Sie haben wahrscheinlich schon tausendmal von maschinellem Lernen oder Machine Learning gehört, aber wissen Sie wirklich, was Maschinelles Lernen ist? In diesem Beitrsg sind insgesamt 8 wichtigste Begriffe vorgestellt, die direkt mit dem maschinellen Lernen zusammenhängen.
Begrifferklärung von Maschinelles Lernen
Maschinelles Lernen ist eine Methode der künstlichen Intelligenz, bei der Computerprogramme lernen, auf Basis von Daten Entscheidungen zu treffen oder Vorhersagen zu treffen, ohne dass sie explizit programmiert werden müssen.
Im Maschinellen Lernen werden Algorithmen verwendet, um Muster in Daten zu erkennen und darauf aufbauend Vorhersagen oder Entscheidungen zu treffen. Dazu werden große Datenmengen verwendet, die als Trainingsdaten bezeichnet werden. Die Algorithmen werden anhand dieser Daten trainiert, indem sie Muster und Zusammenhänge erkennen und die Daten analysieren. Anschließend können sie auf neue Daten angewendet werden, um Vorhersagen oder Entscheidungen zu treffen.
Es gibt verschiedene Arten von Maschinellem Lernen, wie zum Beispiel überwachtes Lernen, unüberwachtes Lernen und bestärkendes Lernen. Im überwachten Lernen werden die Algorithmen mit beschrifteten Daten trainiert, während im unüberwachten Lernen die Algorithmen selbstständig Muster und Zusammenhänge in den Daten erkennen müssen. Beim bestärkenden Lernen lernen die Algorithmen durch Feedback auf Basis von Belohnungen oder Bestrafungen.
Maschinelles Lernen findet in vielen Bereichen Anwendung, wie zum Beispiel in der Spracherkennung, Bilderkennung, medizinischen Diagnose, Betrugserkennung, Robotik und vielen anderen Bereichen. Es ist eine wichtige Technologie, die in Zukunft noch weiter an Bedeutung gewinnen wird.
Neun Unterbegriffe
1. Natural language processing
Natural Language Processing (NLP) ist ein Bereich der künstlichen Intelligenz (KI), der sich mit der Verarbeitung und Analyse natürlicher Sprache befasst. Das Ziel von NLP ist es, Computern die Fähigkeit zu geben, menschliche Sprache zu verstehen, zu analysieren, zu generieren und darauf zu reagieren.
NLP nutzt verschiedene Techniken und Algorithmen, um Sprachdaten zu verarbeiten, einschließlich maschinellen Lernens, Mustererkennung, Spracherkennung, Textklassifizierung, Sentimentanalyse und Übersetzung.
Ein wichtiger Teil von NLP ist die Textanalyse. Hierbei wird eine Menge an Textdaten analysiert, um bestimmte Informationen daraus zu extrahieren. Hierzu können verschiedene Techniken eingesetzt werden, wie zum Beispiel Named Entity Recognition (NER), die Entitäten wie Personen, Organisationen und Orte in Texten identifiziert.
NLP wird in vielen Anwendungsbereichen eingesetzt, darunter Chatbots, automatische Übersetzung, Sentimentanalyse von sozialen Medien, Informationsextraktion und Klassifizierung von Dokumenten, automatische Zusammenfassung von Texten und vieles mehr.
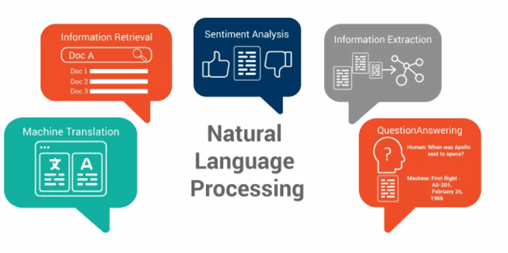
Es gibt viele bekannte Anwendungen von Natural Language Processing (NLP), hier sind einige Beispiele:
Chatbots
Chatbots sind virtuelle Assistenten, die durch NLP und maschinelles Lernen angetrieben werden. Sie sind in der Lage, natürliche Sprache zu verstehen und auf Anfragen zu reagieren, indem sie automatisierte Antworten bereitstellen.
Übersetzung
NLP kann verwendet werden, um automatische Übersetzungen von Texten in verschiedene Sprachen zu erstellen. Hierbei wird die natürliche Sprache analysiert und automatisch in eine andere Sprache übersetzt.
Extraktion von Informationen
Dies dient hauptsächlich dazu, einen langen Absatz in einem kurzen Text zusammenzufassen, ähnlich wie die Erstellung einer Zusammenfassung.
Sentimentanalyse
Die Sentimentanalyse ist eine NLP-Technik, die verwendet wird, um die Meinungen, Einstellungen und Emotionen in Texten zu identifizieren. Hierbei werden Algorithmen verwendet, um bestimmte Wörter, Phrasen oder Kontexte zu erkennen und zu bewerten, ob sie positiv, negativ oder neutral sind.
Informationsextraktion
NLP kann auch eingesetzt werden, um relevante Informationen aus Texten zu extrahieren. Hierbei können spezifische Daten wie Namen, Orte, Daten und Fakten aus einem Text herausgefiltert werden.
Textanalyse
NLP kann dazu verwendet werden, Texte automatisch zu klassifizieren oder zu kategorisieren. Hierbei wird der Inhalt eines Textes analysiert und auf der Grundlage von Schlüsselwörtern oder Themen in Kategorien eingeteilt.
Spracherkennung
NLP wird auch bei der Spracherkennung eingesetzt, um gesprochene Worte in Text umzuwandeln. Hierbei werden akustische Signale analysiert und in natürliche Sprache umgewandelt.
Automatische Zusammenfassung
NLP kann auch verwendet werden, um Texte automatisch zusammenzufassen. Hierbei werden Schlüsselsätze und relevante Informationen aus einem Text extrahiert, um eine kurze Zusammenfassung des Textes zu erstellen.
NLP ist ein schnell wachsender Bereich der künstlichen Intelligenz, der immer wichtiger wird, da immer mehr Daten in natürlicher Sprache vorliegen. Mit Fortschritten im maschinellen Lernen und in der Verarbeitung natürlicher Sprache wird die Technologie immer effektiver und genauer. Diese Anwendungen von NLP haben in vielen Bereichen wie Kundenservice, Sprachübersetzung, Medienanalyse, E-Commerce, medizinischer Diagnostik und vielen anderen Bereichen Anwendung gefunden.
2. Datenmenge
Daten spielen eine entscheidende Rolle im Bereich des maschinellen Lernens. Maschinelles Lernen basiert auf der Verwendung großer Datenmengen, um Muster und Zusammenhänge zu erkennen und Vorhersagen zu treffen. Im Allgemeinen können wir die Daten, die für das maschinelle Lernen verwendet werden, in drei Kategorien einteilen: Trainingsdaten, Validierungsdaten und Testdaten.
Trainingsdaten
Trainingsdaten sind die Daten, auf denen ein Modell trainiert wird. Dies bedeutet, dass ein Algorithmus auf Basis dieser Daten Muster und Zusammenhänge erkennt und lernt, wie er Vorhersagen treffen soll. Die Trainingsdaten müssen eine repräsentative Stichprobe der Gesamtpopulation sein, auf die das Modell angewendet wird, und sollten ausreichend groß sein, um genügend Variationen und Muster zu enthalten.
Validierungsdaten
Validierungsdaten werden verwendet, um die Leistung des Modells während des Trainings zu überwachen und es zu optimieren. Validierungsdaten werden verwendet, um den Algorithmus zu verbessern, indem er Parameter anpasst und Hyperparameter optimiert, um sicherzustellen, dass das Modell nicht nur auf die Trainingsdaten passt, sondern auch auf neue, unbekannte Daten.
Testdaten
Testdaten werden verwendet, um die Leistung des Modells zu bewerten, nachdem es trainiert und validiert wurde. Die Testdaten sollten eine repräsentative Stichprobe der Gesamtpopulation sein, auf die das Modell angewendet wird, aber sie sollten keine Daten enthalten, die in den Trainings- oder Validierungsdaten enthalten sind. Dies hilft, die Fähigkeit des Modells zu bewerten, auf neue, unbekannte Daten zu generalisieren.
Die Qualität der Daten ist von entscheidender Bedeutung für den Erfolg eines Modells im maschinellen Lernen. Es ist wichtig sicherzustellen, dass die Daten sauber, aktuell, ausreichend groß und repräsentativ für die Gesamtpopulation sind. Daten können auf verschiedene Weise beschafft werden, einschließlich Web Scraping, Datenbankabfragen und manueller Dateneingabe. Es ist jedoch wichtig, sicherzustellen, dass die Daten ethisch korrekt beschafft werden und keine personenbezogenen Daten enthalten, die die Privatsphäre der Nutzer verletzen könnten.
3. Überwachtes Lernen (Supervised learning)
Überwachtes Lernen ist eine Form des maschinellen Lernens, bei der ein Algorithmus mit Hilfe von beschrifteten Trainingsdaten trainiert wird. Das bedeutet, dass jeder Datenpunkt in den Trainingsdaten mit einem Label oder einer Klassenzuordnung versehen ist. Ziel des überwachten Lernens ist es, ein Modell zu erstellen, das in der Lage ist, auf neue, unbekannte Daten korrekte Vorhersagen oder Klassifizierungen zu treffen.
Beispiele für überwachtes Lernen sind Klassifizierungs- und Regressionsprobleme. In einem Klassifizierungsproblem soll ein Modell Datenpunkte in verschiedene Kategorien oder Klassen einteilen. Beispiele hierfür sind Spam-Filter, die E-Mails in Spam und Nicht-Spam kategorisieren, oder Gesichtserkennungssysteme, die Gesichter von Personen identifizieren.
In einem Regressionsproblem soll ein Modell eine Beziehung zwischen den Eingabedaten und einer kontinuierlichen Zielvariable herstellen. Beispiele hierfür sind Aktienkursvorhersagen oder die Schätzung der Energieeffizienz von Gebäuden auf Basis von Daten wie Größe, Standort und Baujahr.
Um ein überwachtes Lernmodell zu trainieren, müssen zuerst Trainingsdaten gesammelt und beschriftet werden. Dann wird das Modell mit diesen Daten trainiert, indem es Muster und Zusammenhänge in den Daten lernt. Anschließend kann das Modell auf neue, unbekannte Daten angewendet werden, um Vorhersagen oder Klassifizierungen zu treffen.
Die Leistung eines überwachten Lernmodells wird in der Regel anhand der Genauigkeit oder Fehlerrate gemessen. Es gibt verschiedene Algorithmen, die für das überwachte Lernen verwendet werden können, wie zum Beispiel k-Nearest Neighbors, Decision Trees, Random Forests, Support Vector Machines und Neural Networks. Die Wahl des geeigneten Algorithmus hängt von den spezifischen Anforderungen des Problems und den Eigenschaften der Daten ab.
4. Unüberwachtes Lernen (Unsupervised Learning)
Unüberwachtes Lernen ist eine Form des maschinellen Lernens, bei der ein Algorithmus auf der Grundlage von unbeaufsichtigten Datenmengen trainiert wird. Im Gegensatz zum überwachten Lernen werden die Daten beim unüberwachten Lernen nicht beschriftet und es gibt keine Zielvariablen, die das Modell lernen soll.
Das Ziel des unüberwachten Lernens besteht darin, Muster und Zusammenhänge in den Daten zu identifizieren, ohne dass eine Zielvariablen vorgegeben wird. Unüberwachtes Lernen kann helfen, verborgene Muster in großen Datenmengen zu entdecken und kann bei der Identifizierung von Clustern oder Gruppen von ähnlichen Datenpunkten helfen.
Beispiele für unüberwachtes Lernen sind Clusteranalyse und Dimensionsreduzierung. In einer Clusteranalyse werden ähnliche Datenpunkte in Gruppen oder Clustern zusammengefasst, ohne dass eine Vorstellung von den zugrunde liegenden Klassen oder Gruppen besteht. Dies kann beispielsweise bei der Segmentierung von Kunden auf der Grundlage ihrer Einkaufsgewohnheiten oder bei der Identifizierung von Mustern in biomedizinischen Daten hilfreich sein.
Die Dimensionsreduzierung bezieht sich auf das Verfahren, bei dem die Anzahl der Variablen in einem Datensatz reduziert wird, ohne dabei wesentliche Informationen zu verlieren. Dies kann bei der Analyse von Daten hilfreich sein, bei denen eine große Anzahl von Variablen vorliegt, die die Leistung des Modells beeinträchtigen können.
Die Leistung von unüberwachten Lernmodellen kann schwieriger zu messen sein als die von überwachten Lernmodellen, da keine eindeutige Zielvariable vorgegeben ist. Eine Möglichkeit, die Leistung zu bewerten, besteht darin, die Konsistenz und Stabilität der Cluster oder Gruppen zu bewerten, die vom Algorithmus identifiziert wurden. Zu den Algorithmen für unüberwachtes Lernen gehören k-Means-Clustering, Hierarchisches Clustering, PCA (Principal Component Analysis) und t-SNE (t-distributed stochastic neighbor embedding).

5. Bestärkendes Lernen (Reinforcement learning)
Bestärkendes Lernen ist etwas anderes als das, was wir gerade besprochen haben. Bestärkendes Lernen ähnelt dem Prozess des Spielens mit Computern und zielt darauf ab, Computer so zu trainieren, dass sie Aktionen in einer Umgebung ausführen, um eine bestimmte Art von erhaltene Belohnung zu maximieren. In einer Reihe von Experimenten lernt der Computer viele Spielmustern, und während eines Spiels kann der Computer das optimale Muster verwenden, um die Belohnung zu maximieren.
Ein bekanntes Beispiel ist Alpha Go, das den besten menschlichen Schachspieler geschlagen hat. Kürzlich wurde das Verstärkungslernen auch auf Echtzeitgebote angewandt.
6. Neuronales Netz (engl. Neural network)
Neuronale Netze sind ein Teilbereich des maschinellen Lernens, der von der Struktur und Funktionsweise des menschlichen Gehirns inspiriert ist. Ein neuronales Netzwerk besteht aus einer großen Anzahl von miteinander verbundenen Neuronen, die in Schichten angeordnet sind und auf Eingaben reagieren.
Die einfachste Form eines neuronalen Netzes ist das sogenannte Feedforward-Netzwerk, bei dem die Informationen nur in eine Richtung durch das Netzwerk fließen, von der Eingabeschicht über versteckte Schichten zur Ausgabeschicht. Jedes Neuron in einer Schicht ist mit den Neuronen der vorherigen und der nachfolgenden Schicht verbunden und führt eine bestimmte Berechnung aus.
Die Berechnungen, die von jedem Neuron im Netzwerk ausgeführt werden, werden durch Gewichte und Aktivierungsfunktionen bestimmt. Gewichte sind Zahlen, die die Stärke der Verbindung zwischen Neuronen repräsentieren, und Aktivierungsfunktionen bestimmen, ob ein Neuron aktiviert wird oder nicht.
Neuronale Netze werden für viele Anwendungen eingesetzt, wie z.B. für die Bild- und Spracherkennung, für die Vorhersage von Zeitreihendaten und für die automatische Übersetzung von Texten. Sie haben auch in der medizinischen Forschung und im Finanzwesen Anwendung gefunden.
NNs haben viele Variante, die häufig benutzt sind:
- Convolutional Neural Network – ein großer Durchbruch in der Computer Vision.
- Rekurrentes neuronales Netzwerk – zur Verarbeitung von Daten mit Sequenzmerkmalen, wie z. B. Text und Aktienkurse.
- Vollständig verbundenes Netzwerk – es ist das einfachste Modell für die Verarbeitung statischer/tabellarischer Daten.
7. Deep Learning
Deep Learning ist ein Teilbereich des maschinellen Lernens, der auf der Verwendung von künstlichen neuronalen Netzen basiert. Im Gegensatz zu traditionellen neuronalen Netzen, die nur wenige Schichten oder Ebenen haben, verwenden Deep Learning-Modelle mehrere Schichten von Neuronen, die nacheinander geschaltet sind, um komplexe Muster in Daten zu erfassen.
Deep Learning-Modelle werden oft verwendet, um komplexe Aufgaben wie Bild- und Spracherkennung, natürliche Sprachverarbeitung und autonome Fahrzeuge zu lösen. Sie können auch verwendet werden, um Vorhersagen in verschiedenen Bereichen wie Finanzen, Gesundheitswesen und Marketing zu treffen.
Eines der Hauptmerkmale von Deep Learning-Modellen ist, dass sie in der Lage sind, automatisch Features aus den Daten zu lernen, anstatt dass diese manuell durch den Entwickler definiert werden müssen. Dies wird durch den Einsatz von Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) und anderen Arten von Deep Learning-Architekturen ermöglicht.
Ein Beispiel für die Anwendung von Deep Learning ist die Gesichtserkennung. Ein CNN kann verwendet werden, um automatisch Features aus Bildern zu extrahieren, die dann von einem RNN verarbeitet werden, um Gesichter in Bildern zu erkennen. Ein weiteres Beispiel ist die maschinelle Übersetzung, bei der RNNs verwendet werden, um die Bedeutung von Sätzen in einer Sprache zu erfassen und sie in eine andere Sprache zu übersetzen.
Deep Learning ist eine leistungsstarke Technologie, die es ermöglicht, komplexe Muster in Daten zu erkennen und Vorhersagen in verschiedenen Bereichen zu treffen. Es erfordert jedoch oft große Mengen an Trainingsdaten und Rechenressourcen und kann schwierig zu interpretieren sein, was es manchmal schwierig macht, die Ergebnisse des Modells zu verstehen.
8. Überanpassung (engl. Overfitting)
Überanpassung (engl. overfitting) ist ein Problem im maschinellen Lernen, bei dem ein Modell zu eng an die Trainingsdaten angepasst ist und dadurch eine schlechte Vorhersageleistung auf neuen Daten aufweist. Das Modell passt sich den Trainingsdaten so stark an, dass es sogar auf unbedeutende oder zufällige Schwankungen in den Daten reagiert und dadurch eine falsche Generalisierung auf neue Daten auftritt.
Ein Beispiel für Überanpassung ist ein Modell, das aus einem Datensatz von Hauspreisen gelernt hat. Wenn das Modell sehr komplex ist und eine zu hohe Anzahl von Variablen oder Features enthält, kann es sich an unbedeutende Details der Trainingsdaten anpassen, wie z.B. den Preis von Häusern in bestimmten Nachbarschaften oder zu bestimmten Jahreszeiten. Dadurch wird das Modell nicht in der Lage sein, korrekte Vorhersagen für neue Daten zu treffen, die sich von den Trainingsdaten unterscheiden.
Um Überanpassung zu vermeiden, können verschiedene Maßnahmen ergriffen werden, wie z.B. die Verwendung von regulierenden Verfahren wie L1- oder L2-Regularisierung, die Reduzierung der Komplexität des Modells oder die Verwendung von Techniken wie Cross-Validation oder Early Stopping. Eine weitere Möglichkeit besteht darin, mehr Daten zu sammeln oder die Daten zu erweitern, um die Generalisierungsfähigkeit des Modells zu verbessern.
Es ist wichtig, Überanpassung zu vermeiden, da ein überangepasstes Modell eine schlechte Vorhersageleistung auf neuen Daten aufweist und nicht in der Lage ist, die zugrunde liegenden Muster in den Daten zu generalisieren. In vielen Fällen kann es auch schwierig sein, zu erkennen, ob ein Modell überangepasst ist oder nicht, da dies oft nur durch Tests auf neuen Daten erkannt werden kann.
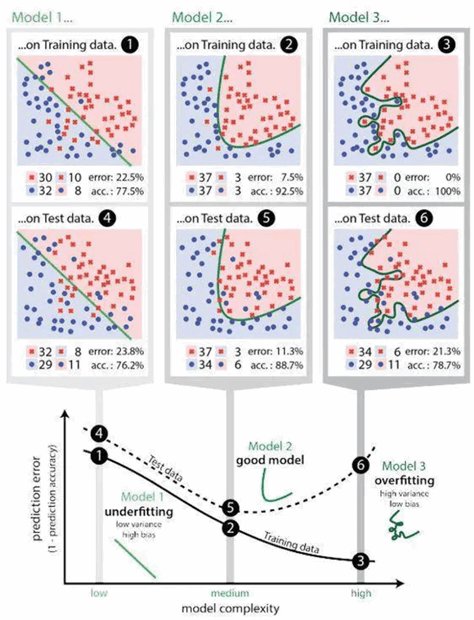
9. Unteranpassung (engl. Underfitting)
Unteranpassung (engl. underfitting) ist ein Problem im maschinellen Lernen, bei dem ein Modell zu einfach oder nicht komplex genug ist, um die zugrunde liegenden Muster in den Trainingsdaten zu erfassen. Unteranpassung tritt auf, wenn das Modell nicht in der Lage ist, die Variabilität der Daten zu erfassen und somit eine schlechte Vorhersageleistung auf neuen Daten aufweist.
Ein Beispiel für Unteranpassung ist ein lineares Regressionsmodell, das auf einen nicht-linearen Zusammenhang zwischen den Variablen angepasst wurde. Das Modell wird nicht in der Lage sein, die nicht-linearen Muster in den Daten zu erfassen und somit eine schlechte Vorhersageleistung auf neuen Daten aufweisen.
Um Unteranpassung zu vermeiden, müssen Modelle eine ausreichende Komplexität aufweisen, um die zugrunde liegenden Muster in den Daten zu erfassen. Dies kann durch die Erhöhung der Anzahl von Features oder die Verwendung von komplexeren Modellen wie neuronalen Netzen erreicht werden.
Eine Möglichkeit, Unteranpassung zu erkennen, besteht darin, das Modell auf den Trainingsdaten und einem Validierungsdatensatz zu trainieren und zu evaluieren. Wenn das Modell auf dem Validierungsdatensatz eine schlechte Leistung aufweist, kann dies ein Hinweis auf Unteranpassung sein.
Es ist wichtig, Unteranpassung zu vermeiden, da ein unterangepasstes Modell die zugrunde liegenden Muster in den Daten nicht erfasst und somit eine schlechte Vorhersageleistung auf neuen Daten aufweist.
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise:Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen:Octoparse für Windows und MacOs
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️




