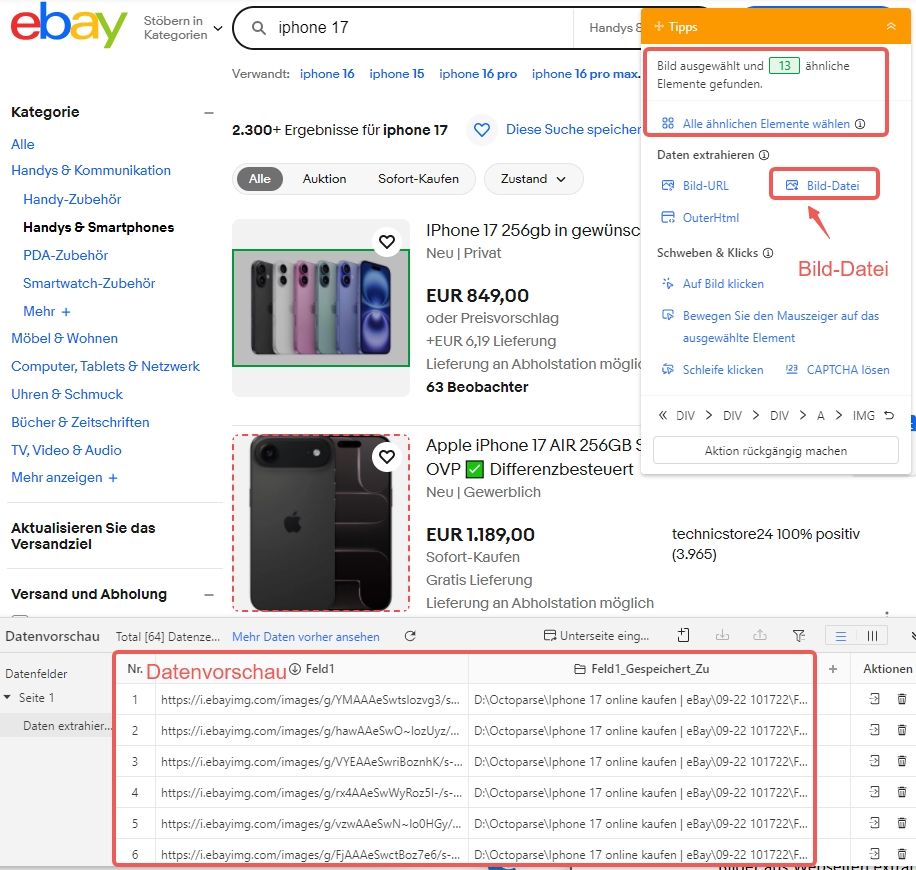
4. Einstellungen anpassen: Im Client-Fenster definieren Sie Download-Ordner und Qualität.
5. Ausführen: Klicken Sie „Start“ – Bilder landen automatisch in Ihrem Ordner.

In diesem Tutorial erwartet Sie eine detaillierte Schritt-für-Schritt-Anleitung, mit der Sie Bilder und Dateien mühelos von jeder Webseite scrapen und herunterladen können.
2 Online-Tools zum Herunterladen von Bildern aus der URL-Liste
Vergessen Sie, welchen Browser Sie verwenden. Versuchen Sie es mit einem Webseitentool zum Herunterladen der Bilder, wenn Sie nichts auf Ihren Geräten installieren möchten.
1. Image Cyborg – Kostenlos und blitzschnell
Image Cyborg ist eine Web-App, die schnell alle Bilder einer Webseite herunterlädt.
Dieses Tool verfügt über eine einfache und übersichtliche Startseite, genau wie eine Suchmaschine.
Nachteile: Oft Thumbnails; keine Metadaten.
Tipp: Für Web Scraping Bilder in niedriger Auflösung perfekt.
💡 Praxistipp aus der Redaktion: Image Cyborg stößt bei Lazy-Loading-Webseiten (Bilder laden erst beim Scrollen) oft an seine Grenzen. Mein Trick: Öffnen Sie die Zielseite einmal komplett im Browser und scrollen Sie bis zum Ende, bevor Sie die URL bei Image Cyborg eingeben. So stellen Sie sicher, dass der Crawler möglichst viele Bildpfade direkt erfassen kann.
2. Extract.pics – Mit Vorschau und Limits
Extract.pics ist ein weiteres Tool für Computerfreaks mit einer einfachen und übersichtlichen Benutzeroberfläche.
Das Beste daran ist, dass Sie alle Bilder vor dem Herunterladen in der Vorschau anzeigen und auswählen oder die Auswahl aufheben können.
Fehlerbehebung: Bei Blocks manuell per Rechtsklick laden.
Ideal für Bilder aus Webseiten extrahieren ohne Registrierung.
💡 Praxistipp aus der Redaktion: Nutzen Sie bei Extract.pics unbedingt die Sortier- und Filterfunktion nach Breite oder Höhe. Dies ist der schnellste Weg, um minderwertige Icons oder Tracker-Pixel von den eigentlichen hochauflösenden Produktfotos oder Beitragsbildern zu trennen. So sparen Sie sich das nachträgliche Aussortieren auf Ihrer Festplatte.
Top 2 Image Downloader-Erweiterungen
1. Firefox – Integrierter Medien-Manager
Mit Firefox Bilder speichern ist ganz einfach. Ein Rechtsklick auf das Bild genügt, um es herunterzuladen. Mit den folgenden Schritten können Sie schnell alle Bilder aus Webseiten extrahieren.
Hier wird die Website Pexels als Beispiel genommen.
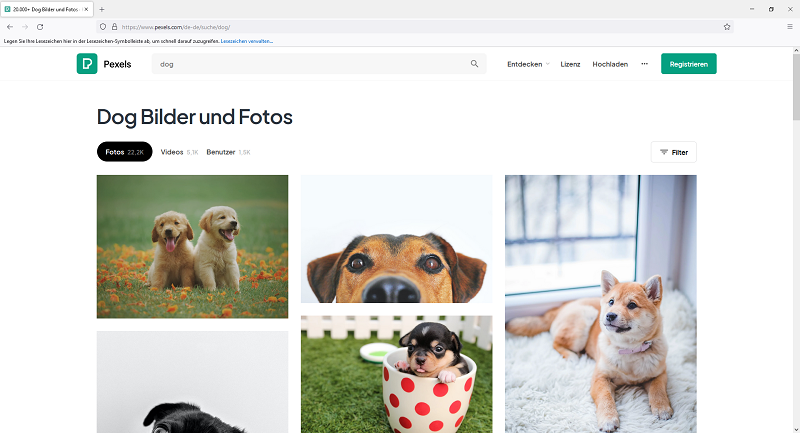
✅ Schritt 1: Öffnen Sie mit Firefox die Website, von der Sie Bilder scrapen möchten.
✅ Schritt 2: Drücken Sie die Tastenkombination Ctrl+i (Strg+i). Damit öffnen sich die Seiteninformationen. Wechseln Sie ins Register Medien. Dann wird die Liste aller Bilder auf der Website angezeigt.
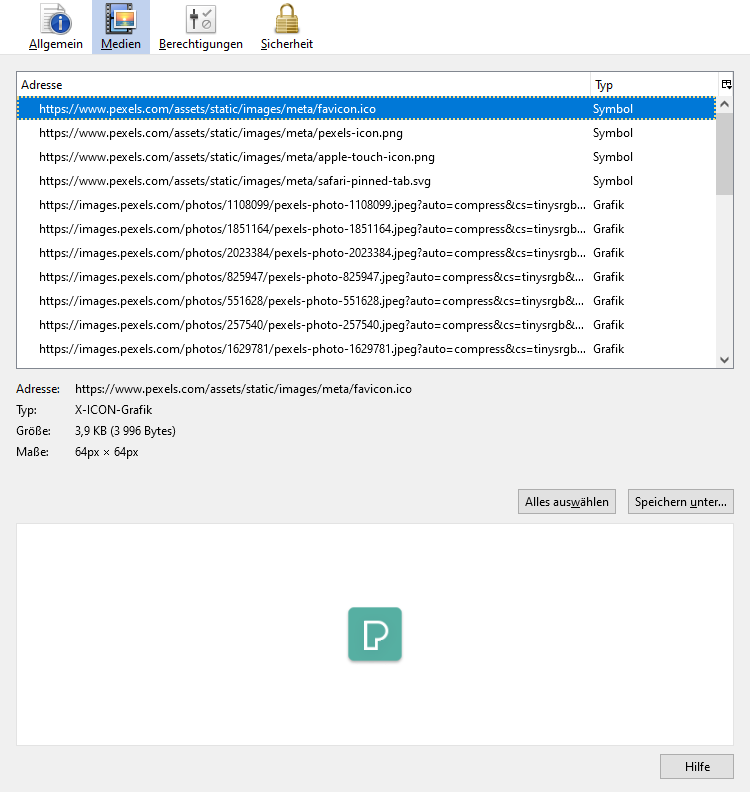
✅ Schritt 3: Klicken Sie auf “Alles auswählen“. Anschließend müssen Sie auf “Speichern unter“ drücken. Jetzt erhalten Sie alle Bilder aus der Website!
Hinweis: Funktioniert für Scrapen von Bildern auf statischen Seiten.
💡 Praxistipp aus der Redaktion: Die Liste in Firefox kann sehr lang sein. Nutzen Sie die Spalten-Sortierung, um den Überblick zu behalten: Klicken Sie auf den Spaltenkopf “Typ”, um alle JPEGs oder PNGs zu gruppieren. So können Sie unnötige SVG-Icons oder Tracking-Pixel (meist 1×1 große GIF-Dateien) schnell identifizieren und von der Auswahl ausschließen. Wichtig: Da Firefox keine Vorschau-Bilder in der Liste skaliert, achten Sie auf die Spalte “Größe”, um die hochauflösenden Originale zu finden.
2. Chrome oder Edge – Image Downloader-Erweiterung
Wenn Sie den Chrome-Browser verwenden, ist ein Bild-Downloader für Chrome eine gute Wahl.
Edge-Benutzer können den Microsoft Edge Image Downloader ausprobieren.
Schritt 1: Installieren Sie die Erweiterung
Installieren Sie die Image Downloader-Erweiterung
Öffnen Sie Google Chrome und rufen Sie die offizielle Seite der Image Download-Erweiterung auf. Klicken Sie oben rechts auf die Schaltfläche „Zu Chrome hinzufügen“ und bestätigen Sie die Auswahl im angezeigten Fenster mit einem Klick auf„ Erweiterung hinzufügen“.
Schritt 2: Zugriff auf die Zielseite
Sobald die Erweiterung installiert ist, gehen Sie zu der Webseite, auf der sich die Bilder befinden, die Sie herunterladen möchten.
Schritt 3: Bildanalyse starten
Klicken Sie oben rechts im Browser auf das Symbol zum Herunterladen von Bildern (ein weißer Pfeil auf blauem Grund). Die Erweiterung beginnt mit der Analyse der Seite und der Suche nach verfügbaren Bildern.
Schritt 4: Auswählen und herunterladen
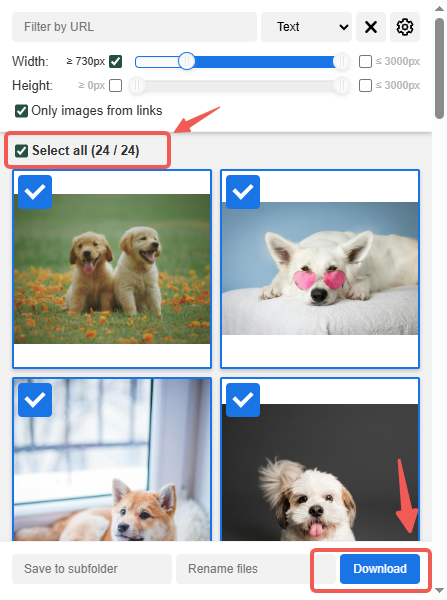
Auswählen und herunterladen mit Image Downloader
Nach einigen Sekunden öffnet sich ein Fenster mit der Liste der gefundenen Bilder. Aktivieren Sie „Alle auswählen“, um alles einzuschließen, und klicken Sie anschließend auf die Schaltfläche „Herunterladen“.
Hinweis: Sie werden auf dem oben gezeigten Bild feststellen, dass dieses Tool einen Filter bietet, mit dem Sie kleine Symbole entfernen und nur Bilder der gewünschten Größe herunterladen können.
Schritt 5: Download abschließen
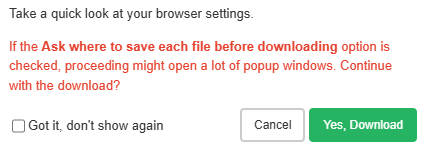
Schließen Sie den Download mit dem Image Downloader ab
Bestätigen Sie mit „JA“, um den Download zu starten. Falls Sie die Möglichkeit haben, den Browser nach dem Speicherort fragen zu lassen, deaktivieren Sie diese Option in den Einstellungen für einen reibungsloseren Ablauf. Alle herunterladbaren Bilder werden in einem Popup-Fenster angezeigt.
Hinweis: Sie werden feststellen, dass dieses Tool einen Filter bietet, mit dem Sie diese kleinen, winzigen Symbole loswerden und nur die Bilder in normaler Größe herunterladen können, die Sie benötigen.
💡 Praxistipp aus der Redaktion: Die mächtigste Funktion dieses Tools ist der Größenfilter (Width/Height). Setzen Sie den Filter vor dem Herunterladen auf mindestens 300×300 Pixel. Dadurch werden Header-Icons, Social-Media-Logos und Werbe-Banner automatisch ausgeblendet, und Sie erhalten nur den relevanten Content.
So scrapen Sie Bilder mit Python
Wenn Sie ein Entwickler sind, gibt es wohl keine Grenzen für Scrapen. Sie können Codes schreiben und alles erreichen.
Im Folgenden lernen Sie die grundlegenden Schritte, um mit Python Web Scraping zum Herunterladen von Bildern zu verwenden. Zuerst müssen Sie Beautiful Soup installieren, indem Sie pip install bs4 in der Kommandozeile eingeben. Geben Sie pip install requests ein, um requests zu installieren.
Danach folgen Sie den Schritten hier:
- Importieren Sie das Modul
- Erstellen Sie eine Instanz von requests und übergeben Sie diese an die URL
- Übergeben Sie die Requests an eine Beautifulsoup Funktion
- Verwenden Sie das Tag ‘img’, um alle Tags (‘src’) zu finden.
Für Entwickler: Ein einfaches Skript mit BeautifulSoup und Requests.
Mit diesem Artikel wird Ihre Arbeit um einiges vereinfacht werden. Dabei spielt es keine Rolle, ob Sie kein Code-Backer oder ein erfahrener Entwickler sind.
So funktioniert es:
Download-Funktion: download_image() nimmt die Bild-URL und speichert sie im angegebenen Ordner.
Bilder scrapen: scrape_images() ruft den Seiteninhalt per Anfrage ab und extrahiert anschließend alle <img> -Tags mit BeautifulSoup. Es sammelt Bild-URLs und lädt sie herunter.
Umgang mit relativen URLs: Wenn eine Bild-URL relativ ist (z. B. /images/pic.jpg ), wird sie vor dem Herunterladen in eine vollständige URL umgewandelt.
Rechtliche Hinweise: Legal und ethisch Bilder scrapen
Viele Bilder sind urheberrechtlich geschützt. Scrapen Sie nur mit Erlaubnis, für privaten Gebrauch oder unter Fair-Use-Regeln. Vermeiden Sie Server-Überlastung (z. B. Delays in Python einbauen). Quellen immer angeben. Mehr zu Web Scraping Legalität: EU-Datenschutz-Tipps.
Zusammenfassung
Sie kennen jetzt einfache Methoden, um Bilder von Webseiten zu extrahieren, mit und ohne Programmierkenntnisse.
Wenn Sie viele Bilder auf einmal oder regelmäßig extrahieren möchten, ist Octoparse eine gute Wahl. Es ist einer der besten Bild-Scraper für geplantes und umfangreiches Scraping.
👍👍 14 Tage Octoparse kostenlos testen – oder Fragen? Schreiben Sie an support@octoparse.com.
Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Häufige Fragen beim Scraping von Bildern
1. Kann ich Metadaten aus Bildern extrahieren?
Ja, Bild-Scraping-Tools können neben den Bildern selbst häufig auch Metadaten wie Alternativtext, Dateinamen, Bildabmessungen (Größe) und URLs extrahieren.
Diese Metadaten finden sich im HTML-Code einer Webseite, meist in zugehörigen Tags oder Attributen. Viele Scraping-Tools und Bibliotheken, wie Octoparse oder Beautiful Soup in Python, können so programmiert werden, dass sie diese Daten erfassen und so umfassende Datensätze erstellen.
2. Wie kann ich Text aus einem hochgeladenen Bild extrahieren?
Ich biete Ihnen ein einfaches Tool zum Extrahieren von Text aus einem Bild: Online-OCR. Fügen Sie Ihr Foto oder Ihre PDF-Datei hinzu, wählen Sie die Sprache und das Ausgabeformat aus und klicken Sie auf „Konvertieren“. In wenigen Sekunden erscheint der Text auf dem Bildschirm und Sie können ihn einfach kopieren oder herunterladen, ohne Installation oder Registrierung.
3. Wie extrahiere ich alle Fotos von einer Social-Media-Seite oder einem Social-Media-Profil?
Octoparse bietet zahlreiche vorgefertigte Vorlagen für verschiedene soziale Netzwerke und erleichtert so den Massenabruf von Fotos von verschiedenen Plattformen. Der Vorgang kann automatisiert werden, um mehrere Seiten zu laden und alle Bilder auf Ihren Computer herunterzuladen.
👉 Dieser Artikel ist ein Originalinhalt von Octoparse.



