Das Internet ist voller Informationen, die sich auf Millionen von Webseiten befinden. Dazu zählen auch Informationen wie Details zu Produkten, die Preisgestaltung der Konkurrenz, Kontaktdaten und Kundenmeinungen. Diese Informationen sind für Unternehmen wichtig, um die eigene Marketingstrategie zu perfektionieren.
Wie kommt man aber an diese Informationen, die sich in den meisten Fällen in Texten befinden? Diese Texte zu suchen, wichtige Informationen mit Klick und Speichern zu sammeln ist sehr mühsam und zeitaufwendig. Ein moderner Web Scraper ist in diesem Fall ein unverzichtbarer Helfer, um rasch einen Text aus Webseite extrahieren zu können. Die folgende Anleitung zeigt Schritt für Schritt, wie man rasch und einfach zu den benötigten Informationen gelangt.
Text aus Webseite extrahieren – was bedeutet das?
Text aus Webseite extrahieren oder kurz Textextraktion genannt ist das Informationen aus Webseiten ziehen. Dabei kann es sich um einen Text, eine Datenbank oder um eine Tabelle handeln. Diese Daten müssen ausgelesen und in einer Datei gespeichert werden, um sie anschließend verarbeiten zu können.
Eines der Probleme beim Text aus Webseite extrahieren ist, dass nicht jeder Text auf jeder Webseite gleich ist. Hier die wichtigsten Unterschiede zum Verständnis:
- sichtbare Inhalte
- Die sichtbaren Inhalte sind Textteile, die man mit der Maus anklicken kann. Dazu gehören Überschriften, der Fließtext, Tabellen, Listen, Beschreibungen von Produkten, Blogartikel, Überschriften und vieles mehr.
- Nicht HTML Texte
- Dabei handelt es sich um Bilder mit Text, PDFs, Word-Dokumente wie zum Beispiel Infografiken oder Verträge, die auf einer Seite enthalten oder aber verlinkt sind.
- versteckte oder strukturierte Daten
- Zu diesen Daten zählen die Metadaten, Informationen, die durch ein JavaScript geladen werden, wenn man scrollt oder klickt und auch JSON-LD-Skripte.
Die Vorteile des Text aus Webseite extrahieren
Zum Spaß Texte aus einer Webseite extrahieren ist sicherlich ein sehr seltsames Vorhaben. Unternehmen hingegen machen es, weil es ihnen Vorteile bietet. Ein Überblick über die Gründe und Vorteile des Text aus Webseite extrahieren:
| Unternehmensbereich | Beispiele der Anwendung | Die Vorteile |
| Marketing | SEO-Daten auslesen, Blogs der Mitbewerber analysieren | Trends entdecken, Lücken im Content finden |
| Vertrieb | Kontaktdaten filtern Verzeichnisse durchsuchen nach Leads | Die Akquise einfacher verbessern |
| Immobilien | Objektdetails sammeln, Exposés erstellen | Generierung von Leads, Marktanalysen |
| Operations | E-Commerce Webseiten und deren Preisgestaltung überwachen, | Lagerbestände einfacher zu kontrollieren, dynamische Preiskontrolle |
| Support | Forenbeiträge und Kundenbewertungen sammeln | frühzeitige Problemerkennung,einfachere Stimmungsanalyse |
Praxisbeispiele zum einfacheren Verständnis:
- Die Wettbewerbsbeobachtung: Ein Einzelhändler kann seinen Umsatz um 3,5 Prozent erhöhen, weil er automatisch die Preisdaten sammelt und entsprechend reagieren kann.
- Die Lead-Generierung: Ein Großhändler für Gemüse kann in sehr kurzer Zeit anstatt von Tagen neue Kontakte herstellen.
- SEO-Datenanalyse: Ein Unternehmensteam sammelt Metadaten, um die Unternehmensstrategie zu optimieren.
Ein Tool für das Text aus Webseite extrahieren kann einem Unternehmen bis zu 40 Prozent Zeit beim Sammeln von Daten einsparen. Verglichen mit der klassischen Datensammelmethode.
Die klassische Methode – Kopieren und Einfügen
Bevor das automatische Text aus Webseite extrahieren näher betrachtet wird kurz noch zu der klassischen Methode ein paar Worte. Die klassische Methode ist, wie in der folgenden Beschreibung deutlich erkennbar, äußerst zeitaufwendig.
Die unterschiedlichen manuellen Text-Extraktion-Methoden:
1. Kopieren und danach Einfügen
Die Webseite öffnen und den benötigten Text mit Strg+C markieren (funktioniert auch mit dem Rechtsklick und dem Klick auf kopieren), danach wird der kopierte Text in eine Tabelle oder ein Dokument eingefügt.
2. Die Seite speichern unter
Im Browser kann unter “Datei -> Seite” gespeichert werden. Bei dem Begriff “Webseite nur HTML” erhält man den Quellcode angezeigt. Manchmal geschieht das nur durch die Anzeige .txt und man erhält nur den Text.
3. Das Drucken als PDF
Mit der Funktion Drucken im Browser unter dem Punkt “als PDF speichern” erfolgt das einfache Speichern des Textes. Der gespeicherte Text kann danach aus dem PDF kopiert werden. Man kann jedoch auch mit einem PDF-Reader den Text speichern.
4. Die Entwicklertools
Bei einem Entwicklertool kann durch das Drücken von F12 oder Rechtsklick > Untersuchen das DevTool geöffnet werden. Wird es geöffnet, findet man die Meta-Tags, den HTML-Quelltext oder die versteckten JSON-Daten, die man einfach kopieren kann.
Die manuellen Methoden und ihre Grenzen
Bei sehr kleinen Aufgaben sind die manuellen Methoden vollkommen ausreichend. Benötigt man größere Datenmengen, kann sich diese Aufgabe über Tage und Wochen hinziehen. Man stelle sich einfach vor, man müsste aus hundert Webseiten Zeile für Zeile aus Texten kopieren und in eine Tabelle einfügen. Diese Aufgabe ist nervenzerreißend.
Online-Tools und Browser-Erweiterungen für das Text aus Webseite extrahieren
Online Tools wie zum Beispiel Octoparse oder Browser Erweiterungen eignen sich hervorragend, um einen Text aus Webseite extrahieren zu können. Sie arbeiten rasch und zuverlässig. Außerdem ist keine Programmierung notwendig. Einfach öffnen, Angaben über die benötigten Daten eingeben und starten.
Schritt für Schritt Anleitung für das Text auslesen mit Octoparse
Eine Anleitung, um es auch für Anfänger leichter macht, Daten aus Webseiten rasch und zuverlässig auszulesen. In dieser Anleitung wird Schritt für Schritt erklärt, wie man rasch zu dem benötigten Text und seinen Informationen gelangt.
- Octoparse aufrufen
- Im Suchfeld die URL der benötigten Webseite eingeben und den “Start”-Button klicken.
- Die “Auto-detect webpage data”-Funktion anklicken
- Wenn die Auto-Detect-Funktion fertig gemacht wurde, wird mit einem Klick auf “Create Workflow” die Aufgabe erstellt.
- Die Aufgabe für das Tool erstellen, um Daten auszulesen. Der Workflow kann am rechten Bildschirmrand kontrolliert werden. Gegebenenfalls können über das Vorschaufenster Daten entfernt oder umbenannt werden.
- Die Aufgabe über Cloud oder auf dem Computer ausführen.
- Ist die Aufgabe abgeschlossen, kann man die ausgelesenen Daten beliebig in Excel, HTML, CSV oder JSON speichern.
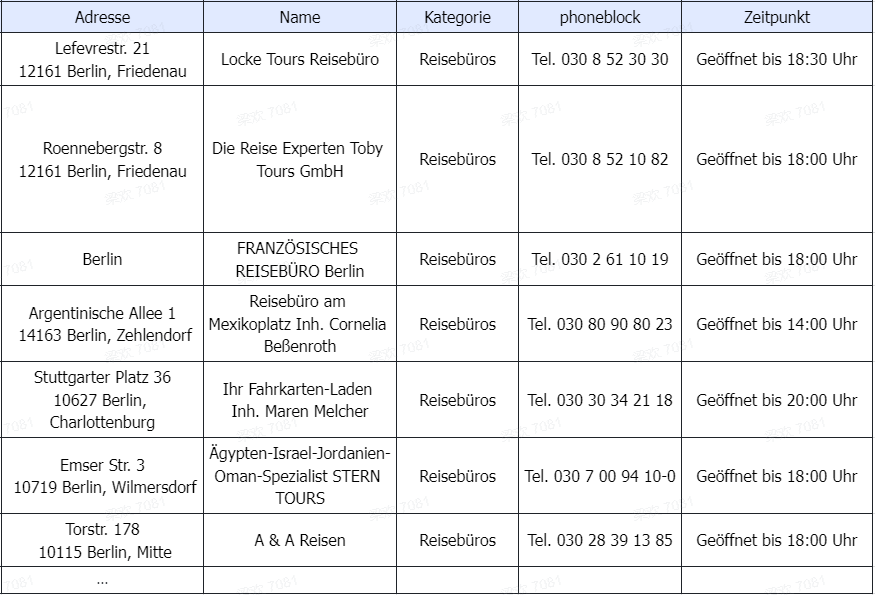
Zusammenfassend kann gesagt werden: Einige wenige Eingaben und man erhält in kurzer Zeit die benötigten Daten aufgelistet. Der Vorteil eines spezialisierten Werkzeugs ist hier sehr deutlich erkennbar. Die wichtigsten Vorteile in einem Überblick zusammengefasst:
- man benötigt keine Programmierkenntnisse
- einfacher und schneller als die klassische Methode
- man kann Listen, Tabellen und auch Dateien verarbeiten
- die Daten können beliebig in Google Sheets, Excel, CSV und weitere exportiert werden
Es finden sich noch weitere Vorteile, die für den Einsatz eines spezialisierten Tools für das Text aus Webseite extrahieren nennen lassen.
Die Text aus Webseite extrahieren Methoden im Vergleich
Ein Vergleich der unterschiedlichen Methoden zum Text aus Webseite extrahieren hier in einem zusammenfassenden Überblick.
1. Manuelle Methode:
a. sehr einfach durchzuführen
b. die Skalierbarkeit ist sehr gering
c. technisches Wissen nicht erforderlich
d. nur sichtbarer Text kann ausgelesen werden
e. eignet sich für kleine Aufgaben
2. Browser Erweiterungen und Tools
a. einfach anwendbar
b. Skalierbarkeit liegt im mittleren Bereich
c. technisches Verständnis hilfreich
d. eignet sich für HTML und Tabellen
e. kleine bis mittlere Aufgaben können erledigt werden
3. KI unterstützte Tools wie zum Beispiel Octoparse
a. sehr einfach zu bedienen
b. hohe Skalierbarkeit
c. kein technisches Wissen erforderlich
d. eignet sich für Bilder, HTML, PDFs und einiges mehr
e. eignet sich für gemischte Aufgaben und Anwender Aus dem Business Bereich
4. Nicht HTML
a. Bedienung liegt im mittleren Bereich
b. Skalierbarkeit ist sehr gering bis mittel
c. technisches Wissen sollte vorhanden sein
d. eignet sich für Dokumente, Bilder, PDFs und mehr
e. besonders gut geeignet wenn Bilder und Dateien ausgelesen werden sollen
5. Programmierung
a. schwierig anzuwenden
b. Skalierbarkeit ist der hoch
c. technisches Wissen und Verständnis muss vorhanden sein
d. alles kann mit der passendem Bibliothek ausgelesen werden
e. eignet sich für Großprojekte und Entwickler
Zusammenfassend kann festgestellt werden, dass, wenn eine flexible und rasche Lösung gesucht wird, Octoparse eine sehr gute Wahl ist. Octoparse bietet die Möglichkeit auch große Datenmengen auszulesen in ganz kurzer Zeit. Außerdem sind keine Programmierungskenntnisse notwendig, um das Tool benutzen zu können.
Fazit
Das Internet enthält unzählige äußerst wertvolle Textdaten. Diese Daten zu finden und auszulesen ist aber nicht einfach. Die manuellen Methoden benötigen sehr viel Zeit und sind daher nur für kleine Aufgaben geeignet. Web Scraper und Browser-Erweiterungen hingegen vereinfachen das Text aus Webseite extrahieren um ein Vielfaches. Sie arbeiten nicht nur schnell, sondern auch sehr genau. Tools wie zum Beispiel Octoparse können ohne Kenntnisse im Programmieren einfach eingesetzt werden.
Die Erkenntnis nach dem Einsetzen eines spezialisierten Tools ist, weg von Strg+V und Tools verwenden. Man spart Zeit und kann damit sein Unternehmen Up to date halten. Der Konkurrenz-Wettbewerb ist einfacher zu bestehen, wenn man immer die aktuellsten und wichtigsten Daten zur Hand hat. Automatisch benötigten Text aus Webseite extrahieren bedeutet, effizient, smart und zukunftsorientiert seine Aufgaben zu erledigen.
FAQs
Zum Text aus Webseite extrahieren und dem Einsetzen von Tools entstehen immer wieder die gleichen Fragen. Die häufigsten werden hier aufgezeigt.
Arbeitet ein Tool zum Text aus Webseite extrahieren genau?
Web Scraper wie zum Beispiel Octoparse arbeiten sehr genau und zuverlässig. Das gilt auch dann, wenn es sich um dynamische oder sehr komplexe Webseiten handelt. Es kann jedoch hin und wieder eine Nachbearbeitung notwendig sein.
Kann man von jeder beliebigen Webseite Text extrahieren?
Nicht jede Webseite lässt das Text extrahieren zu. Einige Webseitenbetreiber verbieten zum Beispiel das Extrahieren von Daten. Ob es erlaubt ist Daten auszulesen kann man auf jeden Fall in den Nutzungsbedingungen der Website nachlesen.
Benötigt man Programmierkenntnisse um Octoparse anzuwenden?
Allgemein kann gesagt werden, dass die meisten angebotenen Online Tools keine Programmierungskenntnisse voraussetzen. Das gilt auch für Octoparse. Diese Tools sind so konzipiert, dass auch Anfänger einfach einen Text aus Webseite extrahieren können.
Octoparse kann zudem als KI-gestützter Web Scraping Assistent dienen. Web Scraping Tool Free/kostenlos ist mit Octoparse 14 Tage möglich. Testen Sie das Web Scraping Tool noch heute!
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



