Der Begriff „Real-time“ oder Echtzeit Web Scraping wird oft missverstanden. Websites pushen Updates nur selten nach außen. In den meisten Fällen ist das, was Unternehmen als Echtzeit-Scraping bezeichnen, eigentlich eine hochfrequente, automatisierte Überprüfung, die darauf ausgelegt ist, Änderungen so schnell wie möglich zu erkennen, ohne blockiert zu werden.
Außerdem ist das Echtzeit Web Scraping von Websites für die meisten Unternehmen von größter Bedeutung. In der Regel gilt: Je aktueller die Informationen sind, über die Sie verfügen, desto mehr Möglichkeiten haben Sie.
In diesem Artikel besprechen wir, was Web Scraping in Echtzeit ist und warum es wichtig ist, sowie welches das beste Tool für Sie ist.
Nicht alles, was „API“ genannt wird, sind Web Scraping Tools
Bevor wir verschiedene Lösungen vergleichen, ist es wichtig, drei Dinge voneinander zu trennen, die häufig vermischt werden.
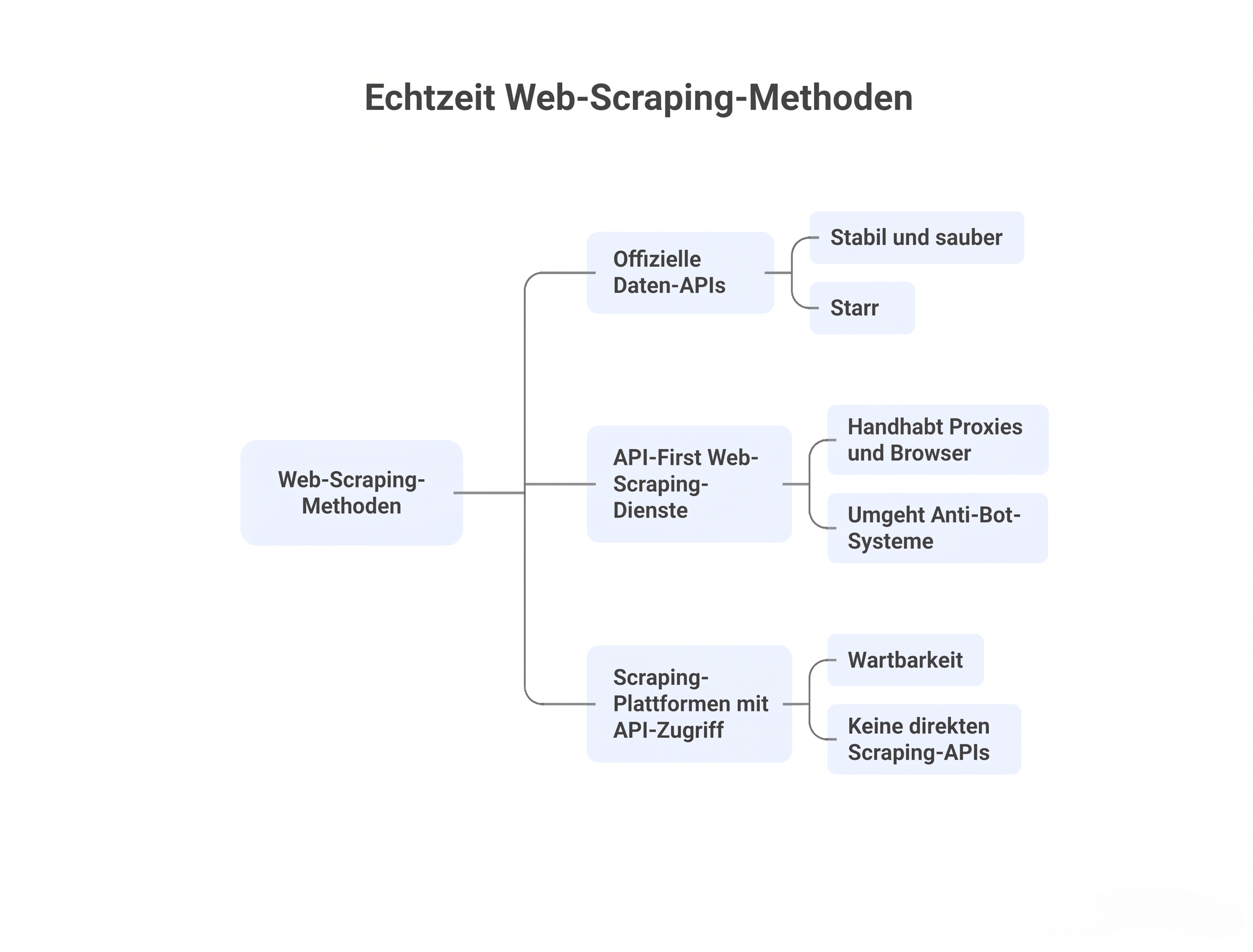
1. Offizielle Daten-APIs (kein Web Scraping)
Beispiele hierfür sind Google Search APIs, Google Maps APIs, Yahoo Finance APIs und ähnliche Dienste.
Ich verwende diese, wenn:
- Die benötigten Daten in ihr Schema passen
- Die Ratenbegrenzungen (Rate Limits) akzeptabel sind
- Lücken in der Abdeckung keine Rolle spielen
Sie sind stabil und sauber, aber starr. In dem Moment, in dem ich Felder benötige, die sie nicht bereitstellen, historische Lücken füllen muss, die sie nicht unterstützen, oder Ergebnisse über die Quoten hinaus brauche, muss ich mich anderweitig umsehen.
Diese APIs liefern lizenzierte Daten, keinen Zugriff auf Webseiten.
2. API-First Web Scraping Dienste
Das ist es, was die meisten Leute meinen, wenn sie nach einer „Web Scraping API“ suchen.
Ich sende eine URL (oder Suchanfrage), konfiguriere ein paar Parameter und der Dienst:
- Verwaltet Proxies und Browser
- Umgeht grundlegende Anti-Bot-Systeme
- Gibt HTML oder strukturiertes JSON zurück
Sie sind anfragegesteuert und zustandslos.
3. Scraping-Plattformen mit API-Zugang
Diese Tools sind keine direkten Scraping-APIs. Stattdessen definiere ich zuerst die Scraping-Logik (visuell oder im Code), automatisiere sie dann und rufe die Ergebnisse über APIs ab.
Sie tauschen Unmittelbarkeit gegen Wartbarkeit ein.
Dieser Unterschied ist wichtig, insbesondere bei Anwendungsfällen für Echtzeit Web Scraping oder nahezu in Echtzeit.
Was „Echtzeit“ beim Web Scraping bedeutet
In der Praxis erfolgt das Web Scraping fast nie in Echtzeit im Sinne von Streaming.
Die meisten „Echtzeit“-Pipelines, die ich aufgebaut habe, basieren auf:
- Hochfrequenten, geplanten Ausführungen (alle paar Minuten)
- Schneller Ausführung
- Sofortiger Bereitstellung, sobald die Extraktion abgeschlossen ist
Da die meisten Websites keine Updates nach außen pushen, geht es beim Echtzeit-Scraping eigentlich darum, wie schnell Sie Website Änderungen überwachen können, ohne blockiert zu werden.
Die besten APIs für Echtzeit Web Scraping Daten
1. ScraperAPI — der schnellste Weg, eine Idee zu testen
ScraperAPI ist normalerweise das erste Tool, das ich ausprobiere, wenn ich überprüfen möchte, ob eine Website überhaupt gescrapt werden kann.
Wie ich es nutze:
- Senden einer URL
- Aktivieren des JavaScript-Renderings bei Bedarf
- Hinzufügen von Länder-Targeting, wenn die Ergebnisse je nach Region abweichen
- Parsen des zurückgegebenen HTMLs oder Nutzung ihrer Auto-Parsing-Optionen
Was mir aufgefallen ist:
- Funktioniert gut für einfache Websites und ungeschützte Seiten
- Das Scraping von Google und Amazon klappt, aber die Antwortzeiten sind langsamer als bei der Konkurrenz
- Einige soziale Plattformen sind standardmäßig blockiert, was die Flexibilität einschränkt
- Der asynchrone Modus ist nützlich, wenn das Rendern Zeit in Anspruch nimmt
Ich verwende ScraperAPI nicht für komplexe Abläufe, aber es ist effektiv für schnelle Experimente und leichtgewichtige Pipelines.
2. ScrapingBee — berechenbar und entwicklerfreundlich
Auf ScrapingBee greife ich zurück, wenn ich weniger Überraschungen erleben möchte.
Im täglichen Gebrauch:
- Die API-Oberfläche ist klein und leicht verständlich
- Das JavaScript-Rendering funktioniert durchgängig
- Die CAPTCHA-Verarbeitung ist bei mittelschweren Seiten zuverlässig
- Die Dokumentation ist so klar, dass ich selten Support benötige
Es ist nicht das schnellste bei großer Skalierung, aber es ist stabil. Wenn ich eine Scraping-API möchte, die „einfach funktioniert“, ohne Dutzende von Parametern anpassen zu müssen, ist ScrapingBee meist ausreichend.
3. Bright Data (Web Unlocker & SERP API) — wenn Zuverlässigkeit wichtiger ist als Kosten
Bright Data ist das, was ich benutze, wenn andere APIs versagen.
In der Praxis:
- Die Erfolgsquoten beim SERP-Scraping sind spürbar höher
- Marktplätze mit aggressiven Blockaden sind besser zugänglich
- Strukturierte Ausgaben reduzieren den Parsing-Aufwand
- Die Konfigurationsmöglichkeiten sind umfangreich — manchmal überwältigend
Dies ist nicht meine Standardwahl. Es ist die API, die ich rechtfertige, wenn Scraping-Fehler geschäftliche Konsequenzen haben.
4. Oxylabs — stark, wenn es auf strukturierte Ausgabe ankommt
Ich verwende Oxylabs normalerweise, wenn mir saubere Datenobjekte wichtiger sind als rohes HTML.
Aus der praktischen Anwendung:
- Die Parsing-Genauigkeit ist hoch, insbesondere bei E-Commerce-Seiten
- Die Antwortzeiten sind wettbewerbsfähig
- Die API unterstützt Zeitplanung und asynchrone Bereitstellung
- Die Preisgestaltung ist erst bei steigendem Volumen sinnvoll
Oxylabs funktioniert gut, wenn ich die Nachbearbeitung und Schema-Wartung minimieren möchte.
5. Octoparse — oft die bessere Lösung
Octoparse verhält sich nicht wie ScraperAPI oder ScrapingBee. Wer auf der Suche nach einer Octoparse Alternative ist, sollte bedenken, dass eine reine API-Bewertung hier am Ziel vorbeischießt.
Wie ich Octoparse tatsächlich nutze:
- Einen Scraper visuell erstellen (Point-and-Click)
- Ihn in die Cloud hochladen
- Ausführungen alle paar Minuten planen
- Ergebnisse über API oder automatisierte Exporte abrufen
Warum ich mich dafür entscheide:
- Auch Nicht-Entwickler können Scraper erstellen und reparieren
- Layout-Änderungen lassen sich visuell leichter beheben
- Die Cloud-Ausführung übernimmt Proxies und Zeitplanung
- Die API konzentriert sich auf die Aufgabensteuerung und Datenbereitstellung, nicht auf das Abrufen von Seiten
Wenn Teams nach „einer API“ fragen, aber eigentlich etwas brauchen, das Monat für Monat zuverlässig funktioniert, reduziert Octoparse oft den Wartungsaufwand.
Wie man Octoparse in einem Echtzeit Web Scraping API-Workflow nutzt
Wenn Leute fragen, ob Octoparse „eine Web Scraping API hat“, stellen sie sich normalerweise so etwas vor:
Senden einer URL → sofortiges Empfangen geparster Daten.
So funktioniert Octoparse nicht — und in realen API-Workflows ist dieser Unterschied wichtiger, als es klingt.
Meiner Erfahrung nach verhält sich Octoparse weniger wie eine anfragebasierte Scraping-API und mehr wie eine API-gesteuerte Scraping-Engine. Man scrapt nicht durch die API; man steuert Scraping-Jobs mit der API.
Hier ist, wie sich das typischerweise in der Praxis abspielt.
Ich beginne damit, den Scraper visuell zu erstellen — durch die Definition von Paginierungsregeln, dynamischem Laden, Login-Schritten und Datenfeldern in der Octoparse-App. Hier haben die meisten Scraping-APIs ohnehin ihre Schwierigkeiten: JavaScript-lastige Seiten, inkonsistente DOMs und Anti-Bot-Systeme lassen sich interaktiv leichter lösen als im Code.
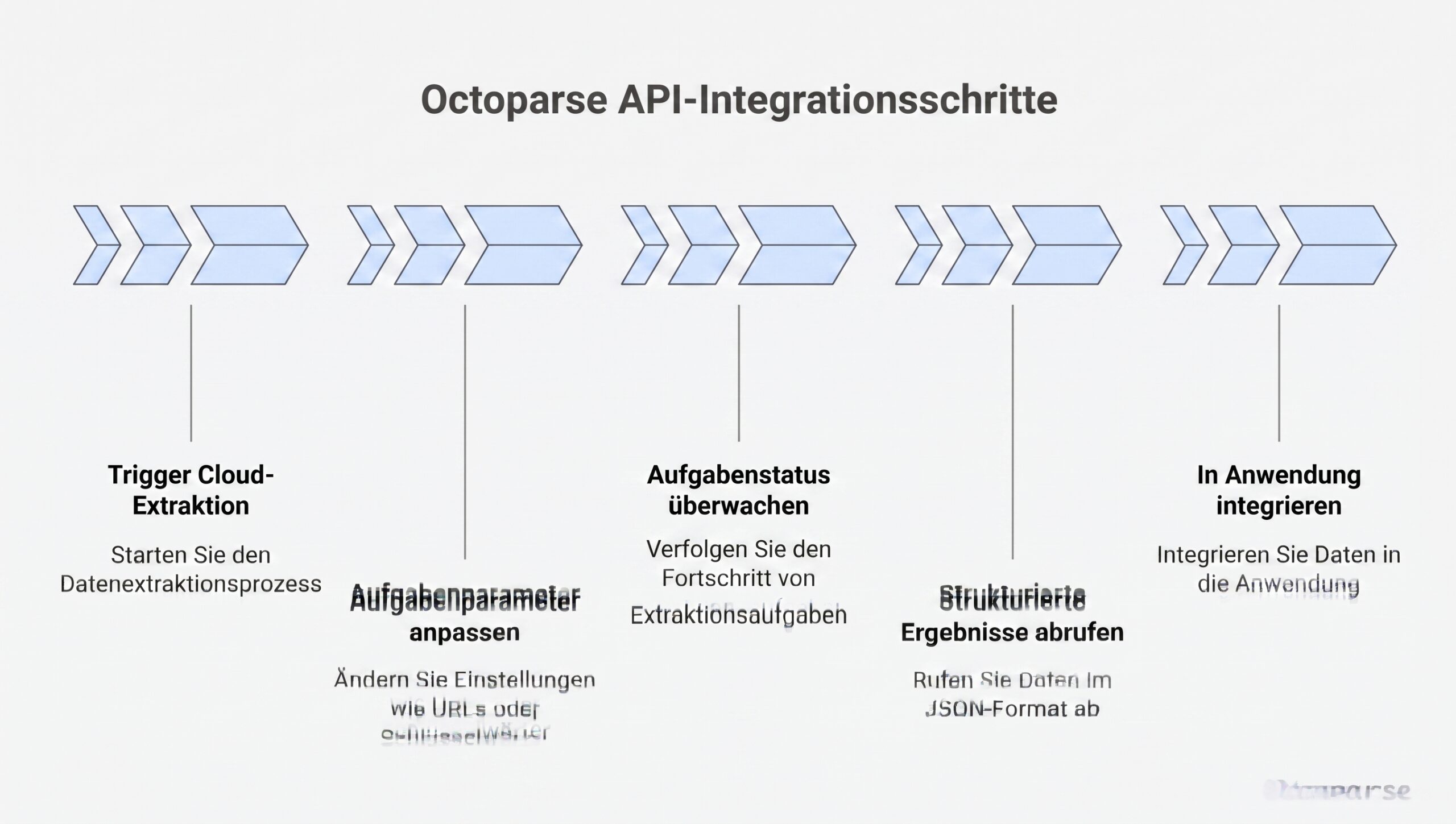
Sobald die Aufgabe stabil ist, wird die API zur Steuerungsebene.
Mit der Octoparse OpenAPI kann ich:
- Cloud-Extraktionsläufe programmgesteuert auslösen
- Aufgabenparameter anpassen (wie Ziel-URLs oder Suchbegriffe)
- Den Status von Aufgaben und Unteraufgaben nahezu in Echtzeit überwachen
- Strukturierte Ergebnisse als JSON in meine Anwendung oder Datenbank ziehen
An diesem Punkt fügt sich Octoparse nahtlos in eine API-gesteuerte Pipeline ein. Mein Backend muss sich nicht um Proxies, Wiederholungsversuche oder Headless-Browser kümmern — es behandelt Octoparse einfach als eine verwaltete Datenquelle, die sich bei Bedarf oder nach Zeitplan aktualisiert.
Dies ist besonders nützlich für „Near-Real-Time“-Anwendungsfälle, bei denen die Aktualität der Daten in Minuten und nicht in Millisekunden gemessen wird:
- Verfolgung von Preis- oder Bestandsänderungen alle 5–10 Minuten
- Aktualisierung von SERP- oder Marktplatzdaten für Dashboards
- Einspeisung aktualisierter Datensätze in Analyse- oder interne Tools
Scrapen Sie Echtzeit-Daten mit der Octoparse API
Octoparse und seine Web Scraping API wären Ihre beste Wahl. Es lässt sich eine API-Integration aufbauen, mit der Sie zwei Dinge erreichen können:
1. Extrahieren beliebiger Daten von der Website, ohne auf die Antwort eines Webservers warten zu müssen.
2. Automatisches Senden der extrahierten Daten aus der Cloud an Ihre internen Anwendungen über die Octoparse API-Integration.
Wenn Sie ebenfalls frustriert über die Nutzung einer reinen API sind, werden Sie in Octoparse großen Mehrwert finden, da der Integrationsprozess sehr einfach ist.

Einfaches Scrapen von Daten mit Auto-Detect-Funktionen, keine Programmierkenntnisse erforderlich.
Echtzeit-Scraping mit IP-Proxies und Rotation.
Cloud-Service und Aufgabenplanung zum Scrapen von Daten in Echtzeit.
Wie ich zwischen den besten APIs für Echtzeit Web Scraping wähle (Entscheidungslogik)
Hier ist die Logik, die ich tatsächlich anwende:
- Benötigen Sie sofortiges HTML von einer URL?
→ ScraperAPI oder Octoparse - Benötigen Sie strukturierte Daten, ohne Parser zu schreiben?
→ Octoparse oder Bright Data APIs - Benötigen Sie benutzerdefinierte Workflows oder wartbares, wiederholbares Scraping ohne viel Programmierung?
→ Octoparse
Es gibt keine einzelne „beste“ Web Scraping API — nur Tools, die zu unterschiedlichen betrieblichen Anforderungen passen.
Fazit
Die Einschränkung wird im Vergleich zu direkten Scraping-APIs deutlich. Wenn Ihr Workflow davon abhängt, beliebige URLs spontan zu scrapen oder auf benutzergesteuerte Anfragen zu reagieren, wird sich Octoparse indirekt anfühlen. Der Einrichtungsaufwand ist real, und Spontanität ist nicht seine Stärke.
Aber wenn das Ziel ist, überhaupt nicht mehr über das Scraping nachdenken zu müssen — Daten planmäßig eintreffen zu lassen und nahtlos in ein bestehendes System zu integrieren —, beginnt dieses Modell Sinn zu machen. Bei der API von Octoparse geht es nicht darum, das Web schneller zu erreichen. Es geht darum, einen Punkt zu erreichen, an dem das Scraping den Rest Ihrer Arbeit nicht mehr unterbricht.
Dieser Unterschied ist subtil, aber wenn Sie einmal beide Modelle genutzt haben, ist er kaum noch zu übersehen.
Häufig gestellte Fragen zu Echtzeit Web Scraping APIs
1. Kann eine Websuche-API HTML-Content-Scraping für Wissensaktualisierungen in Echtzeit durchführen und ist sie damit ein Muss für dynamische Branchen?
Nein. Eine Websuche-API (Google, Bing usw.) führt kein HTML-Content-Scraping durch.
Was sie tun kann:
- Indexierte Suchergebnisse zurückgeben
- Metadaten bereitstellen (Titel, Snippet, URL, manchmal Ranking-Signale)
- Änderungen widerspiegeln, nachdem die Suchmaschine eine Seite gecrawlt und neu indexiert hat
Was sie nicht tun kann:
- Live-HTML von beliebigen Seiten abrufen
- Inhalte auf Seitenebene extrahieren
- Aktualität in dem Moment garantieren, in dem sich Inhalte ändern
Das macht Such-APIs zu einer Ergänzung, aber nicht zu einem Ersatz für Web Scraping.
2. Ist eine Web Scraping API dasselbe wie eine öffentliche Daten-API wie Google Finance oder Yahoo Finance?
Nein. Diese dienen grundlegend unterschiedlichen Zwecken.
Öffentliche Daten-APIs (wie die Endpunkte von Google Finance oder Yahoo Finance) stellen vordefinierte Datensätze bereit, die vom Anbieter ausgewählt und gepflegt werden. Sie können nur das anfordern, was der API-Besitzer zur Verfügung stellt, und das in der von ihm kontrollierten Struktur.
Web Scraping APIs hingegen rufen Daten direkt von Webseiten ab. Sie sind nicht vom Schema oder dem Aktualisierungsrhythmus eines Anbieters abhängig. Aus diesem Grund werden Scraping-APIs häufig verwendet, wenn öffentliche APIs unvollständig oder verzögert sind oder eingestellt wurden.
Kurz gesagt:
- Öffentliche APIs bieten Stabilität und Compliance.
- Scraping-APIs bieten Abdeckung und Flexibilität.
Sie ergänzen sich und sind nicht austauschbar.
3. Können Web Scraping APIs die Datengenauigkeit in „Echtzeit“ garantieren?
Nicht im strengen Sinne von Streaming.
Die meisten Web Scraping APIs simulieren den Echtzeitzugriff durch hochfrequente Anfragen, nicht durch kontinuierliche Daten-Feeds. Die Daten sind nur so aktuell wie der Moment, in dem die Seite abgerufen wird, bleiben aber weiterhin Pull-basiert.
Echte Echtzeitsysteme erfordern, dass die Datenquelle Updates pusht, was die meisten Websites nicht zulassen. Scraping-APIs arbeiten innerhalb dieser Einschränkung, indem sie das Timing der Anfragen, die Proxy-Rotation und die Liefergeschwindigkeit optimieren.
Diese Unterscheidung ist wichtig für Anwendungsfälle wie:
- Blitzartige Preisänderungen
- Bestandsüberwachung
- Nachrichten- oder Ankündigungs-Tracking
In diesen Szenarien ist „nahezu in Echtzeit“ (Near Real-Time) in der Praxis meist das Maximum.
4. Wann sollten Sie eine Such-API anstelle einer Web Scraping API verwenden?
Such-APIs eignen sich besser für die Entdeckung (Discovery), nicht für die Extraktion.
Wenn es Ihr Ziel ist:
- Relevante Seiten zu identifizieren
- Die Sichtbarkeit in Suchergebnissen zu verfolgen
- Zu überwachen, wie sich Informationen im Web verbreiten
dann ist eine Such-API oft ausreichend.
Wenn es Ihr Ziel ist:
- Strukturierte Felder zu sammeln
- Änderungen auf Seitenebene zu verfolgen
- Rohe Inhalte zur Analyse zu speichern
dann ist eine Scraping-API oder ein Scraping-Workflow erforderlich.
Die Verwendung einer Such-API als Ersatz für Scraping führt oft zu unvollständigen Daten und falscher Sicherheit.
5. Werden Tools wie Octoparse als „Web Scraping APIs“ betrachtet?
Nicht im engeren Sinne.
Octoparse ist kein einzelner Endpunkt, der bei Bedarf HTML abruft. Es ist ein Scraping-System, das API-Zugriff auf verwaltete Extraktions-Workflows bietet.
Diese Unterscheidung erklärt, warum Octoparse häufig verwendet wird für:
- Geplante Datenerfassung
- Langfristige Überwachungsprojekte
- Integration mit internen Datenbanken oder BI-Tools
und weniger häufig verwendet wird für:
- Benutzergesteuertes, spontanes Scraping
- Zustandslose API-Aufrufe
Das Verständnis dieses Unterschieds hilft, falsche Erwartungen bei der Bewertung von „API-basiertem Scraping“ zu vermeiden.
6. Warum kombinieren einige Unternehmen Such-APIs und Scraping-APIs im selben Workflow?
Weil jedes eine Lücke füllt, die das andere nicht schließen kann.
Ein gängiges Muster ist:
- Verwendung einer Such-API, um neue oder aktualisierte URLs zu entdecken.
- Verwendung einer Scraping-API oder Scraping-Plattform, um Daten auf Seitenebene aus diesen URLs zu extrahieren.
- Interne Speicherung und Analyse der Ergebnisse.
Dieser hybride Ansatz reduziert unnötiges Scraping und bewahrt gleichzeitig die Datentiefe und Aktualität.
Es ist nicht redundant. Es ist architektonisch bedingt.
7. Macht die Verwendung einer API Web Scraping legal oder konformer?
Eine API ändert nichts an den grundlegenden Compliance-Überlegungen.
Egal, ob Sie über Code, eine proxybasierte API oder eine verwaltete Plattform scrapen, es gelten die gleichen Faktoren:
- Nutzungsbedingungen der Website
- Robots.txt-Richtlinien
- Datenschutz- und Nutzungsbestimmungen
APIs reduzieren die technische Komplexität, nicht die Verantwortung. Die Einhaltung der Vorschriften bleibt weiterhin Aufgabe des Nutzers.



