CAPTCHAs sind eine der beliebtesten Anti-Scraping-Techniken, die von Website Besitzern implementiert werden. Manchmal werden wir während des Anschauen von den Websites mit diesen Satz konfrontiert sein: Ich bin kein Roboter. reCaptcha v3 ist eine CAPTCHA-Integrationslösung von Google, um den Besucherverkehr der Roboter zu erkennen und sie abzufangen. NuCaptcha, hCaptcha sind einige andere fortschrittliche CAPTCHA-Lösungen. Aber CAPTCHAs sind ziemlich irritierend, nicht nur für Benutzer*innen, sondern auch für Web-Scraper. Die Lösungen von CAPTCHA ist eine der größten Herausforderungen für Web-Scraper. Während Sie den Inhalt Ihrer Zielwebsite scrapen, können Sie diesen Artikel lesen, um „Ich bin kein Roboter“ zu umgehen oder zu deaktivieren, und beim Web Scraping verschiedene Methoden zur Lösung von CAPTCHAs zu finden.
Was ist CAPTCHA? Und was ist reCaptcha?
Die gemeinsame CAPTCHA-Bedeutung ist Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA), was ein automatisch algorithmusgenerierter textueller, visueller oder audiobasierter Test ist. Heutzutage verwenden die meisten Webseiten diese Technik, um die reale Menschen und Bots zu unterscheiden. Die Lösung von CAPTCHAs erfordert drei Fähigkeiten, welche die Menschen viel besser als Computer gut können:
- Invariante Erkennung (Identifizieren verschiedene Formen, Bilder desselben Alphabets, Objekt);
- Segmentierung (Identifizieren überlappender Alphabete);
- Analyse vom Zusammenhang (Umfassendes Verständnis von Bild, Text oder Audio)
reCaptcha ist die beliebteste CAPTCHA-Art. Es stammt von Google und kann leicht in eine Website integriert werden.
Populäre Arten von CAPTCHAs
Es gibt unterschiedliche Arten von CAPTCHAs im Internet. Hier würde ich Ihnen einige populärste Arten von CAPTCHAs vorstellen.
1. Normale CAPTCHAs
Dies ist der am weitesten verbreite CAPTCHA, bei dem ein verzerrtes Bild Text enthält, aber von Menschen gelesen werden kann. Sie müssen den verzerrten Text in das Textfeld genau eingeben, um normalen CAPTCHAs zu lösen.
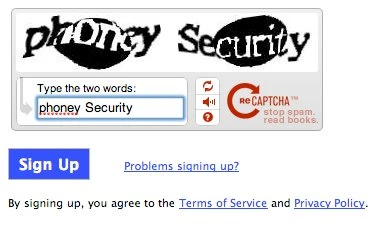
2. Textbasierte CAPTCHAs
TextCaptcha ist nicht so beliebt, aber er ist gut geeignet für sehbehinderte Benutzer*innen. Dieser Captcha basiert nicht auf ein Bild, sondern reiner Text ist. Folgend ist ein CURL-Beispiel von TextCaptcha:
CAPTCHA: If tomorrow is Saturday, what day is today?
Lösung: Friday.
3. Key-CAPTCHAs
KeyCAPTCHA ist ein anderer CAPTCHA-Integrationsdienst, mit dem Sie ein Puzzle erledigen sollen.

4. Klick-CAPTCHAs
Bildbasierte CAPTCHAs, die zu klassifikation-basierten Probleme zählen, stellen Klick-CAPTCHAs dar. reCaptcha, ASIRRA, Snapchat’s Ghost Captcha sind beliebte Beispiele von klassifikation-basierten Klick-CAPTCHAs.
5. Gedrehte CAPTCHAs
Diese sind CAPTCHA-Puzzles, die auf der Bildorientierung basieren. Wenn Sie mit gedrehten CAPTCHAs konfrontiert sind, müssen Sie einmal oder mehrmals klicken, um das Bild zu drehen, bis es die Verifizierungsbedingungen erfüllt. Das beliebteste Verifizierungsbedingung ist, ein Objekt „right way up“ zu machen. FunCaptcha ist einer der Integrationsanbieter von Gedrehtem CAPTHCA. Aber er schien zusammengebrochen zu sein. RVerify.js ist eine Open-Source- Programmbibliothek von Javascript zur Verifizierung der Bildorientierung.
6. GeeTest-CAPTCHA
GeeTest CAPTCHAs sind interessant. Hier müssen Sie ein Teil des Puzzles bewegen, normalerweise durch Ziehen des Schiebereglers. Oder müssen Sie bestimmte Bilder in einer bestimmten Reihenfolge auswählen.
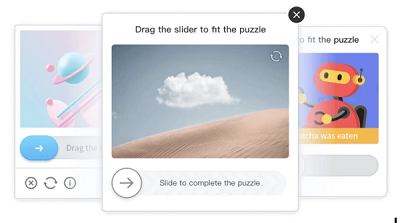
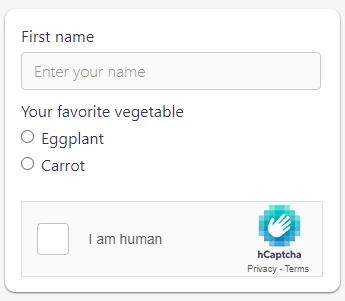
7. hCaptcha
hCaptcha ist sehr ähnlich wie reCaptcha. Der einzige Unterschied ist, dass einige Unternehmen die Vorteile des Datenlabel nutzen können, die Benutzer auf Websites während der Klicks machen, wenn wir hCaptcha verwenden. Mit reCaptcha profitiert nur Google von der crowdsourcing Datenlabel.
8. Capy Puzzle
Es ist keyCaptcha ähnlich. Capy Puzzle ist ein puzzle-basierter CAPTCHA Dienst. CAPY:ME ist ein Service zur Integration von Copy Puzzle in Websites.
Wie lösen Sie reCAPTCHAs beim Data Scraping?
Egal ob Sie mit einem fortschrittlichen „click and scrape“ Screen-Scraping-Tool, das keine Kodierung hat, oder Ihrem Scraper scrapen, der Sie in Python, Java oder Javascript geschrieben haben, ist es möglich, alle Arten von CAPTCHAs zu lösen und zu umgehen. Obwohl kein Service/keine Lösung eine 100% CAPTCHA-Lösungsrate garantieren kann, können wir mit beliebten Tools wie DeathByCaptcha und 2captcha usw. die Effizienz von bis zu 90% erreichen.
Hier sind 2 beliebte Methoden zur Lösung von CAPTCHAs.
Mensch-basierte Captcha-Lösung
CAPTCHAs sind gemacht, um von Menschen gelöst zu werden. Einige Unternehmen Tausende von Mitarbeitern mit einem günstigen Preis beschäftigen, um diese CAPTCHAs in Echtzeit zu lösen. Die Effizienz ist ziemlich hoch, aber Zeitverzögerung ist ein Problem mit dieser Methode.
Also, wie sollen Sie CAPTCHA-Lösungsdienst beim Scraping verwenden?
Es gibt einige Dienstleister von CAPTCHA-Lösung auf dem Markt. Einige bemerkenswerte Anbieter sind:
✅ DeathByCaptcha
✅ AZCaptcha
✅ ImageTyperZ
✅ EndCaptcha
✅ BypassCaptcha
✅ CaptchaTronix
✅ AntiCaptcha
✅ 2Captcha
✅ CaptchaSniper
Alle diese Dienstleister werden eine ähnliche Methode anwenden:
- Registrieren Sie auf ihrer Website, erhalten Sie ein Token und Credentials, dann bezahlen Sie den Betrag. Oder wenn eine
- Implementieren Sie ihre API/Plugin mit Ihrer ausgewählten Sprache, d. h. Python, PHP, Java, JS usw.
- Senden Sie Ihre CAPTCHAs an ihre APIs.
- Erhalten Sie die gelösten CAPTCHAs in API-Antwort.
Mit OCRs zur CAPTCHAs-Lösung
Dies ist eine programmatische Methode zur Lösung von CAPTCHAs. OCR steht für Optical Character Recognition oder Optical Character Reader. OCR ist eine elektronische oder mechanische Methode zur Umwandlung von getipptem, handgeschriebenem oder gedrucktem Text in maschine-kodierten Text. Sie können ein gescanntes Dokument, ein Bild oder eine Szene (Beispiel: Plakatwand) in OCRs eingeben. Es gibt Open-Source-Tools wie TESSERACT, GOCR, OCRAD usw. Diese können Ihnen helfen, damit Sie nicht von vorn anfangen müssen. OCRs können verschiedene Arten von bildbasierten CAPTCHAs erfolgreich lösen.
Selbst-Lösung
Wenn Sie eine einzelne Website scrapen, die gelegentlich echte Benutzer*innen mit reCAPTCHAs überprüft, möchten Sie vielleicht reCAPTCHA manuell umgehen. In diesen Fall können Sie Ihren Scraping Workflow wie folgt konfigurieren:
1. Testen Sie reCAPTCHA, und während Sie CAPTCHA lösen:
- Pausieren Sie Scraping für eine bestimmte Zeit, zum Beispiel 7-8 Sekunden oder
- Warten Sie, bis das Element auf der Seite sichtbar ist, oder
- Warten Sie auf Ihre Eingabe, bis sie wieder zu scrapen beginnt
2. Lösen Sie Captcha und beginnen Sie Ihr Scraping wie gewöhnlich.
Um reCaptcha zu testen, ist es wichtig, ihre Implementierung zu verstehen.
Wie wird reCaptcha in Websites integriert?
Die Integration von reCaptcha umfasst die folgenden Schritte:
✅ Schritt 1: Laden Sie Javascript API.
✅ Schritt 2: Rufen Sie eine Funktion auf, um den Rückruf zu verarbeiten und den an ein Button oder eine Aktion zu binden.
Funktion:
Wenn Sie jetzt Captcha testen möchten, verwenden Sie XPaths und testen Sie reCaptcha, indem Sie nach dem Element mit Klassentext suchen, der reCaptcha enthält.
Wenn ein Element existiert, bedeutet das, dass es ein Captcha auf der Seite gibt, das gelöst werden sollte. Sie können Ihren Scraper pausieren und Captcha lösen. Nachdem es gelöst ist, können Sie die Daten wieder extrahieren.
Nächste werden wir sehen, wie Sie ReCaptcha in Octoparse lösen.
Wie gehen Sie reCaptcha in Octoparse um?
Was ist Octoparse?
Wie zuvor erläutert, können Sie Webseiten mit Klick-und-Scraping-Lösungen ohne Kodierung scrapen. Octoparse ist ein Web Scraping Tool ohne Kodierung, das zu einer der Marktführer zählt. Es ist kostenlos, diese Software herunterzuladen und darin die Webdaten zu scrapen.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Für skalierbares Scraping mit hoher Geschwindigkeit bietet Octoparse auch verschiedene bezahlbare Pläne, die Sie nach Bedarf auswählen können. Wenn Sie neu in Octoparse sind, können Sie hier großartige Ressourcen finden. Wenn Sie mit Octoparse vertraut sind, können Sie im folgenden Artikel erfahren, wie Sie CAPTCHAs in Octoparse lösen:
1. Lokale Datenextraktion
Wenn Sie Octoparse verwenden, um die Webdaten auf Ihrem lokalen Computer zu scrapen, wird es empfohlen, dass die Funktionen „Wait before action“ zu verwenden, die unter den fortgeschrittenen benutzerdefinierten Optionen des Octoparse Scraping Workflows bietet werden. Dies hilft Ihnen dabei, dass Sie während des Scraping Zeit gewinnen. In dieser Zeit sollen Sie zuerst auf den „Show Browser“ Button klicken und dann manuell den CAPTCHA lösen. Oder wir bieten jetzt auch CAPTCHA-Lösungsdienst an, mit dem Sie einfach CAPTCHAs lösen können.
2. Cloud-Datenextraktion
Für große Projekte bietet wir auch verwaltete Vorlagen/Crawler-Anpassungsdienste an. Wenn Sie sich für das Service interessieren, kontaktieren Sie uns durch E-Mail.
Tipps zur Verhinderung des Stören von CAPTCHAs
1. Verwenden Sie rotierende IP-Proxys, rotieren Sie Benutzeragenten und reinigen Sie Ihre Cookies.
Octoparse bietet Ihnen diese Optionen, diese zu konfigurieren. Wenn dieselbe IP normalerweise beginnt, die Servers aktiv anzugreifen, löst die Website einen integrierten Anti-Scraping Test Service aus. Wenn Sie Tausende von Proxies verwenden und sie ständig drehen, können Sie vielleicht CAPTCHAs umgehen.
2. Gehorchen Sie Robots.txt File.
Das File enthält die Regeln für Präferenz der Website, beispielsweise werden die Regeln erklären, ob die Website Data Scraping zulässt. Wenn ja, würden Sie nicht zulassen, diese URL zu scrapen.
3. Wenn Sie Ihren Web-Scraper erstellen, verwenden Sie Headless-Browser. Tools wie Octoparse kann automatisch einige CAPTCHAs lösen, da sie intelligente Browser sind.
4. Wenn Sie keinen Full-Scale Browser verwenden, versuchen Sie, Header und Referrers in Ihren Anordnungen an den Server zu verwenden.
5. Zum Scraping von den Daten, die nach dem Einloggen angezeigt werden, brauchen Sie die Speicherung von Cookies. In unserem Tutorial können Sie die detaillierte Anleitung finden.
6. Beachten Sie unsichtbare Honeypot-Fallen auf den Websites. Dies sind die Elemente oder Links, die unsichtbar sind. Wenn Sie also einen Crawler geschrieben haben, der diese Links scrapt, erfährt die Website, dass es ein Roboter ist. Weil Menschen auf diesen Link mit einem normalen Browser wie Chrome oder Firefox nicht klicken können.
7. Behalten Sie zufällige Verzögerungen zwischen ständigen Anordnungen bei. Vor allem, wenn Sie wiederholt Websites mit derselben IP-Adresse besuchen.
8. Verwenden Sie die CAPTCHA-Lösungsdienste von Octoparse.
Zusammenfassung
Scraping der Websites zur Datenextraktion ist für Unternehmen sehr wichtig, um Einblick zu gewinnen und datengesteuerte kritische Geschäftsentscheidungen zu treffen. Webdaten sind auch ganz bedeutend für Trainieren der Maschine, die Algorithmus lernen kann. In diesem Artikel haben wir verschiedene Arten von CAPTCHAs gefunden, verschiedene Methoden zur Lösung von reCaptcha entdeckt, CAPTCHAs verhindert und auch über die Lösung von CAPTCHAs in Octoparse gesprochen. Ich möchte Sie daran erinnern, dass wir außer Vorlagen und Erstellung des Web Crawler auch für große Projekte benutzerdefinierten Vorlagendienst mit Javascript anbieten, um Top CAPTCHA-Service in Octoparse zu integrieren. Bei alle Scraping-Bedarf wenden Sie sich bitte an unser Team. Viel Spaß beim freiem CAPTCHA Scraping!
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬




