Sie kennen das. Sie haben den Scraper endlich zum Laufen gebracht, Tausende von Datensätzen aus dem ganzen Web gezogen, die Exportdatei geöffnet und … es ist ein einziges Chaos.
Bewertungstexte sind mit HTML-Tags verheddert. Datumsangaben erscheinen in drei verschiedenen Formaten – manchmal sogar in vier. Die Hälfte der Einträge sind Duplikate. Spam mischt sich unter echtes Kundenfeedback. Und irgendwie enthält eine Spalte, die eigentlich Preise enthalten sollte, in jeder zweiten Zeile das Wort „null“.
Das ist der Teil der Datenbereinigung, vor dem Sie niemand warnt, wenn man Ihnen „datengesteuerte Entscheidungen“ verkaufen will. Das Scraping ist der einfache Teil. Die Datenbereinigung – sie konsistent, genau und tatsächlich nutzbar zu machen – ist der Punkt, an dem die eigentliche Arbeit beginnt.
Und das ist kein kleines Problem. Laut der Umfrage „State of Data Science 2020“ von Anaconda unter mehr als 2.300 Datenexperten verbringen die Befragten rund 45 % ihrer Zeit mit dem Laden und Bereinigen von Daten – was es zum zeitaufwändigsten Teil ihrer Arbeit macht. Nicht die Analyse. Nicht die Erkenntnisse. Sondern nur, die Daten in einen Zustand zu bringen, in dem eine Analyse überhaupt möglich ist.
Wenn Sie Daten bisher von Hand bereinigt haben – oder schlimmer noch, Entwickler beauftragt haben, für jedes Projekt einmalige Skripte zu schreiben – wissen Sie bereits, dass dies nicht nachhaltig ist. Die Frage ist: Was ist die Alternative?
Darum geht es in diesem Artikel. Wir werden aufschlüsseln, was Datenbereinigung tatsächlich beinhaltet, warum herkömmliche Datenbereinigungstools bei Web-Scraping-Daten an ihre Grenzen stoßen und wie Octoparse KI-Intelligenz mit konfigurierbaren Regeln kombiniert, um den unordentlichsten Teil jedes Datenprojekts zu bewältigen – ohne eine einzige Zeile Code zu schreiben.
Was ist Datenbereinigung – und warum verschlingt sie den größten Teil Ihrer Projektzeit?
Lassen Sie uns konkret werden, denn der Begriff „Datenbereinigung“ wird oft verwendet, ohne dass die Leute erklären, was er in der Praxis tatsächlich bedeutet.
Datenbereinigung (auch Datensäuberung oder Data Scrubbing genannt) ist der Prozess des Erkennens und Behebens von Fehlern, Inkonsistenzen und Qualitätsproblemen in einem Datensatz, damit er zuverlässig genug für Analysen oder Entscheidungen ist.
Das klingt einfach. Ist es aber nicht.
Wenn Sie mit Web-Scraping-Daten arbeiten – die von E-Commerce-Websites, Social-Media-Plattformen, Verzeichnissen oder Content-Plattformen stammen – umfasst die Bereinigung typischerweise fünf verschiedene Herausforderungen:
Standardisierung von Formaten. Dieselbe Information sieht je nach Quelle völlig anders aus. Ein Datum kann auf einer Website als „23.04.2023“ erscheinen, auf einer anderen als „2023-04-23“ und auf einer dritten als „23. April 2023“. Ein Preis könnte „29,99 €“, „29.99 USD“ oder „$29.99“ lauten. Ohne Standardisierung sind Ihre Daten unmöglich zu vergleichen oder zu aggregieren.
Entfernen von Störfaktoren (Noise). Rohe Scraping-Daten sind oft in HTML-Tags verpackt, mit Sonderzeichen durchsetzt oder mit Leerzeichen und Formatierungsartefakten überladen. Eine Produktbewertung, die „Tolles Produkt“ lauten sollte, sieht in Ihrem Export tatsächlich so aus: <p class="review-text"><b>Tolles Produkt!!!</b></p>. Diese Störfaktoren müssen entfernt werden.
Entfernen von Duplikaten. Wenn Sie mehrere Seiten – oder dieselbe Seite im Laufe der Zeit – scrapen, schleichen sich überall Duplikate ein. Manchmal sind es exakte Kopien. Häufiger sind es Beinahe-Duplikate mit feinen Unterschieden (ein nachgestelltes Leerzeichen, ein leicht abweichender Zeitstempel), die mit einfacher Deduplizierung schwer zu erkennen sind.
Herausfiltern von Datenmüll. Nicht jeder gescrapte Datensatz ist es wert, behalten zu werden. Spam-Kommentare, von Bots generierte Bewertungen, als Inhalt getarnte Anzeigen, Testeinträge – all das verschmutzt Ihren Datensatz. Das Identifizieren und Entfernen erfordert mehr als nur eine einfache Stichwortsuche.
Umgang mit fehlenden Werten. Reale Daten haben Lücken. Bei einem Produktangebot fehlt möglicherweise der Preis. Eine Bewertung hat vielleicht kein Datum. Die Entscheidung, wie mit diesen Lücken umgegangen werden soll – sie ausfüllen, markieren oder den gesamten Datensatz entfernen – ist eine Ermessensentscheidung, die von Ihrem Anwendungsfall abhängt.
Stellen Sie sich die Datenbereinigung wie die Raffination von Rohöl vor. Sie haben es aus dem Boden gepumpt (Scraping), aber Sie können kein Rohöl in Ihr Auto füllen. Es muss verarbeitet, gefiltert und raffiniert werden, bevor es zu etwas Nützlichem wird. Die Datenbereinigung ist dieser Raffinationsschritt.
Fazit: Wenn Sie die Datenbereinigung überspringen oder schlecht durchführen, ist jede Analyse, die auf diesen Daten aufbaut, unzuverlässig. Sie ist das Fundament. Wenn Sie es falsch machen, wackelt alles, was darauf aufbaut. Laut Gartners Forschung zu Datenqualitätslösungen aus dem Jahr 2020 kostet schlechte Datenqualität Unternehmen durchschnittlich 12,9 Millionen US-Dollar pro Jahr. Und Thomas C. Redman schätzt im MIT Sloan Management Review, dass schlechte Daten die meisten Unternehmen 15 % bis 25 % ihres Umsatzes kosten.
Warum die meisten Datenbereinigungstools nicht dafür gemacht wurden
Hier wird es frustrierend. Es gibt keinen Mangel an Datenbereinigungstools – von den integrierten Funktionen von Excel bis hin zu dedizierten ETL-Plattformen wie Talend oder Alteryx. Warum fühlt sich die Bereinigung von gescrapten Web-Daten also immer noch so mühsam an?
Weil die meisten Datenbereinigungstools für strukturierte Daten entwickelt wurden, die bereits in Datenbanken leben. Sie gehen davon aus, dass Ihre Daten in vorhersagbaren Spalten mit meist vorhersagbaren Formaten ankommen. Web-Scraping-Daten brechen jede dieser Annahmen.
Das Problem des Format-Chaos. Wenn Sie gleichzeitig Daten von Amazon, eBay, Twitter und YouTube abrufen, haben Sie es mit völlig unterschiedlichen Datenstrukturen, Datumsformaten, Kodierungsstandards und Feldlayouts zu tun. Herkömmliche Tools erwarten, dass Sie für jede Quelle einzeln Transformationsregeln schreiben – und diese jedes Mal neu schreiben, wenn eine Website ihr HTML aktualisiert.
Das Skalierungsproblem. Das Bereinigen einiger hundert Zeilen in Excel ist machbar. Das Bereinigen von 500.000 Datensätzen von sechs verschiedenen Plattformen? Excel stürzt ab. Traditionelle Skripting-Ansätze (Python Pandas, SQL-Transformationen) funktionieren, erfordern aber einen Entwickler, Testzeit und Wartung bei jeder Änderung der Datenstruktur.
Das Intelligenzproblem. Regelbasierte Bereinigung ist leistungsstark, aber starr. Ein RegEx-Muster, das HTML-Tags entfernt, erfasst keine Spam-Bewertungen. Eine Deduplizierungsregel, die exakte Zeichenketten abgleicht, erfasst keine Beinahe-Duplikate. Am Ende benötigen Sie Schichten von Regeln, jede einzelne von Hand erstellt – und sie übersehen immer noch Randfälle, die ein Mensch sofort erkennen würde.
Das ist die Lücke. Web-Scraping-Daten benötigen einen Bereinigungsansatz, der flexibel genug ist, um unvorhersehbare Formate zu bewältigen, intelligent genug, um Probleme zu erkennen, die Regeln allein übersehen würden, und zugänglich genug, dass Sie kein Daten-Engineering-Team benötigen, um ihn einzurichten.
Der hybride Ansatz: Wenn KI auf konfigurierbare Regeln trifft
Das Ingenieurteam von Octoparse hat jahrelang mit den unordentlichsten Web-Daten gearbeitet, die man sich vorstellen kann – plattformübergreifende E-Commerce-Exporte, mehrsprachige Social-Media-Feeds, regionenübergreifende Inhaltsdatensätze. Und sie kamen zu einer Schlussfolgerung, die im Nachhinein vielleicht offensichtlich klingt:
Weder KI allein noch Regeln allein lösen das Problem der Datenbereinigung. Man braucht beides, in Zusammenarbeit.
Stellen Sie es sich wie eine Küche mit zwei Köchen vor. Der KI-Koch hat brillante Instinkte – er kann ein Gericht probieren und sofort erkennen, was nicht stimmt, vorschlagen, welche Gewürze hinzugefügt werden sollten, und verdorbene Zutaten entdecken, die niemand sonst bemerkt hat. Der Regel-Koch ist präzise und konsistent – er befolgt Rezepte exakt, misst Zutaten auf den Gramm genau und liefert jedes Mal das gleiche Ergebnis.
Einzeln hat jeder Schwächen. Der KI-Koch improvisiert zu viel; der Regel-Koch kann sich nicht anpassen. Zusammen decken sie die blinden Flecken des anderen ab.
Das ist die Philosophie hinter der Datenbereinigungs-Engine von Octoparse. Heute treibt die KI-Schicht die intelligente RegEx-Generierung und die semantische Entitätsextraktion an – sie versteht Ihre Daten und schreibt die Bereinigungsmuster für Sie. Die regelbasierte Schicht übernimmt die Präzisionsarbeit – RegEx-Transformationen, Standardisierung von Datumsformaten, HTML-Transkodierung, Deduplizierung und Feldextraktion. Beide laufen in einer visuellen Oberfläche, in der Sie sie ohne Code schreiben konfigurieren, anpassen und kombinieren können.
Und Octoparse erweitert die KI-Schicht aktiv. Funktionen wie Sentiment-Analyse, Spam-Erkennung und erweiterte Anomalieerkennung sind bereits über die Datendienste von Octoparse verfügbar – und stehen auf der Roadmap für die direkte Produktintegration. Das Fundament ist gelegt; die Intelligenz wächst weiter.
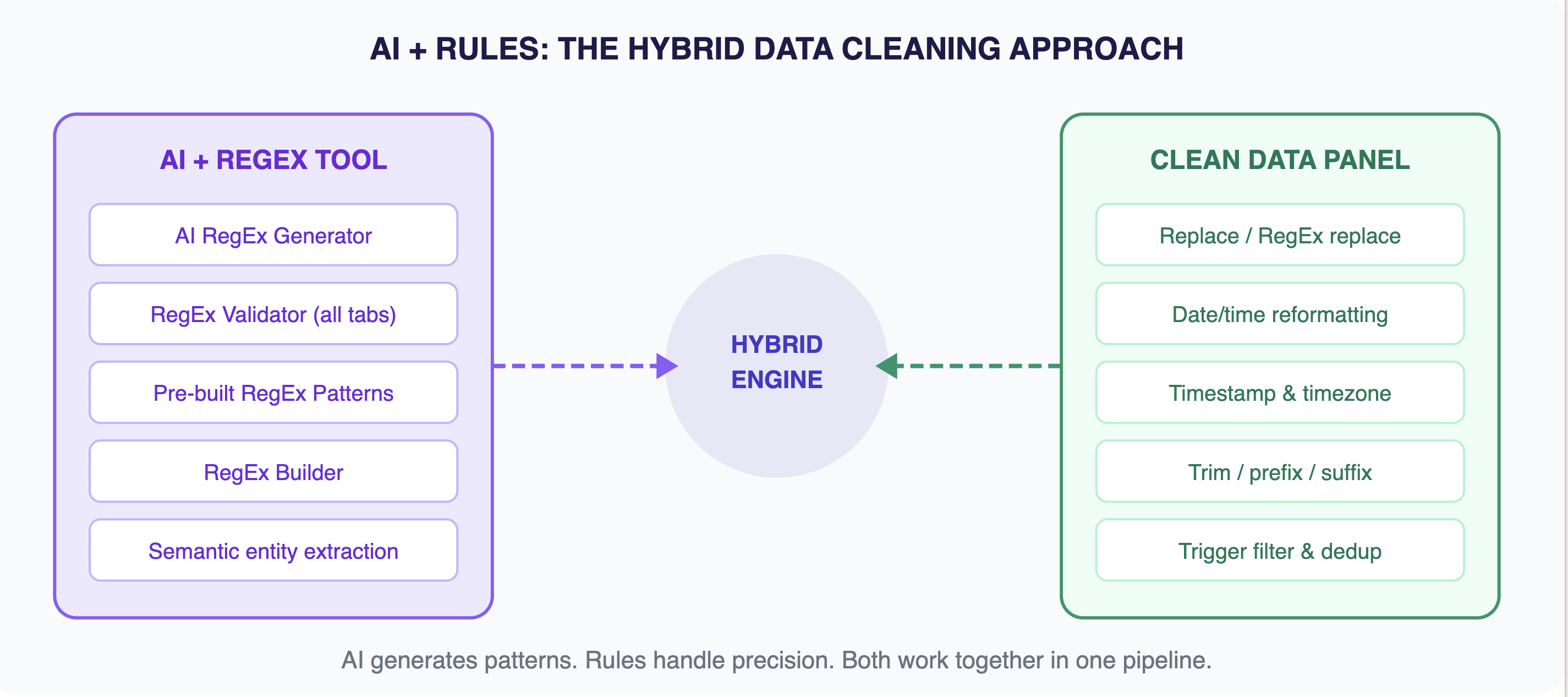
Die Hybrid-Engine: KI übernimmt die Intelligenz, Regeln sorgen für Präzision – beides gesteuert über eine visuelle No-Code-Oberfläche.
Drei Ebenen der Bereinigungsleistung – Null Zeilen Code
Lassen Sie uns konkret werden. So sieht das Datenbereinigungs-Toolkit von Octoparse in der Praxis aus – unterteilt in drei Ebenen, die verschiedene Arten von Bereinigungsherausforderungen bewältigen.
Intelligente Mustererkennung mit RegEx (Kein Doktortitel erforderlich)
Reguläre Ausdrücke – RegEx – sind die Arbeitspferde der textbasierten Datenbereinigung. Sie ermöglichen es Ihnen, Muster in Ihren Daten zu finden und zu transformieren: Produkt-IDs aus unordentlichen Zeichenketten extrahieren, Telefonnummern neu formatieren, Preiswerte herausziehen, Sonderzeichen entfernen.
Das Problem? Das Schreiben von RegEx war schon immer eine Hürde. Ein Muster wie (\d{2})/(\d{2})/(\d{4}) sieht aus wie ein fremder Code, wenn man noch nie damit gearbeitet hat.
Octoparse löst dies mit einem dreigleisigen Ansatz:
- KI-RegEx-Generator. Sie fügen bis zu 5 Textbeispiele in das Feld „Test String“ ein und markieren dann mit dem Cursor die erwarteten Übereinstimmungen – genau die Teile, die Sie extrahieren möchten. Klicken Sie auf „AI Generate“, und die KI analysiert Ihre markierten Auswahlen, um ein funktionierendes RegEx-Muster zu erstellen. Es sind keine Syntaxkenntnisse erforderlich. Zum Beispiel fügen Sie drei Produktzeichenketten wie „Produkt-ID: ABC12345“ ein, markieren in jeder nur den ID-Teil, und die KI generiert ein zuverlässiges Muster, das für Ihren gesamten Datensatz funktioniert. Überprüfen Sie es im Validator unten und klicken Sie dann auf „Save“, um es anzuwenden.
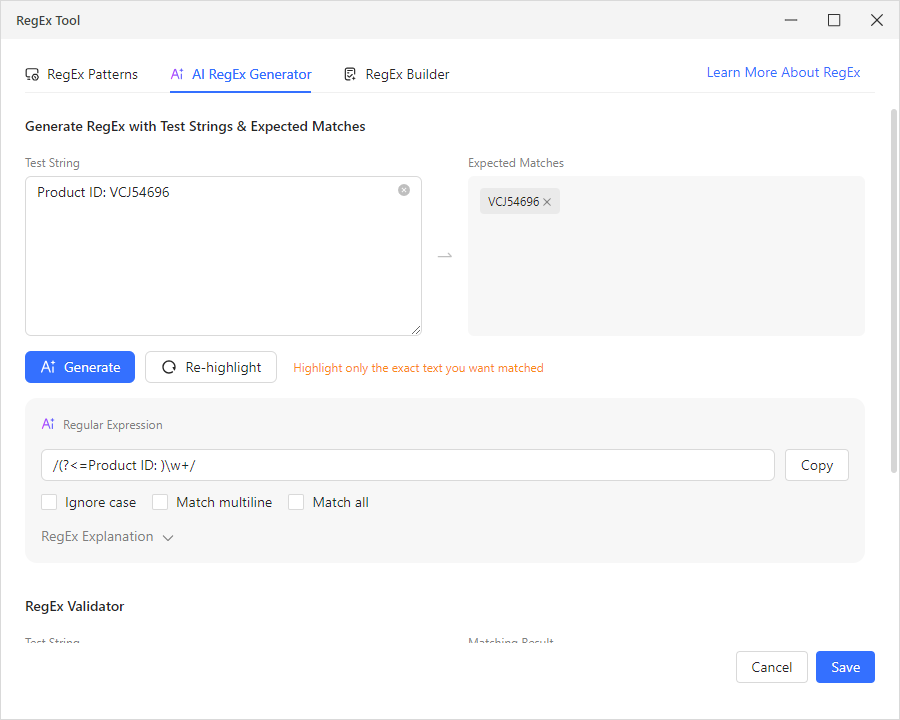
- RegEx-Muster. Octoparse wird mit einer Bibliothek vorgefertigter RegEx-Muster für die häufigsten Extraktionsaufgaben geliefert: Gängige E-Mail-Adresse, URL/Webadresse, US-Telefonnummer, US-Postleitzahl, Datum (JJJJ-MM-TT-Format), Ganzzahl, Fließkommazahl, nachgestellte Leerzeichen und Zeilenumbrüche, alphabetische Zeichen und mehr. Wählen Sie eines aus dem Dropdown-Menü aus und wenden Sie es mit einem Klick an.
- RegEx-Builder. Für gezielte Extraktionen können Sie mit dem Builder RegEx mithilfe von Abgleichsregeln generieren – „Match by Start“ (mit einer „Include Start“-Option), „Match with End“ (mit „Include End“) und „Matched by Content“ („Contains One“). Legen Sie Ihre Bedingungen fest, klicken Sie auf „Generate“, und es erstellt das RegEx für Sie – kein manuelles Schreiben der Syntax erforderlich.
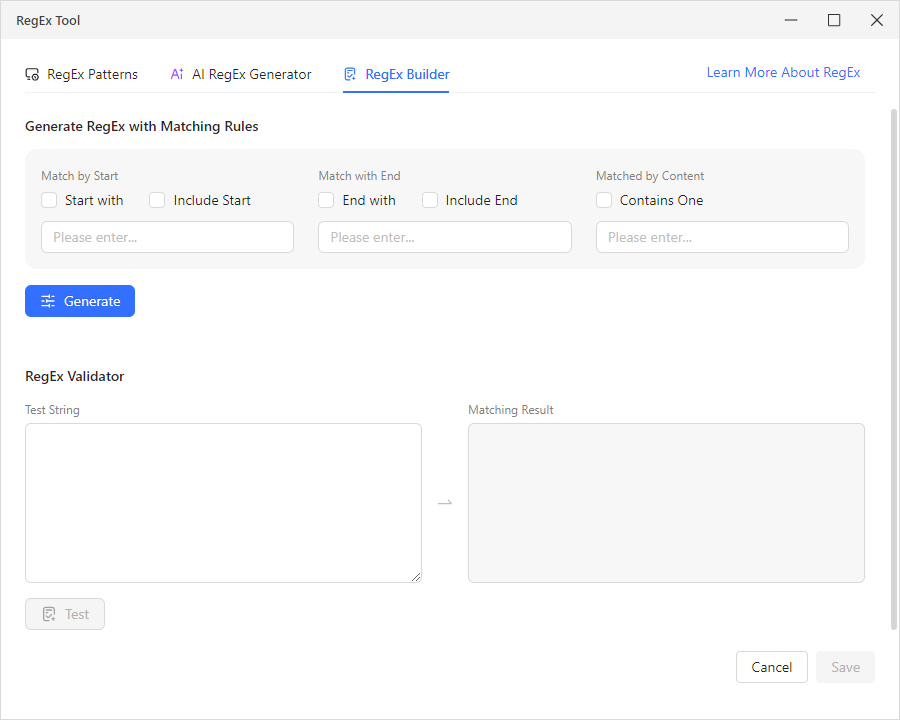
Alle drei Registerkarten enthalten einen integrierten RegEx-Validator mit den Feldern „Test String“ und „Matching Result“, sodass Sie jedes Muster überprüfen können, bevor Sie es auf Ihre Daten anwenden.
Praxisbeispiel: Sie haben Produktangebote gescrapt und das Preisfeld enthält unordentliche Zeichenketten wie „Preis: 29,99 $ USD“ gemischt mit „Ab 25,00 $“. Anstatt ein RegEx-Muster von Grund auf neu zu schreiben, öffnen Sie den KI-RegEx-Generator, fügen einige Beispielzeichenketten in das Feld „Test String“ ein, markieren mit dem Cursor nur den numerischen Preis in jeder Zeichenkette und klicken dann auf „AI Generate“. Die KI erstellt ein funktionierendes Muster, das saubere Preiswerte extrahiert. Überprüfen Sie es im RegEx-Validator, klicken Sie auf „Save“, und es wird auf Ihren gesamten Datensatz angewendet.
Datums- und Zeitstandardisierung (eines der schwierigsten Probleme in der Datenverarbeitung)
Wenn Sie jemals Datensätze aus verschiedenen Ländern zusammengeführt haben, kennen Sie den Albtraum. Ist „04/05/2023“ der 5. April oder der 4. Mai? Das hängt davon ab, ob die Quelle amerikanisch oder europäisch ist. Multiplizieren Sie das nun mit einem Dutzend Datenquellen über verschiedene Zeitzonen hinweg, und Sie haben ein ernsthaftes Konsistenzproblem.
Octoparse löst dies mit drei speziellen Bereinigungsoptionen im „Clean Data“-Panel:
- Extrahierte Datums-/Zeitangaben neu formatieren. Das System erkennt eingehende Datumsformate – MM/TT/JJJJ, TT/MM/JJJJ, JJJJ-MM-TT, „23. Apr. 2023“ – und konvertiert sie alle in Ihr gewähltes Standardformat. Sie konfigurieren es einmal; es wird auf Ihren gesamten Datensatz angewendet.
- Zeitzonenumrechnung. Wenn Ihre Daten aus Quellen in verschiedenen Zeitzonen stammen (z. B. Amazon US vs. Amazon UK), normalisiert diese Option Zeitstempel auf eine einzige Zeitzone, damit Ihre zeitbasierten Vergleiche tatsächlich Sinn ergeben.
- Zeitstempelumrechnung. Rohe Zeitstempel wie „1682294400“ werden zu menschenlesbaren Daten, was Ihre Daten ohne manuelle Berechnung sofort lesbar macht.
KI-gestützte intelligente Bereinigung
Über die Mustererkennung und Formatkonvertierung hinaus fügt die KI-Schicht von Octoparse eine Verständnisebene hinzu, die reine Regeln nicht erreichen können.
Semantische Entitätsextraktion (jetzt verfügbar). Hier glänzt die KI im heutigen Octoparse-Produkt wirklich. Sie zeigen und klicken auf den Inhalt, den Sie aus unstrukturiertem Text extrahieren möchten – Produktnamen, die in Bewertungstexten vergraben sind, Firmennennungen in sozialen Beiträgen, Preispunkte, die in Kommentarthreads eingebettet sind – und die KI versteht die semantische Bedeutung dessen, was Sie auswählen. Sie generiert dann automatisch RegEx-Muster, die diese Entitäten in Ihrem gesamten Datensatz erfassen und sie in saubere, separate Felder organisieren. Es ist nicht nur Mustererkennung – es ist die KI, die versteht, was Sie suchen, und die Extraktionslogik für Sie erstellt.
Sentiment-Analyse, Spam-Erkennung und intelligente Regelvorschläge (über Datendienste, mit Produktintegration auf der Roadmap). Für Teams, die eine tiefere KI-Bereinigung benötigen – wie das automatische Taggen von Bewertungsstimmungen als positiv, negativ oder neutral, das Markieren von bot-generiertem Spam oder das Erhalten von KI-empfohlenen Bereinigungsregeln basierend auf Anomalieerkennung – sind diese Funktionen heute über die professionellen Datendienste von Octoparse verfügbar. Das Ingenieurteam arbeitet aktiv daran, diese in das Kernprodukt zu integrieren, sodass sie in zukünftigen Versionen zu Self-Service-Funktionen werden. Die Architektur ist bereits dafür ausgelegt; es ist eine Frage des Wann, nicht des Ob.
In der Praxis: Bereinigung von E-Commerce-Bewertungsdaten
Lassen Sie uns ein reales Szenario durchgehen. Sie haben 50.000 Produktbewertungen von mehreren E-Commerce-Plattformen für ein Wettbewerbsanalyseprojekt gescrapt. So sehen die Rohdaten aus – und was passiert, wenn die Bereinigungs-Engine von Octoparse sie verarbeitet.

Vorher und nachher: Ungeordnete Bewertungsdaten aus mehreren Quellen werden strukturiert, dedupliziert und analysebereit.
So würden Sie dies in Octoparse Schritt für Schritt einrichten:
- Schritt 1: Öffnen Sie die Bereinigungstools für Ihr Datenfeld. Klicken Sie im benutzerdefinierten Task-Editor von Octoparse mit der rechten Maustaste auf das Datenfeld, das Sie bereinigen möchten. Im Kontextmenü sehen Sie die Option „Clean Data“ – klicken Sie darauf, um das Bereinigungsfenster zu öffnen.
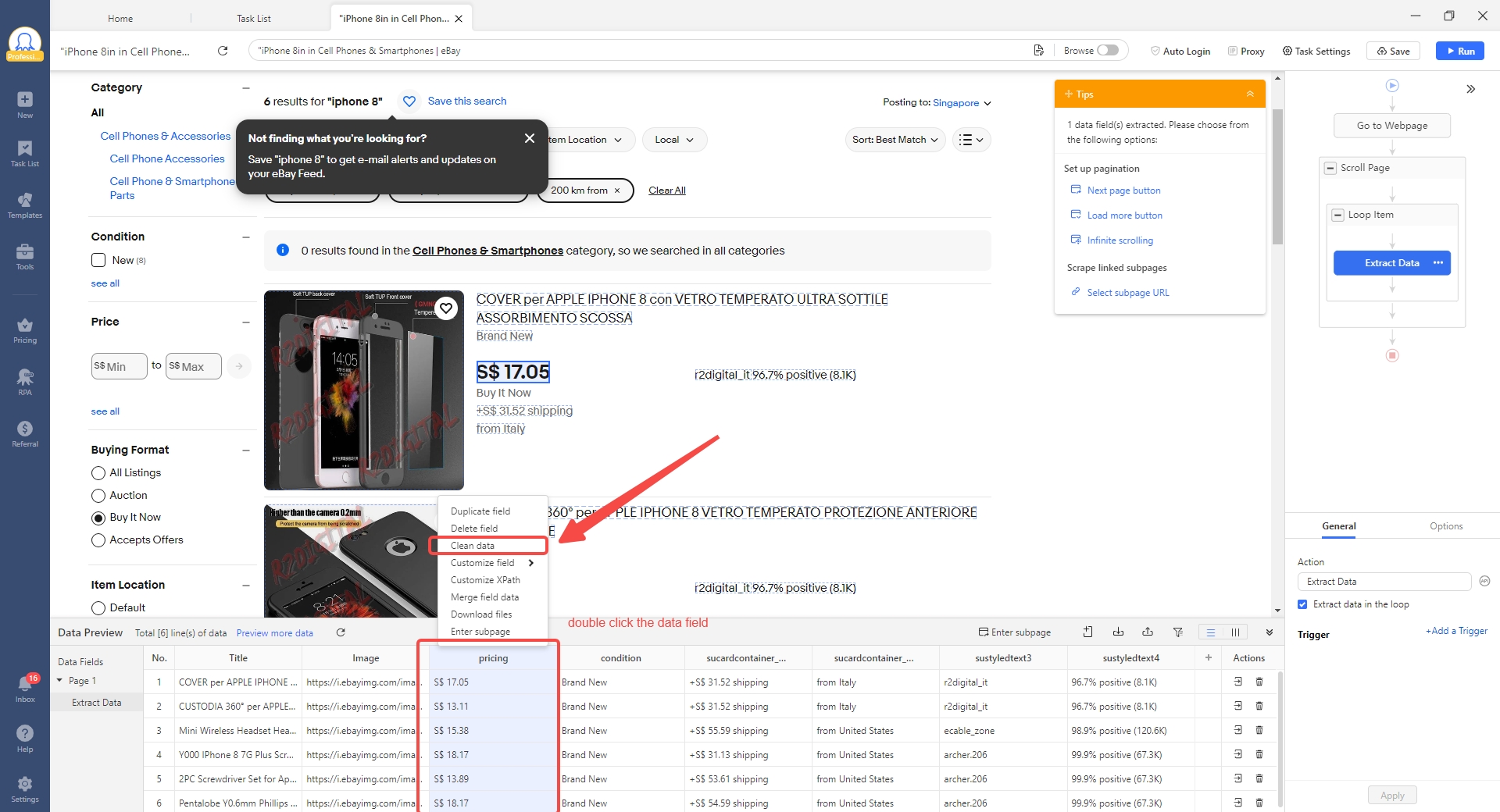
- Schritt 2: Standardisieren Sie Datumsformate. Fügen Sie im Feld „review_date“ einen Bereinigungsschritt hinzu und wählen Sie „Reformat extracted date/time“. Wählen Sie Ihr Zielformat (JJJJ-MM-TT). Octoparse erkennt automatisch die eingehenden Formate und konvertiert sie alle.
- Schritt 3: Verwenden Sie KI-RegEx, um Entitäten zu extrahieren. Müssen Sie Produkt-IDs, Markennamen oder spezifische Datenpunkte aus unordentlichem Bewertungstext extrahieren? Öffnen Sie das RegEx-Tool (im Bereich „Tools“), wechseln Sie zur Registerkarte „AI RegEx Generator“, fügen Sie bis zu 5 Beispielzeichenketten ein, markieren Sie die Zielbereiche und klicken Sie auf „AI Generate“. Überprüfen Sie das Ergebnis im RegEx-Validator und speichern Sie es – es wird auf Ihren gesamten Datensatz angewendet.
- Schritt 4: Filtern Sie unerwünschte Daten. Verwenden Sie die Trigger-Funktion, um Bedingungen festzulegen, die Zeilen herausfiltern, die Sie nicht benötigen – zum Beispiel Bewertungen ausschließen, bei denen das Preisfeld einen bestimmten Schwellenwert überschreitet, oder Zeilen löschen, bei denen ein erforderliches Feld leer ist.
- Schritt 5: Deduplizieren. Für die Deduplizierung eines einzelnen Datenfeldes verwenden Sie die Funktion „Remove Duplicates“ im Datenvorschau-Modul, um doppelte Werte herauszufiltern. Für die Deduplizierung ganzer Datensätze über Ihren gesamten Datensatz hinweg enthält die Exportfunktion von Octoparse eine integrierte Deduplizierungsoption, die doppelte Zeilen beim Export automatisch entfernt.
- Schritt 6: Exportieren Sie saubere Daten. Führen Sie die Aufgabe in der Cloud aus. Exportieren Sie nach Excel, CSV, in Ihre Datenbank oder über eine API. Die 50.000 unordentlichen Datensätze werden als sauberer, strukturierter und analysebereiter Datensatz ausgegeben.
Gesamte Einrichtungszeit? Etwa 15 Minuten.
Vergleichen Sie das mit dem traditionellen Ansatz: Ein Python-Entwickler schreibt ein benutzerdefiniertes Skript mit Pandas, BeautifulSoup, dateutil und einer Sentiment-Analyse-Bibliothek. Das Testen dauert einen Tag. Randfälle dauern einen weiteren Tag. Wenn das nächste Projekt andere Datenquellen hat, fangen sie von vorne an. Das ist der Unterschied zwischen einem speziell entwickelten Datenbereinigungstool und einem allgemeinen Programmieransatz.
Wo dies sonst noch wichtig ist
Der hybride Ansatz aus KI und Regeln funktioniert für jedes Szenario der Web-Datenbereinigung. Hier sind einige, die Octoparse-Benutzer regelmäßig bewältigen:
Preisüberwachung über Marktplätze hinweg. Gescrapte Preise kommen in allen erdenklichen Formaten – „29,99 $“, „29,99 €“, „24,99 £“, „Ab 25 $“. RegEx entfernt die Störfaktoren und extrahiert die numerischen Werte, während Filter Anomalien wie offensichtlich falsche Preise (z. B. ein Laptop-Angebot für 0,01 $) erkennen.
Social-Media-Markenverfolgung. Beiträge von Twitter, Reddit und Foren kommen mit plattformspezifischer Formatierung, Emojis, Hashtags und unterschiedlichem Rauschen. Regelbasierte Bereinigung entfernt Formatierungsartefakte. KI-gestütztes RegEx extrahiert Entitäten wie Markennamen und Produktnennungen, während RegEx-Muster und Filter die Rauschentfernung übernehmen. Für tiefere Analysen wie Sentiment-Tagging kann das Datendienst-Team von Octoparse benutzerdefinierte Pipelines einrichten.
Lead-Generierung aus Verzeichnissen. Geschäftseinträge, die aus den Gelben Seiten, LinkedIn und Branchenverzeichnissen gescrapt wurden, enthalten inkonsistente Formatierungen für Telefonnummern, Adressen und Firmennamen. RegEx standardisiert die Formate, und die Funktion „Remove Duplicates“ filtert wiederholte Einträge heraus, sodass Ihre endgültige Liste sauber und bereit für die Kontaktaufnahme ist.
Inhaltsrecherche und -aggregation. Videometadaten von YouTube, Artikel von Nachrichtenseiten und Blogbeiträge aus dem gesamten Web benötigen alle eine Datumsstandardisierung und Deduplizierung, bevor sie für die Forschung nützlich sind. Die Hybrid-Engine erledigt dies in einer einzigen Pipeline.
Was dies von anderen Datenbereinigungstools unterscheidet
| Manuell / Excel | Python-Skripte | Traditionelle ETL-Tools | Octoparse Hybrid-Engine | |
| Lernkurve | Niedrig | Hoch (Programmierung) | Mittel-Hoch | Niedrig (visuell, No-Code) |
| Umgang mit Web-Daten | Schlecht | Gut (wenn maßgeschneidert) | Mäßig | Speziell für Web-Daten entwickelt |
| KI-Fähigkeiten | Keine | DIY (Bibliotheken hinzufügen) | Begrenzt | KI-RegEx-Generierung + semantische Extraktion (Sentiment & NER über Datendienste) |
| RegEx-Unterstützung | Grundlegend | Vollständig (manuell) | Variiert | KI-generiert + Bibliothek + visueller Builder |
| Wiederverwendbarkeit | Keine | Copy-Paste-Skripte | Vorlagenbasiert | Modulare, teilbare Bereinigungsschritte |
| Skalierung | ~10K Zeilen max. | Unbegrenzt (mit Infrastruktur) | Abhängig von der Lizenz | Cloud-Ausführung, 500K+ Datensätze |
| Einrichtungszeit | Minuten (aber manuell) | Tage bis Wochen | Wochen | Minuten bis Stunden |
Warum dies für Ihr nächstes Projekt wichtig ist
Wenn Sie diesen Artikel lesen, sind Sie wahrscheinlich kein Neuling im Bereich Daten. Sie kennen den Wert sauberer, strukturierter Informationen. Die Frage ist nicht, ob Datenbereinigung wichtig ist – sondern ob Sie Ihre Zeit dafür klug einsetzen.
Jede Stunde, die Sie mit der manuellen Datenbereinigung verbringen, ist eine Stunde, die Sie nicht für Analysen, Strategien oder Entscheidungen aufwenden. Jede Woche, die ein Entwickler mit dem Schreiben einmaliger Bereinigungsskripte verbringt, ist eine Woche, in der er keine Features oder Produkte entwickelt.
Die hybride Bereinigungs-Engine von Octoparse beseitigt nicht die Notwendigkeit der Datenbereinigung – diese Notwendigkeit wird nicht verschwinden. Was sie beseitigt, ist die manuelle Plackerei. Die KI übernimmt die Intelligenz. Die Regeln übernehmen die Präzision. Die visuelle Oberfläche sorgt für die Zugänglichkeit. Und die Cloud kümmert sich um die Skalierung.
Das Ergebnis: Die Datenbereinigung wird vom größten Zeitfresser in Ihrem Daten-Workflow zu einem der schnellsten Schritte. Sie konfigurieren es einmal, verwenden es projektübergreifend wieder und lassen das System die schwere Arbeit erledigen.
Erste Schritte mit der Datenbereinigung von Octoparse
Bereit, es auszuprobieren? Hier ist der schnelle Weg:
- Erstellen Sie ein kostenloses Konto auf octoparse.com. Keine Kreditkarte erforderlich. Der kostenlose Plan enthält Datenbereinigungsfunktionen.
- Richten Sie eine Scraping-Aufgabe ein. Verwenden Sie den Point-and-Click-Builder in einer benutzerdefinierten Aufgabe, um mit der Extraktion von Daten von Ihrer Zielwebsite zu beginnen.
- Öffnen Sie die Bereinigungstools. Klicken Sie mit der rechten Maustaste auf ein extrahiertes Datenfeld und wählen Sie „Clean Data“. Sie sehen Optionen wie „Replace“, „Replace with Regular Expression“, „Match with Regular Expression“, „Trim spaces“, „Add a prefix/suffix“, „Reformat extracted date/time“, „Timestamp conversion“, „Timezone conversion“ und „HTML transcoding“. Für fortgeschrittene RegEx-Arbeiten bietet das RegEx-Tool im Bereich „Tools“ einen KI-RegEx-Generator, vorgefertigte RegEx-Muster und einen RegEx-Builder.
- Ausführen und exportieren. Führen Sie die Aufgabe in der Cloud aus, planen Sie sie für die automatische Ausführung und exportieren Sie saubere Daten in Ihr bevorzugtes Format – Excel, CSV, Datenbank oder API. Aktivieren Sie die Deduplizierung beim Export für eine automatisch saubere Ausgabe.
Das ist alles. Vier Schritte von rohen Web-Daten zu sauberer, strukturierter Ausgabe.
Saubere Daten, klare Entscheidungen
Hier ist die Sache mit der Datenbereinigung: Niemand ist davon begeistert. Es ist der Teil des Daten-Workflows, den jeder überspringen möchte, aber niemand sich leisten kann zu ignorieren. Es ist das unsexy Fundament, das alles andere – die Dashboards, die Erkenntnisse, die Wettbewerbsintelligenz – tatsächlich vertrauenswürdig macht.
Octoparse macht die Datenbereinigung nicht aufregend. Aber es macht sie schnell, genau und für jeden zugänglich – unabhängig davon, ob Sie jemals eine Zeile Code geschrieben haben. Und in einer Welt, in der die Unternehmen gewinnen, die am schnellsten mit Daten umgehen, ist das der entscheidende Vorteil.

Scrapen Sie Daten einfach mit Auto-Detecting-Funktionen, keine Programmierkenntnisse erforderlich.
Voreingestellte Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Werden Sie nie wieder blockiert, dank IP-Proxies und fortschrittlicher API.
Cloud-Service zur Planung des Daten-Scrapings zu jeder gewünschten Zeit.
FAQs zur Datenbereinigung
Was ist Datenbereinigung und warum ist sie wichtig?
Datenbereinigung ist der Prozess des Identifizierens und Behebens von Fehlern, Inkonsistenzen, Duplikaten und Qualitätsproblemen in einem Datensatz. Sie ist wichtig, weil jede Analyse, jeder Bericht oder jede Entscheidung, die auf unsauberen Daten basiert, unzuverlässig ist. Speziell für Web-Scraping-Daten ist die Bereinigung unerlässlich, da Websites Informationen inkonsistent formatieren – daher sind rohe Exporte selten ohne Verarbeitung nutzbar.
Was sind die häufigsten Datenbereinigungsaufgaben für gescrapte Daten?
Die fünf häufigsten Aufgaben sind: Standardisierung von Datums- und Zahlenformaten über verschiedene Quellen hinweg, Extraktion spezifischer Werte aus unordentlichen Textfeldern, Entfernen doppelter Datensätze, Herausfiltern von Datenmüll und Entfernen unerwünschter Leerzeichen oder Zeichen. Octoparse bewältigt dies durch eine Kombination aus „Clean Data“-Optionen (Ersetzen, Leerzeichen entfernen, Datums-/Zeit-Neuformatierung), dem RegEx-Tool mit KI-gestützter Mustergenerierung, „Remove Duplicates“ in der Datenvorschau, Deduplizierung beim Export und konfigurierbaren Trigger-Filtern.
Muss ich RegEx kennen, um die Datenbereinigungstools von Octoparse zu verwenden?
Nein. Das RegEx-Tool von Octoparse hat drei Registerkarten für unterschiedliche Kenntnisstände. Der KI-RegEx-Generator ermöglicht es Ihnen, bis zu 5 Beispielzeichenketten einzufügen, die zu suchenden Teile zu markieren und auf „AI Generate“ zu klicken – es schreibt das RegEx für Sie. Die Registerkarte „RegEx Patterns“ bietet eine Bibliothek vorgefertigter Muster für gängige Aufgaben (E-Mails, Telefonnummern, URLs, Daten, Ganzzahlen). Und der RegEx-Builder ermöglicht es Ihnen, Muster mithilfe von Abgleichsregeln wie „Match by Start“, „Match with End“ und „Matched by Content“ zu erstellen. Jede Registerkarte enthält einen RegEx-Validator, damit Sie vor der Anwendung testen können. Power-User können auch benutzerdefinierte RegEx schreiben, aber das ist völlig optional.
Wie unterscheidet sich die KI-Bereinigung von Octoparse von der Verwendung von ChatGPT oder einem anderen KI-Tool?
Allzweck-KI-Tools wie ChatGPT können Ihnen helfen, einen Bereinigungsansatz zu finden, aber sie können nicht 50.000 Datensätze in großen Mengen verarbeiten, sie integrieren sich nicht direkt in eine Scraping-Pipeline und sie bieten keine persistenten, wiederverwendbaren Bereinigungskonfigurationen. Der KI-RegEx-Generator von Octoparse ist speziell für die Datenbereinigung entwickelt – Sie füttern ihn mit Beispielen aus Ihren tatsächlichen Daten, und er generiert zuverlässige Muster, die im großen Maßstab über Ihren gesamten Datensatz laufen, direkt in Ihrem Extraktions-Workflow. Kein Kopieren und Einfügen zwischen verschiedenen Tools.
Kann ich Daten von mehreren Plattformen in derselben Pipeline bereinigen?
Absolut. Die Bereinigungstools von Octoparse arbeiten mit den extrahierten Daten, unabhängig von der Quelle. Wenn Sie Bewertungen von Amazon, eBay und Walmart abrufen, konfigurieren Sie Ihre Bereinigungsregeln einmal, und sie werden einheitlich auf alle Datensätze angewendet. Datumsformate werden standardisiert, unerwünschter Text wird entfernt, Duplikate werden erkannt – unabhängig davon, von welcher Plattform die Daten stammen.
Ist die Datenbereinigung im kostenlosen Plan enthalten?
Ja. Der kostenlose Plan ermöglicht es Ihnen, bis zu 10 Scraping-Aufgaben mit vollem Zugriff auf Datenbereinigungsfunktionen auszuführen, einschließlich RegEx-Tools, Formatkonvertierung und KI-gestützter Bereinigung. Der Standard-Plan (69 $/Monat bei jährlicher Abrechnung) und der Professional-Plan (249 $/Monat bei jährlicher Abrechnung) fügen Cloud-Ausführung, Zeitplanung, höhere Parallelität und priorisierten Support hinzu.
Kann Octoparse auch nicht-englische Daten bereinigen?
Ja. Die RegEx- und Formatkonvertierungstools sind sprachunabhängig, und der KI-RegEx-Generator funktioniert mit dem Zeichensatz jeder Sprache. Dies ist besonders nützlich für regionenübergreifende Projekte – zum Beispiel die Bereinigung von Produktbewertungen von Amazon US, Amazon UK und Amazon Frankreich in einer einzigen Pipeline. Die Tools verarbeiten unterschiedliche Zeichenkodierungen nativ.



