Daten aus dem Internet zu filtern und für Vergleiche oder Optimierungen der Unternehmensstrategie einzusetzen, ist in heutiger Zeit sehr wichtig. Daten aus dem Internet helfen auch dabei, Preise zu vergleichen, Kundenbewertungen zu analysieren und die Kundenzufriedenheit zu verbessern.
Ein personalisierter Webcrawler ist für diese Zwecke sehr vorteilhaft. Die angebotenen Tools bieten sehr oft nicht den gewünschten Erfolg, wodurch es einfacher ist, selbst einen Webcrawler zu erstellen. Wie Sie mit Octoparse und Python gezielt Daten aus dem Internet crawlen können, wird Ihnen hier erklärt.
Was ist ein Webcrawler und wie funktioniert der?
Webcrawler, auch Suchmaschinen-Bot oder Spider genannt, rufen Daten aus dem gesamten Internet ab. Der Webcrawler erhielt seinen Namen übrigens deshalb, weil der automatische Zugriff mit einer Software auf Internetdaten als “Crawling” bezeichnet wird.
Möglich ist das Crawling, weil es sich bei einem Webcrawler um ein spezielles Softwareprogramm handelt. Es kann Daten abrufen, herunterladen und sogar indexieren. Nutzer von Webcrawlern suchen bestimmte Daten auf öffentlichen Webseiten, um zum Beispiel die Unternehmensstrategie zu optimieren.
Die Betreiber von Suchmaschinen wiederum nutzen Webcrawler um den Internetnutzern rasch die gesuchten Seiten aufzuzeigen. Durch die Eingabe einer Anfrage in die Suchleiste der Suchmaschine werden alle Webseiten mit diesem Inhalt gelistet. Diese Web Crawler durchsuchen das Internet und indexieren für Seiten, um die rasch zur Verfügung stellen zu können.
Suchmaschinen-Indexierung
Der Webcrawler einer Suchmaschine erstellt mit dem Crawling eine Art Katalog über die Webseiten im Internet. Dadurch kann bei einer Suchanfrage rasch und unkompliziert erfolgreich ein Ergebnis präsentiert werden.
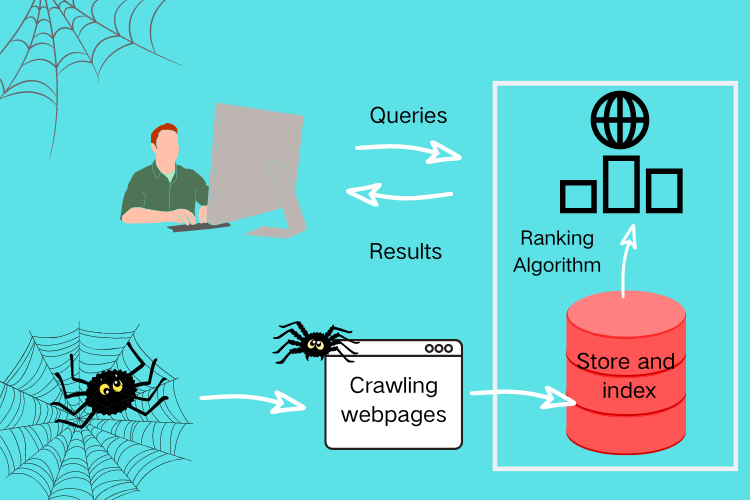
Diese Indexierung ist vergleichbar mit einem Inhaltsverzeichnis in einem Buch. Jedes einzelne Kapitel wird im Buch mit der Seitennummer angezeigt. Der Index der Suchmaschine besitzt ebenfalls eine Indexierung, wodurch der Crawler einfach auf die benötigten Daten zugreifen kann.
Die Indexierung des Suchmaschinen Web Crawler fokussiert übrigens auf den Text und die Meta-Tags von Webseiten, um die Indexierung festzulegen.
Wie funktioniert der Webcrawler?
Das Internet wächst täglich, da laufend neue Webseiten und damit neue Informationen hochgeladen werden. Wie viele Webseiten bestehen, kann dadurch nicht genau gesagt werden. Der Webcrawler benötigt für die Suche einen festgelegten Punkt. Eine oder mehrere URLs. Sobald er beginnt, diese Seiten zu durchsuchen, stößt er auf weitere URLs, die er in einer Liste reiht. Diese Liste wird danach abgearbeitet und neue URLs in die Liste hinzugefügt, bis diese Liste komplett abgearbeitet wurde.
Aufgrund der schier endlosen Webseiten im Internet kann dieser Vorgang unendlich fortgesetzt werden. Der Webcrawler benötigt dadurch festgelegte Richtlinien, um bei der Vorgehensweise selektiv handeln zu können. Wird das Crawling festgelegt, können dem Webcrawler die Reihenfolge der Seiten und wie oft er erneut suchen, vorgegeben werden.
Der Unterschied zwischen Webcrawling und Web-Scraping
Das Web-Scraping ist in der Regel mehr auf ein bestimmtes Ziel ausgerichtet als das Webcrawling. Ein Scraper sucht gezielt nach Webseiten, um die benötigten Daten auszulesen. Der Webcrawler hingegen durchsucht Webseiten und folgt den darin enthaltenen Links, die ebenfalls durchsucht werden.
Weshalb benötigen Sie einen Webcrawler?
Der Webcrawler wird von Innen in der Regel benötigt, wenn Sie Informationen aus dem Internet benötigen. Zum Beispiel wenn Sie ein bestimmtes Rezept aus dem Internet benötigen. Stellen Sie sich vor, wie lange Sie ohne eine Suchmaschine und deren Webcrawler nach dem Rezept suchen würden. Durch rund 2,5 Trillionen Datenbytes, die täglich online gestellt werden, wäre die Suche für Sie wie nach einer Nadel im Heuhaufen.
Daten, die von Ihnen zum Beispiel ausgelesen werden können:
| Produktinformationen | Beschreibungen, Preise und auch Bilder von Produkten |
| Kontaktdaten zur Lead-Generierung | Namen, Telefonnummern, E-Mail-Adressen, |
| Bewertungen und Rezensionen | von Kunden über die Konkurrenz oder über das eigene Unternehmen |
| Blogartikel oder die Headlines der Nachrichten | damit die eigene Werbung rasch angepasst werden oder die Trends rasch erfasst werden können |
| Immobilienangebote | für Immobilienmakler sehr wichtig |
| Daten aus Bildern oder PDFs | diese hilfreiche Möglichkeit steht mittlerweile ebenfalls zur Verfügung |
Suchmaschinen nutzen Webcrawler der Webseiten indizieren kann. Dadurch werden die gesuchten Webseiten sehr schnell gefunden und in den Ergebnissen für Sie gereiht. Sie können sich das Suchen nach Daten jedoch noch mehr vereinfachen. Mit der Erstellung eines individuell an Ihre Bedürfnisse errichteten Webcrawler.
Sie können zum Beispiel drei Arten von Crawler selbst errichten.
| Web Crawler 1: Content Aggregation | Dieser Webcrawler fokussiert auf das Umwandeln von Informationen aus verschiedenen Ressourcen in einer Plattform. Das bedeutet, er durchsucht die beliebtesten Webseiten nach Informationen und verwaltet Ihre Plattform mit den gesammelten Daten. |
| Web Crawler 2: Sentiment Analyse | Jedes Unternehmen benötigt zum Beispiel Sales-Leads. Damit kann es sich weiterentwickeln und überleben. Mit einem spezifischen Webcrawler können etwa Telefonnummern, E-Mail-Adressen, Teilnehmerlisten aus Messeveranstaltungen und mehr aus öffentlichen Webseiten gesammelt werden. |
| Web Crawler 3: Lead Generierung | Diese Art von Webcrawler wird auch als Text Miner oder Text Mining bezeichnet. Der Webcrawler analysiert hier die öffentlichen Bewertungen zu Dienstleistungen oder Produkten. Dabei muss er eine enorme Menge an Daten sammeln, um diese auswerten zu können. Der Crawler kann dabei Bewertungen, Tweets und auch Kommentare für die Analyse auslesen. |
Hinweis: Hier werden die drei gängigsten Varianten aufgezeigt. Jede Branche bzw. jedes Unternehmen hat individuelle Interessen im Bereich der Datenanalyse.
Schritt für Schritt Anleitung für Anfänger, um einen Web Crawler Python zu erstellen
Hier werden zwei unterschiedliche Methoden vorgestellt, um einen Web Crawler Python selbst herzustellen. Mit der Schritt für Schritt Anleitung ist es relativ einfach.
Methode 1: Die Verwendung eines nutzungs-bereiten Web Scraping Tools
Wenn Sie keinen Code lernen möchten, ist ein fertiger Web Crawler die beste Lösung für Sie. Octoparse bietet sich hier zum Beispiel hervorragend an, weil es eine äußerst benutzerfreundliche Oberfläche und vorgefertigte Web Scraping Vorlagen bietet.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Ein Beispiel hierfür:
In diesem Beispiel werden Daten aus den gelben Seiten gesammelt. Es wird ein Web Crawler erstellt, um Leads, Faxnummern, Telefonnummern, Öffnungszeiten, Webseiten, Adressen und andere Daten zu sammeln.
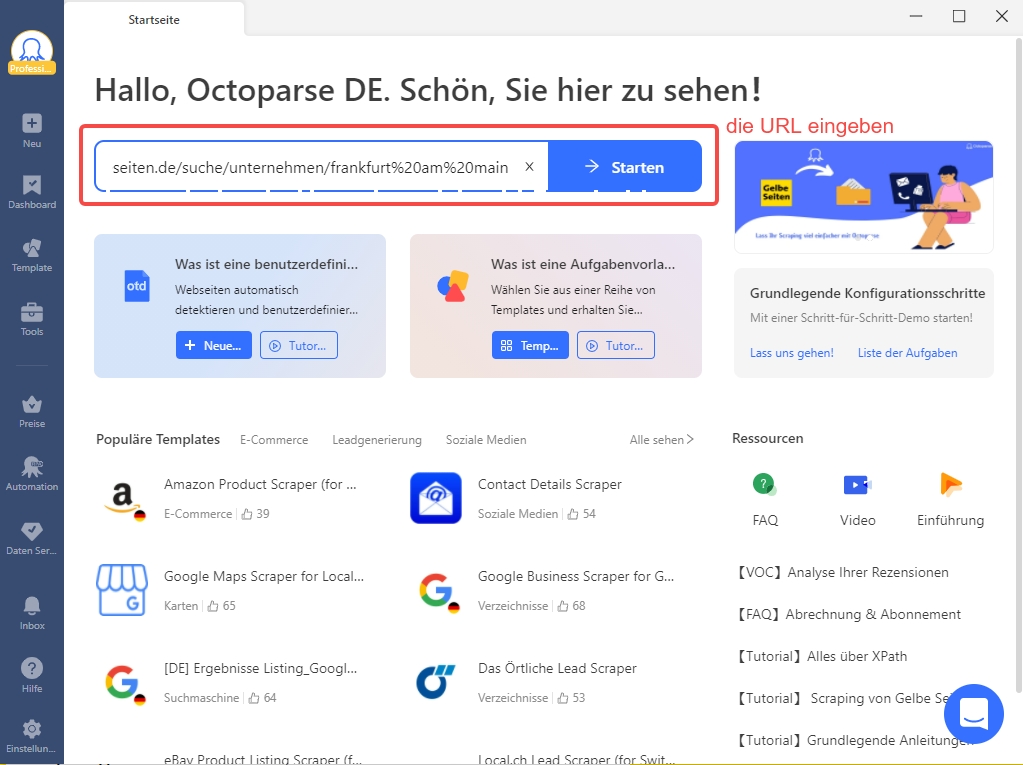
✅ Schritt 1: Octoparse öffnen und eine neue Aufgabe erstellen
Nach dem Öffnen von Octoparse wird die benötigte URL eingegeben, womit eine Aufgabe erstellt wird.
✅ Schritt 2: Das Aufbauen einer Paginierung – die Extraktion der Leads-Daten
Da die Leads-Daten in der Regel mehrere Seiten benötigen, muss eine Paginierung eingerichtet werden. Dafür wird auf der Schaltfläche “Nächste Seite” einmal geklickt. Bei dem sich öffnenden Fenster wird “Schleifenklick auf einzelnes Element” gewählt.
✅ Schritt 3: In die Detailseite gehen und das Element klicken
Damit Sie Detailinformationen zu jedem einzelnen Element der Liste erhalten, muss eine Schleife erstellt werden. Dafür wird das benötigte Element ausgewählt und Octoparse erkennt diese dann automatisch. Das gilt auch für ähnliche Elemente, die sich auf der Seite befinden. Durch das Aktivieren bzw. Klicken auf “Daten der Webseite automatisch erkennen” wird diese Aufgabe erstellt.
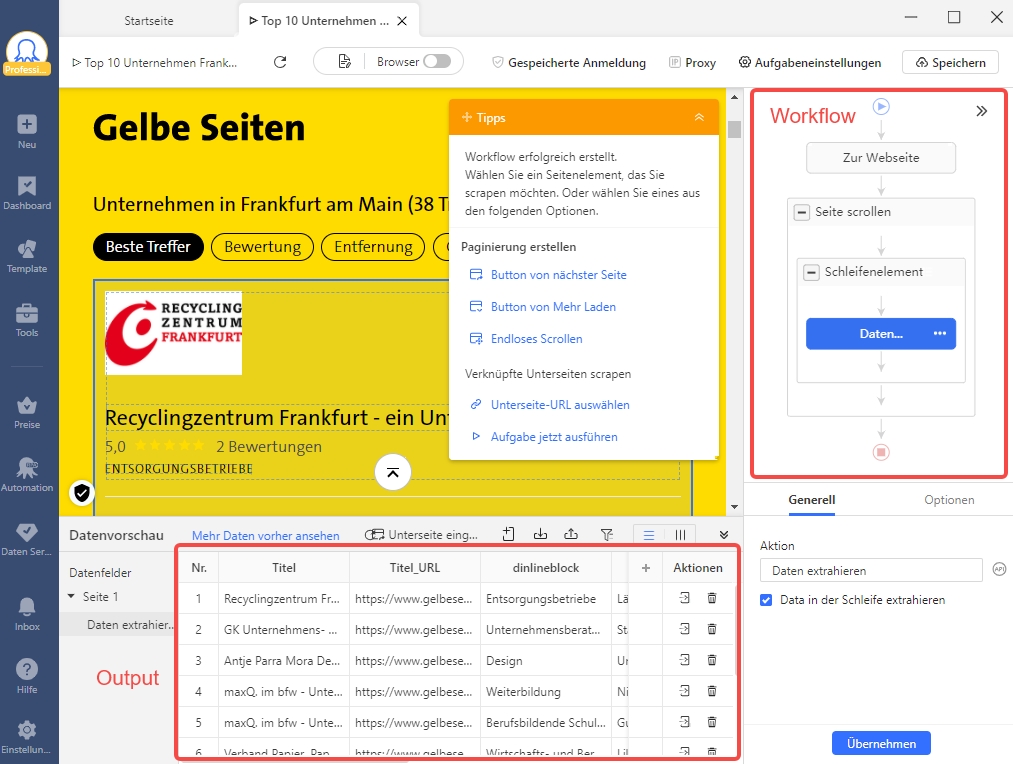
✅ Schritt 4: Daten-Details extrahieren – die benötigten Dateien auswählen
Nachdem Sie die vorhergehenden Schritte ausgeführt haben, finden Sie sich jetzt auf einer Detailseite. Jetzt müssen Sie Octoparse sagen, von wo die Daten ausgelesen werden sollen. Dafür klicken Sie auf “Titel des ausgewählten Elements extrahieren”. Dieser Schritt wird für jeden einzelnen Punkt, etwa Telefonnummer, Öffnungszeiten und weitere durchgeführt. Damit erhalten Sie alle benötigten Daten.
✅ Schritt 5: Ende der Erstellung – Beginn des Aufgabenstart
Haben Sie alle Extraktion-Felder ausgefüllt, können Sie die Ausführungsaufgabe mit “Start Extraktion” beginnen.
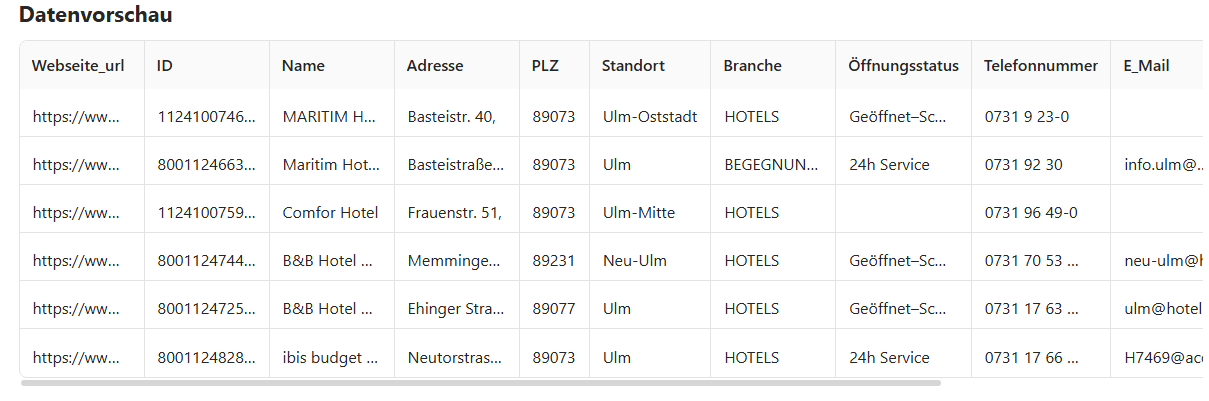
Hinweis: Octoparse bietet Ihnen eine Vorlage für die Gelben Seiten, um Daten auszulesen. Diese Vorlage ist sehr benutzerfreundlich und erleichtert das Web Crawling enorm.
https://www.octoparse.de/template/gelbe-seiten-scraper
Hinweis: Mit einer vordefinierten Vorlage von Octoparse können Daten rasch und einfach extrahiert werden. Einfach die benötigten URLs oder Schlüsselwörter eingeben und los geht’s.
Methode 2: Kodieren und schreiben eigener Skripte lernen
Skripte schreiben mit Programmiersprache wird normalerweise von Programmierern durchgeführt. Der Webcrawler wird dadurch so erfolgreich wie er geschrieben wurde. Im Folgenden ein Beispiel eines Ausschnittes aus einem Bot-Code.
Crawler Programmieren besteht allgemein in drei Hauptschritten:
✅ Schritt 1: Eine Anfrage senden
Sie senden eine Anfrage von http zu einer URL auf einer Webseite. Die Antwort ist die Beantwortung Ihrer Anfrage durch das Anzeigen des Inhaltes der Webseite.
✅ Schritt 2: Die Analyse der Webseite
Sie können jetzt die Webseite analysieren. Bestehen Verflechtungen zwischen mehreren Webseiten wird das durch den Parser angezeigt. Es wird dabei von Parser eine Baumstruktur von HTML aufgebaut. Durch diese Baumstruktur kann der Crawler einem Pfad folgen. Er wird sozusagen navigiert, um die benötigten Daten zu finden.
✅ Schritt 3: Das Einsetzen der Python-Bibliothek um eine Baumstruktur aufzubauen
Bei Python handelt es sich um eine sehr einfache Programmiersprache. Python ist dadurch sehr flexibel und einfach einzusetzen. Einfacher als Java oder PHP. Ein Web Crawler Python muss jedoch erlernt werden, wodurch Menschen mit einem geringen technischen Wissen die Verwendung vermeiden. In den meisten Fällen ist dies der Grund, warum Anfänger diese Variante nicht verwenden.
Hinweis: Die Methode 2 eignet sich besser für Menschen, die bereits Erfahrung im Programmieren haben. Anfänger haben bei dieser Methode einige Herausforderungen zu meistern.
FAQs
Die häufigsten Fragen betreffend eines Webcrawler werden hier kurz und übersichtlich beantwortet. Damit möchten wir Ihnen eine lange Suche für die Beantwortung einer Frage ersparen.
Was ist ein Webcrawler und wofür wird er eingesetzt?
Ein Webcrawler ist eine spezielle Software, die automatisch Webseiten nach Daten durchsuchen kann. Dabei folgt er Links und sammelt Daten von Texten, Metadaten und Bildern. Suchmaschinen nutzen Webcrawler um Webseiten zu Indexieren und das Web bei Anfragen zu durchsuchen.
Was ist der erste Schritt, wenn man einen Web Crawler Python aufbaut?
Normalerweise werden Bibliotheken wie zum Beispiel Requests für die http-Anfragen genutzt. BeautifulSoup wird als Bibliothek für das Parsen eines HTML-Code verwendet. Damit können anschließend die benötigten Webseiten abgerufen und die Inhalte ausgelesen werden.
Benötigt man Kenntnisse für das Crawler Programmieren?
Wenn Sie Octoparse nutzen, benötigen Sie keine Programmiererfahrung. Sie können Octoparse als Tool verwenden, das automatisch die gesuchten Daten erkennt und die Konfiguration dazu kann visuell durchgeführt werden.
Fazit
Skripte für das Crawler Programmieren ist für Menschen, die über keine Programmiererfahrung verfügen, sehr kompliziert. Der Grund ist, dass Webseiten nicht identisch sind und dadurch jede Webseite ein eigenes Skript benötigt.
Mit einem Tool wird Octoparse den Crawler programmieren ohne endloses Lernen von Codes. Die rund 500 fertigen Vorlagen machen das Web Crawling zusätzlich einfacher. Ein Tool zu nutzen ist eine einfache und unkomplizierte Möglichkeit, Daten rasch aus dem Web zu erhalten.
Haben Sie mit Ihrem Webcrawler Probleme, steht Ihnen außerdem ein kompetenter Kundensupport zur Verfügung. Versuchen Sie die 14-tägige Testversion und erstellen Sie Ihren eigenen Web Crawler Python!
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



