XPath spielt eine sehr wichtige Rolle in Octoparse, wenn Sie dabei Daten scrapen. Umschreiben des XPath kann Ihnen helfen, mit den fehlenden Seiten, Daten oder Duplikate usw. umzugehen. Während XPath am Anfang für die Benutzer*innen schwierig ausgesehen ist, machen Sie keine Sorgen darum. In diesem Artikel würde ich detailliert XPath vorstellen, damit Sie verstehen können, was XPath ist und wie sie verwendet wird, um durch genaue und präzise Bauaufgaben Ihre gewünschten Daten zu scrapen.
1. Was ist XPath?
XPath (XML Path Language) stellt für Selektieren der Elemente aus einem XML/HTML-Dokument eine Abfragesprache dar. Sie können schnell und präzis durch XPath ein Element aus dem ganzen Dokument finden.
Webseiten werden in der Regel in einer Sprache namens HTML geschrieben. Wenn Sie eine Webseite auf einen Browser (Chrome, Firefox usw.) laden, können Sie einfach beim Klick auf F12-Taste das entsprechende Dokument besuchen. Alles, das Sie auf der Webseite sehen könnten, könnte innerhalb des HTML gefunden werden, z.B. Bild, Textblöcke, Links, Menüs usw.
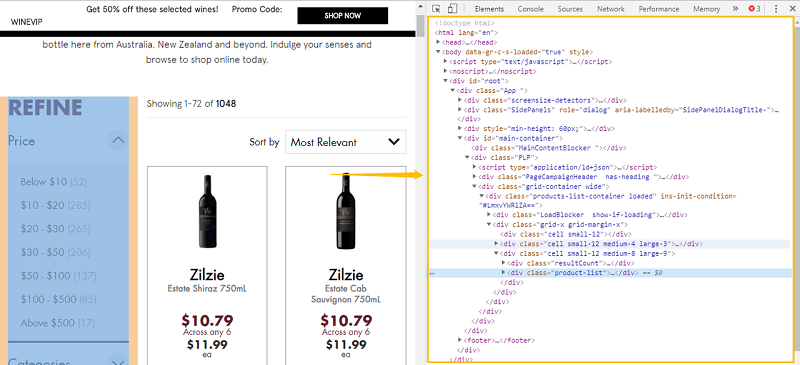
XPath ist die häufigst verwendete Sprache, wenn man ein Element in einem HTML-Dokument lokalisieren möchte. Es ist leicht zu verstehen, dass man durch es, das als „Route“ bezeichnet wird, innerhalb eines Dokumentes das Zielelement finden kann.
Um tiefer zu erklären, wie XPath funktioniert, schauen wir zusammen dieses Beispiel.
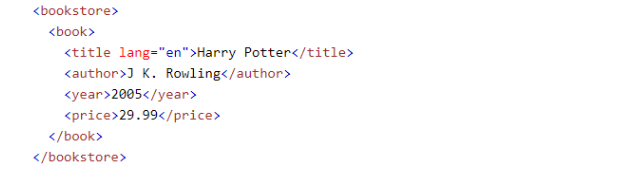
Das Bild zeigt einen Teil von einem HTML-Dokument.
HTML hat verschiedene Stufen von Elementen, gerade wie eine Baumstruktur. In diesem Beispiel gehört „bookstore“ zur Stufe-1 und „book“ zur Stufe-2. „Title“, „author“ und „price“ gehören zur Stufe-3.
Texte in spitzen Klammern (<bookstore>) werden einen Tag genannt. Ein HTML-Element besteht normalerweise aus einen Start-Tag und einen End-Tag, gleichzeitig werden die Texte zwischen den beiden liegen.
XPath verwendet „/“ zur Verbindung der Tags von verschiedenen Stufen, die von oben bis unten, um die Stelle eines Elementes festzulegen. Wenn Sie das „author“ Element lokalisieren möchten, würde XPath in unseren Beispiele wie folgend aussehen:
/bookstore/book/author
Wenn Sie beim Verstehen seines Arbeitsprinzipes auf die Probleme gestoßen haben, können Sie daran denken, wie wir in unserem Gerät eine bestimmte Akte finden können.

Um die Akte mit dem Namen „author“ zu finden, ist der genaue Akte-Route „ \bookstore\book\author“. Kommt Ihnen das bekannt vor?
Jede Akte auf dem Gerät hat ihre eigene Route, wie die Elemente auf einer Webseite. Mit XPath können Sie schnell und einfach die Seitenelemente finden, gerade wie Sie eine Akte auf Ihrem Gerät finden.
Der XPath wird Matching-XPath genannt, der vom Wurzelelement (dem obersten Element im Dokument) ausgeht und alle Elemente dazwischen zum Zielelement durchläuft.
Beispiel:
Absolute Route könnte lang und verwirrend werden, sodass wir „//“ zur Vereinfachung des Absoluten XPath verwenden, um das Element zu referenzieren, womit Sie den XPath starten möchten (auch bekannt als ein kurzer XPath). Zum Beispiel könnte der kurze XPath „/bookstore/book/author“ als „//book/author“ beschrieben werden. Dieser kurze XPath würde das „book“ Element versuchen, während er von seiner absoluten Stelle in HTML unabhängig ist. Dann würde er eine Ebene nach unten gehen, um das Zielelement von „author“ zu finden.
2. Wie wird XPath in Octoparse verwendet (einfaches XPath-Tutorial)
Wenn Sie die Daten auf der Webseiten ohne Kodierung scrapen möchten, gibt es hier 3 Schritte:
- Schritt 1: Laden Sie Octoparse herunter und melden Sie sich mit einem kostenlosen Konto.
- Schritt 2: Öffnen Sie die benötigte Webseite, um die URL zu kopieren und zu extrahieren. Geben Sie sie in Octoparse ein, danach starten Sie Octoparse. Gleichzeitig können Sie auch inpiduell die Datenfelder aus dem Vorschaumodus oder -workflow rechts einrichten.
- Schritt 3: Starten Sie Ihr Scraping durch dem Klick auf „Run“ Button. Die extrahierten Daten können als Excel-Format auf Ihrem Gerät heruntergeladen werden.
Eigentlich ist Scraping der Webseiten in Octoparse es, die Elemente aus HTML-Dateien zu scrapen. XPath wird oft in diesem Fall verwendet, wenn man die Ziel-Elemente aus einer Datei lokalisieren möchte.
Nachdem wir den „Nächste“ Button ausgewählt haben, um eine Paginierung einzurichten, würde Octoparse einen XPath generieren, um den „Nächste“ Button zu lokalisieren, sodass es erkennt, auf welchen Button geklickt werden sollte.
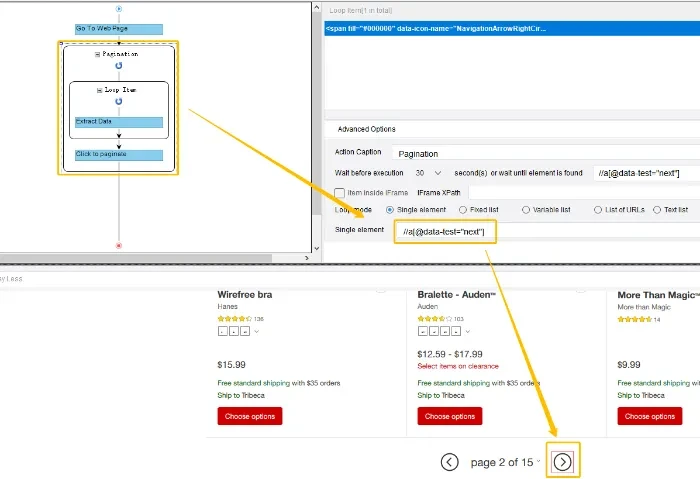
XPath kann dem Crawler helfen, auf den richtigen Button zu klicken oder die Zieldaten zu scrapen. Beliebige Aktion, die Sie Octoparse tun lassen möchten, basiert auf den zugrunde liegenden XPath. Octoparse könnte automatisch die XPaths generieren, aber der automatisch generierte XPath funktioniert nicht immer gut. Das ist die Ursache, warum wir lernen sollten, XPath umzuschreiben.
Während des Umgangs mit den Probleme, wie fehlenden Daten, unendlosem Loop, falschen Daten, Duplikaten, nicht funktioniertem Button von „Nächste“ und so weiter, gibt es eine gute Chance, dass Sie einfach durch die Umschreibung von XPath sie verändern.
3. Wie wird eine XPath beschrieben (einschließlich Cheat Sheet)
Bevor wir beginnen, einen XPath zu schreiben, schauen wir zuerst einige Schlüsselbegriffe. Da können Sie ein tieferes Verständnis über XPath-Ausdrücke erhalten. Es gibt im folgenden ein leichtes HTML, das wir verwenden können.

Attribute/value
Ein Attribut (Attribute im Bild) bietet zusätzliche Information über ein Element an und wird immer im Start-Tag des Elements angegeben. Ein Attribut erscheint meistens als das Paar vom Namen/Wert, wie „name=’value’“. Einige häufigst verwendete Attribute sind href, title, style, src, id, class usw. Sie können die vollständige HTML Attribute Referenz hier finden.
In unserem Beispiel ist „id=’book’“ das Attribut vom Element <p> und „class=’book_name’“ das Attribut vom Element <span>.

Parent/child/sibling
Wenn ein oder mehr HTML-Elemente sind in ein Element enthalten, würde das Element als das übergeordnete Element (Parent) bezeichnet, das die anderen Elemente enthält. Gleichzeitig wird jedes enthaltene Element als das untergeordnete Element (Child) des übergeordneten Elements bezeichnet. Jedes Element hat nur ein übergeordnetes Element, während es vielleicht null, ein oder mehr übergeordnete Elemente enthält. übergeordnete Elemente werden zwischen dem Start-Tag und dem End-Tag vom übergeordneten Element gefunden.
In unserem Beispiel ist das <body> Element das übergeordnete Element von den Elemente <h1> und <p>. Die Elements von <h1> und <p> sind die übergeordnete Elemente vom Element <body>.
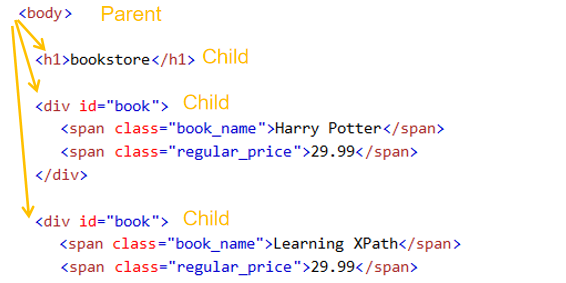
Das <p> Element ist das übergeordnete Element von zwei Elementen <span>. Die Elemente von <span> sind die übergeordneten Elemente vom Element <p>.
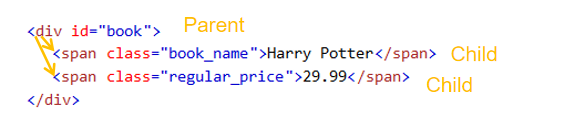
Elemente, die ein gleiches übergeordnetes Element haben, werden als Geschwister bezeichnet. Die Elemente von <h1> und <p> sind Geschwister, weil sie ein gleiches übergeordnetes Element <body> haben.
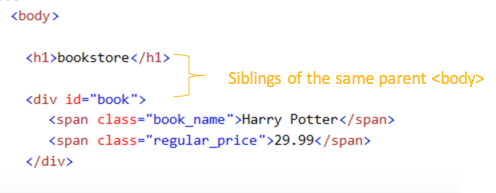
Die zwei Elemente von <span> sind auch Geschwister, die unter dem Element von <p> stehten.

Nachdem Sie sich über diese einfachen HTML-Codes erfahren haben, gibt es im Folgenden einige Fälle mit XPath Ausdrücke-Beispiele, dabei würde ich drei übliche XPath Funktionen vorstellen.
Beschreibung eines XPath zur Lokalisierung von „Nächste“
Zuerst müssen wir den Button von „Nächste“ im HTML genau untersuchen. In dem folgenden Beispiel-HTML gibt es zwei hervorgehobene Sachen. Eine ist der Titel-Attribut mit dem Wert von „Nächste“ (Attribute im Bild). Der andere ist der Inhalt von „Nächste“ (Content im Bild).
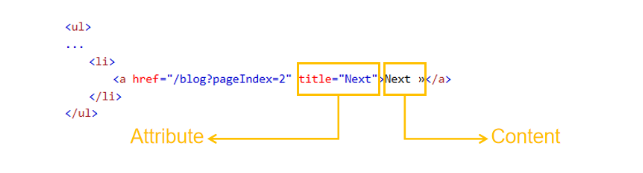
In diesem Fall können wir sowohl das Attribut von „title“ als auch den Inhalt vom Text verwenden, um den Button von „Nächste“ in HTML zu lokalisieren.
Der XPath wird wie folgend aussehen, der das <a> Element lokalisiert, das ein Attribut von „title“ mit dem Wert „Nächste“:
Der XPath bedeutet: Gehen Sie auf das <a> Element(e), dessen title-Attribut „Next“ ist. Das Symbol @ wird im XPath verwendet, um auf ein Attribut abzuzielen.
Alternativ könnte der XPath wie folgend aussehen, der das <a> Element lokalisiert, das den Text von „Nächste“ enthält:
Der XPath bedeutet: Gehen Sie auf das <a> Element(e), dessen Inhalt „Next“ ist.
Sie können auch beide Elemente (title-Attribut und Inhalt) benutzen, um den XPath zu schreiben:
Dieser XPath bedeutet: Gehen Sie auf das <a> Element(e), das(die) ein title-Attribut mit dem Wert „Nächste“ hat(haben) und dessen Inhalt „Nächste“ enthält.
Beschreibung eines XPath zur Lokalisierung von Loop Item
Um eine Liste der Items auf einer Webseite zu anvisieren, ist es besonders wichtig, unter den Listeneinträgen nach dem Muster zu suchen. Die Items in der gleichen Liste haben in der Regel die gleichen oder ähnlichen Attribute. In dem folgenden Beispiel-HTML sehen wir, dass alle Elemente ähnliche „class“ Attribute haben.

Aufgrund der Beobachtung können wir „contains(@attribute)“ verwenden, um alle Items der Liste zu anvisieren.
//li[contains(@class,”product_item”)]
Der XPath bedeutet: Gehen Sie auf das <li> Element(e), dessen „class“ Attribute „product_item“ enthalten.
Beschreibung eines XPath zur Lokalisierung von Datenfelder
Es ist ganz ähnlich wie Lokalisierung des „Nächste“ Button, indem Sie „text()“ oder „attribute“ verwenden, ein bestimmtes Datenfeld zu lokalisieren.

Wenn wir einen XPath beschreiben möchten, der die Addresse vom obenen HTML-Beispiel lokalisiert könnte, können wir das „itemprop“ Attribut verwenden, das den „address“ Wert enthält, um das bestimmte Element zu anvisieren.
Der XPath bedeutet: Gehen Sie auf das <p> Element(e), welches das „itemprop“ Attribut mit dem „address“ Wert enthält.
Es gibt auch eine andere Beschreibungsform. Beachten Sie, dass das <p> Element, das die tatsächliche Adresse enthält, immer unter seinem gemeinsamen <p> Element gefunden wird, das den Inhalt „Location:“ enthält. So können wir zuerst den Text „Location“ finden und dann das erste Geschwister auswählen, das folgt.
Der XPath bedeutet: Gehen Sie auf das <p> Element(e), welches das „Location“ im Text enthält, dann gehen Sie auf sein erstes Geschwister-<p>-Element.
Nun haben Sie vielleicht bereits notiert, dass es mehr als eine Methode gibt, um ein Element in HTML zu anvisieren. Es ist genauso wie das aussehen, dass es immer mehr als eine Route gibt, um ein beliebiges Gebiet einzugehen. Der Schlüssel besteht darin, das Tag, die Attribute, den Inhaltstext, die Geschwister, das übergeordnete Element und alles zu verwenden, was Ihnen hilft, das Zielelement im HTML zu finden.
Damit Sie ein besseres Verständnis dafür haben können, gibt es ein Cheat Sheet von hilfreichen XPath-Ausdrücken, um Ihnen zu helfen, dass Sie schnell jedes Element in HTML anvisieren können.
| Ausdruck | Beispiel | Bedeutung |
| * Mit jedem Element übereinstimmen | //p/* | Selektieren Sie alle untergeordneten <p> Elemente. |
| @ Attribute selektieren | //p[@id=”book”] | Selektieren Sie alle <p> Elemente, die ein „id“ Attribut mit einem „book“ Wert enthalten. |
| text() Elemente mit exaktem Text finden | //span[text()=”Harry Potter”] | Selektieren alle <span> Elemente, deren Text exakt „Harry Potter“ enthält. |
| contains() Elemente selektieren, die einen bestimmten String enthalten | //span[contains(@class, “price”)] | Selektieren Sie alle <span> Elemente, deren „class“ Attribut-Wert „price“ enthalten. |
| //span[contains(text(),”Learning”)] | Selektieren Sie alle <span> Elemente, deren Inhalt „Learning“ enthalten. | |
| position() Elemente in einer sicheren Stelle selektieren | //p/span[position()=2]//p/span[2] | Selektieren Sie das zweite <span> Element, welches das untergeordnete Element vom <p> Element ist. |
| //p/span[position()<3] | Selektieren Sie die ersten 2 <span> Elemente, welche die untergeordneten Elemente vom <p> Element sind. | |
| last() Das letzte Element selektieren | //p/span[last()] | Selektieren Sie das letzte <span> Element, welches das untergeordnete Element vom <p> Element ist. |
| //p/span[last()-1] | Selektieren Sie das letzte aber ein <span> Element, welches das untergeordnete Element vom <p> Element ist. | |
| //p/span[position()>last()-3] | Selektieren Sie die letzten 3 <span> Elemente, welche die untergeordneten Elemente vom <p> Element sind. | |
| not Elemente selektieren, die den angegebenen Bedingungen entgegengesetzt sind | //span[not(contains(@class,”price”))] | Selektieren Sie alle <span> Elemente, deren „class“ Attribute-value „price“ nicht enthält. |
| //span[not(contains(text(),”Learning”))] | Selektieren Sie alle <span> Elemente, deren Inhalt „Learning“ nicht enthält. | |
| and Elemente selektieren, die mit einigen Bedingungen übereinstimmen | //span[@class=”book_name” and text()=”Harry Potter”] | Selektieren Sie ale <span> Elemente, deren „class“ Attribute-value „book_name“ und deren Inhalt gleichzeitig „Harry Potter“ enthält. |
| or Elemente selektieren, die mit eine von Bedingungen übereinstimmen | //span[@class=”book_name” or text()=”Harry Potter”] | Selektieren Sie alle <span> Elemente, deren „class“ Attribute-value „book_name“ oder deren Inhalt „Harry Potter“ ist. |
| following-sibling Alle Geschwister nach dem gegenwärtigen Element selektieren | //span[text()=”Harry Potter”]/following-sibling::span[1] | Selektieren Sie das erste <span> Element nach dem <span> Element, dessen Inhalt „Harry Potter“ ist. |
| preceding-sibling Alle Geschwister vor dem gegenwärtigen Element selektieren | //span[@class=”regular_price”]/preceding-sibling::span[1] | Selektieren Sie das erste <span> Element vor das <span> Element, dessen „class“ Attribute-value „regular_price“ ist. |
| .. Das übergeordnete Element vom gegenwärtigen Element selektieren | //p[@id=”bookstore”]/.. | Selektieren Sie das übergeordnete Element vom <p> Element, dessen „id“ Attribute-value „bookstore“ ist. |
| | Einige Routen selektieren | //p[@id=”bookstore”] | //span[@class=”regular_price”] | Selektieren Sie alle <p> Elemente, deren „id“ Attribute-value „bookstore“ ist und alle <span> Elemente, deren „class“ Attribute-value „regular_price“ ist. |
*Beachten Sie, dass das Attribut und der Textwert alle Groß- und Kleinschreibung berücksichtigen.
*Um eine vollständigere Liste von den XPath-Ausdrücken zu sehen, klicken Sie hier.
4. Matching-XPath und Relativer XPath (für Loop)
Bisher haben wir behandelt, wie man einen XPath schreibt, wenn Sie ein Element von einer Webseite extrahieren müssen. Jetzt brauchen Sie vielleicht es zu tun, zuerst eine Liste der Ziel-Items einzurichten und dann die Daten aus jedem Item zu scrapen. Z.B. Wenn Sie die Daten aus den Ergebnisseiten wie das scrapen möchten: https://www.bestbuy.com/site/promo/tv-deals
In diesem Fall sollten Sie nicht nur den Matching-XPath (,den Sie direkt zur Erfassung der Elemente verwenden könnten) sondern auch den Relativen XPathvon Loop Item erlernen, der den Speicherort des bestimmten Listenelements relativ zur Liste angibt.
In Octoparse würden Sie zwei XPath-Kästen sehen, wenn Sie den XPath eines Datenfeldes modifizieren.
Matching-XPath wird verwendet, wenn wir die Daten direkt aus der Webseite scrapen.

Der Workflow sieht meistens wie folgend aus:
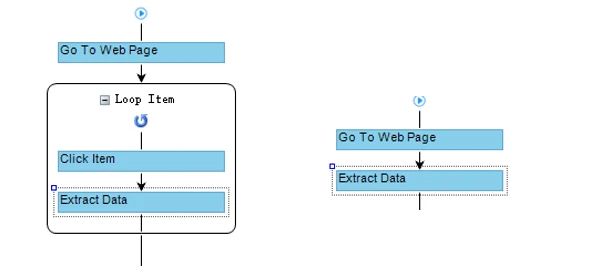
Relativer XPath wird verwendet, wenn wir die Daten aus einem Loop Item scrapen möchten. Vor allem, wenn wir einen Workflow wie das folgende Bild einrichten:
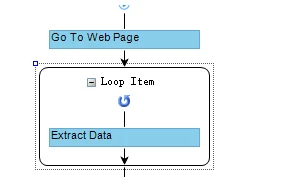
Der Relative XPath in Octoparse ist ein zusätzlicher Teil des Matching-XPath relativ zu Loop Item-XPath.

Zum Beispiel können wir den XPath //ul[@class=”results”]/li verwenden, um die Liste zu lokalisieren, wenn wir eine Loop-Liste von <li>-Elementen einrichten und ein Element scrapen möchten, das in den einzelnen <li>-Elemente in der Liste enthalten ist.
Wenn der XPath eines Elementes auf der Liste //ul[@class=”results”]/li/p/a[@class=”link”] ist, sollte der Relative XPath in diesem Fall /p/a[@class=”link”] werden. Oder wir können „//“ vor //a[@class=”link”] hinzufügen, um diesen Relativen XPath zu vereinfachen. Es ist besser, „//“ zu verwenden, wenn ein Relativer XPath beschrieben wird, weil es den Ausdruck präziser werden lassen.
Machen wir es einfacher, die Beziehung zwischen den verschiedenen XPaths zu sehen.
Loop Item XPath:
XPath vom Element, das Sie verwenden möchten, um die Stelle in Loop Item zu lokalisieren:
Relativer XPath zum Loop Item:
Wir sollten dann den Matching-XPath und den Relativen XPath wie folgend in Octoparse eingeben:

Jetzt haben Sie vermutlich bereits notiert, dass Sie dort genau den XPath für das Element bekommen, wenn der XPath für die Schleifenliste und der relative XPath zu einem XPath kombiniert werden.
5. Vier einfache Schritte zur Festlegung Ihrer XPath
Schritt 1
Öffnen Sie die Website, indem Sie einen Browser mit einem XPath-Tool verwenden (, das Ihnen es ermöglicht, HTML zu sehen und eine XPath-Abfrage nachzuschlagen). Path helper (ein Plug-in von Chrome) ist immer wertvoll zu empfehlen, wenn Sie Chrome verwenden.
Schritt 2
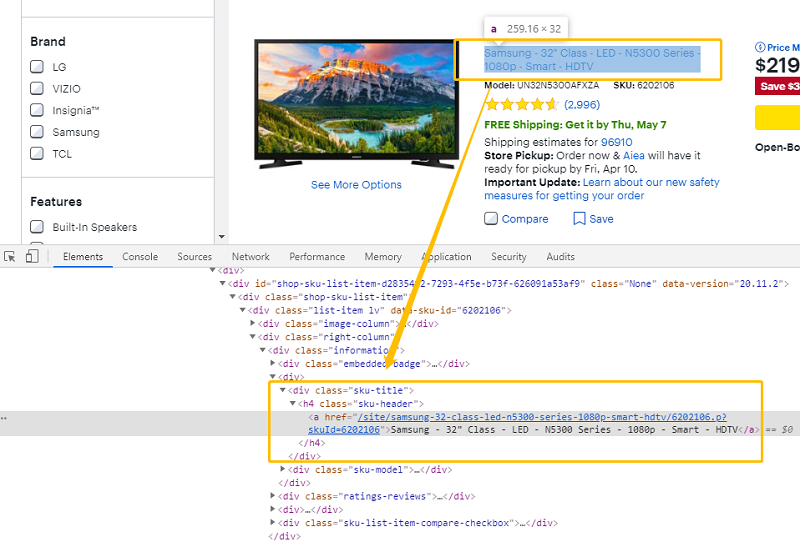
Wenn die Website geladen ist, untersuchen Sie das Ziel-Element in HTML.
Schritt 3
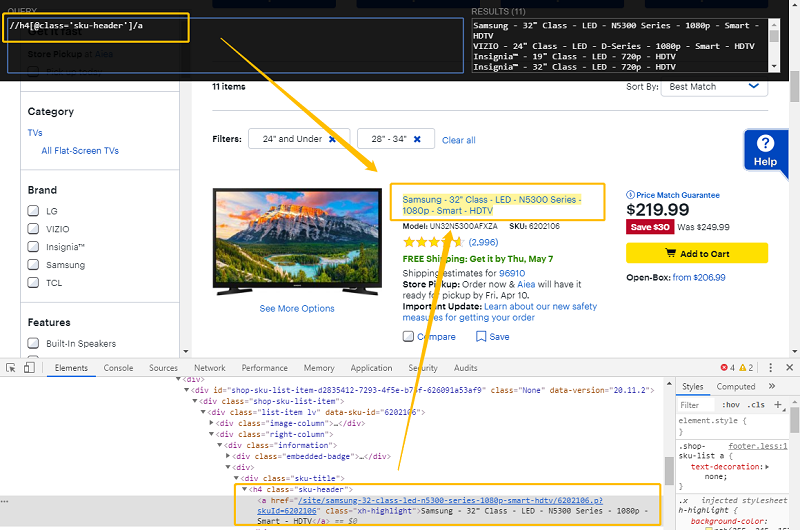
Untersuchen Sie das HTML-Element und die Elemente in der Nähe genau. Sehen Sie etwas, was hervorgehoben ist und Ihnen vielleicht helfen, das Ziel-Element zu identifizieren und lokalisieren? Es ist möglich, dass es ein „class“ Attribut wie class=”sku-title” oder class=”sku-header” gibt?

Verwenden Sie das obige Cheat sheet, um einen XPath zu schreiben, der das Element exklusiv und genau selektiert. Ihr XPath sollte nur das Ziel-Element(e) entsprechen. Bei der Verwendung von XPath helper können Sie immer überprüfen, ob der umgeschriebene XPath richtig funktionieren könnte.
Schritt 4
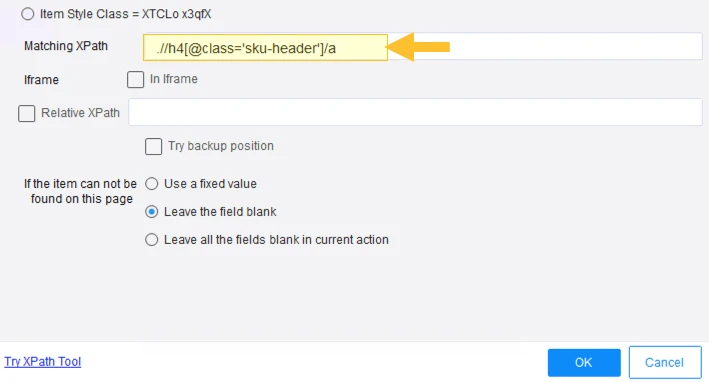
Ersetzen Sie den automatisch generierten XPath in Octoparse.
6. Xpath-Tutorials von Fehlerbehebung
In mehreren Fällen brauchen Sie nicht selbst einen XPath zu schreiben. Aber es gibt einige Situationen, wo Sie vielleicht einige Modifikationen nehmen sollten, um die Daten exakt zu scrapen.
Situation 1: Fehlerbehebung von Loop
- Fehlen an Items im Loop:
Was tun, wenn Octoparse nicht alle Elemente in der Liste erkennt?
- Falsche Datenextraktion bei Scraping aus Loop Item:
Warum erhaltet Octoparse weniger Daten, obwohl es mehr sein sollten?
- Datenduplikate
Warum so viele Duplikate und wie sie zu löschen?
Situation 2: Fehlerbehebung von Paginierung
- Übersprung einer Seit
Warum überspringt Octoparse Seiten während des Scrapens?
- Scraping der letzten Seite
Warum scrapt Octoparse immer wieder die letzte Seite und hört nicht auf?
Situation 3: Fehlerbehebung von Feldern
- Extraktion eines falschen Feld
Lokalisierung des Elementes durch nahegelegenen Text
7. XPath Tools
Es ist nicht leicht, das HTML-Code direkt in Octoparse zu sehen. Deshalb sollten wir einige andere Tools verwenden, um einen XPath zu generieren.
Chrome XPath/Jeder Browser
Sie können einen XPath für ein Element einfach mit jedem Browser erhalten. Lassen wir Chrome als Beispiel sehen.
- Schritt 1: Öffnen Sie die Website in Chrome.
- Schritt 2: Drücken Sie die rechte Maustaste auf das gewünschte Item, um den XPath zu finden.
- Schritt 3: Wählen Sie „inspect“ und dann würden Sie Chrome DevTools sehen.
- Schritt 4: Drücken Sie die rechte Maustaste auf das hervorgehobene Gebiet der Konsole.
- Schritt 5: Gehen Sie zur „Copy“ -> „Copy XPath“
Aber man würde meistens durch „Copy XPath“ einen Absoluten XPath kopieren, wenn es kein Attribut gibt oder das Attribut-value zu lang ist. Sie brauchen wahrscheinlich noch selbst den korrekten XPath schreiben.
XPath Helper
XPath Helper ist ein hervorragendes Plug-in von Chrome, mit dem Sie XPath durch einfaches Schweben nachschlagen können, indem Sie einfach über das Element im Browser fahren. Sie können auch den XPath-Ausdruck direkt in der Console bearbeiten. Sie würden sofort die Ergebnisse bekommen, sodass Sie wissen können, ob Ihr XPath gut funktionieren könnte.
Für mehrere Tutorials über XPath:
- https://www.w3schools.com/xml/xpath_intro.asp
- https://msdn.microsoft.com/en-us/library/ms256086(v=vs.110).aspx
- https://en.wikipedia.org/wiki/XPath
- 3 Minutes to Know – Basic HTML for XPath
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise:Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen:Octoparse für Windows und MacOs
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️




