Das Umgehen von CAPTCHA-Herausforderungen ist eine wichtige Aufgabe für alle, die mit Web-Scraping beschäftigt sind, da es eine reibungslose Datenerfassung ohne Unterbrechungen gewährleistet. Viele Websites, darunter E-Commerce-Riesen wie Amazon, verwenden häufig CAPTCHA-Mechanismen, um ihre Inhalte vor Bots zu schützen.
Glücklicherweise gibt es mehrere Tools, die das Umgehen von CAPTCHAs ermöglichen, von automatisierten Scraping-Tools über Python-Bibliotheken bis hin zu Browser-Erweiterungen.
In diesem Artikel stellen wir 10 empfohlene Tools vor, die Ihnen helfen können, CAPTCHAs einfach zu umgehen und Ihren Web-Scraping-Prozess zu optimieren.
Warum CAPTCHAs beim Web-Scraping umgehen
Das Lösen von CAPTCHAs ist ein wesentlicher Bestandteil des Web-Scrapings, insbesondere beim Umgang mit Websites, die diese Sicherheitsmechanismen einsetzen, um Bots und automatisierte Datenextraktion zu blockieren. Hier ist, warum das Umgehen von CAPTCHAs für das Web-Scraping entscheidend ist:
Schnellere Datenerfassung
CAPTCHA verlangsamt das Scraping, erfordert manuelle Eingriffe und verursacht Verzögerungen. Das Umgehen ermöglicht eine schnellere, automatisierte Datenextraktion.
Scraping automatisiert halten
CAPTCHA unterbricht den automatisierten Charakter des Web-Scrapings. Das Umgehen gewährleistet eine kontinuierliche, manuelle Datenerfassung.
Groß angelegtes Scraping bewältigen
Beim Scraping großer Datensätze wird die manuelle Handhabung von CAPTCHAs unpraktisch. Das Umgehen ermöglicht skalierbare Scraping-Operationen.
Echtzeit-Daten erhalten
CAPTCHA verzögert die Datenerfassung und beeinträchtigt die rechtzeitige Entscheidungsfindung. Durch das Umgehen erhalten Sie Echtzeit-Zugang zu Daten ohne Unterbrechungen.
IP-Sperren vermeiden
CAPTCHA-Herausforderungen führen oft zu IP-Sperren. Das Umgehen hilft, einen reibungslosen Scraping-Prozess aufrechtzuerhalten, ohne das Risiko von Sperren.
Das Umgehen von CAPTCHAs gewährleistet eine schnellere, skalierbare und effizientere Datenextraktion und hilft Unternehmen, in wettbewerbsintensiven Märkten die Nase vorn zu behalten.
10 Tools to Bypass CAPTCHA for Web Scraping
1. Octoparse
Octoparse ist ein leistungsstarkes, benutzerfreundliches Web-Scraping-Tool, das CAPTCHA-Herausforderungen automatisch bewältigt und es Benutzern ermöglicht, Daten von CAPTCHA-geschützten Websites zu extrahieren. Dieses Tool verwendet fortschrittliche Algorithmen, um CAPTCHAs zu umgehen und Scraping-Unterbrechungen zu verhindern, was es sowohl für Anfänger als auch für fortgeschrittene Benutzer ideal macht.
Mit Funktionen wie Proxy-Rotation und cloudbasiertem Scraping gewährleistet Octoparse eine effiziente, ununterbrochene Datenextraktion, auch von CAPTCHA-geschützten Websites wie Amazon.
2. 2Captcha
2Captcha ist einer der beliebtesten CAPTCHA-Lösungsdienste und nutzt menschliche Mitarbeiter, um CAPTCHA-Herausforderungen in Echtzeit zu lösen. Es ist eine großartige Option, die in Ihren Scraping-Prozess integriert werden kann, um CAPTCHAs zu umgehen, die Ihren Bot stoppen könnten. Bei der Verwendung von 2Captcha senden Sie das CAPTCHA an deren Plattform, und ein menschlicher Mitarbeiter löst es für Sie. Dieser Dienst ist mit den meisten Scraping-Tools kompatibel, einschließlich Octoparse und Python-basierten Methoden.
Hauptmerkmale:
- Echtzeit-CAPTCHA-Lösung durch Menschen.
- Integration mit Web-Scraping-Tools.
- Löst verschiedene Arten von CAPTCHAs, einschließlich reCAPTCHA und bildbasierter CAPTCHAs.
3. Anti-Captcha
Anti-Captcha ist ein CAPTCHA-Lösungsdienst ähnlich wie 2Captcha und bietet eine automatisierte Lösung zum Lösen von CAPTCHAs mithilfe von sowohl Bots als auch menschlichen Mitarbeitern. Anti-Captcha unterstützt reCAPTCHA, FunCaptcha und andere gängige Typen. Es kann problemlos in Ihren Scraping-Prozess integriert werden und gewährleistet eine ununterbrochene Datenextraktion, auch wenn CAPTCHAs erscheinen.
Hauptmerkmale:
- Unterstützt mehrere CAPTCHA-Typen.
- Integration mit verschiedenen Scraping-Tools.
- Schnelle Reaktionszeit und zuverlässiger Service.
4. Selenium with Python
Selenium ist ein Python-basiertes Browser-Automatisierungstool, das echtes Benutzerverhalten simulieren kann. Es wird häufig zum Umgehen von CAPTCHAs verwendet, da es mit der Webseite genauso interagiert wie ein Mensch, wodurch die Wahrscheinlichkeit einer Sperrung verringert wird. Durch die Integration von Selenium mit CAPTCHA-Lösungsdiensten von Drittanbietern wie 2Captcha oder Anti-Captcha können Sie das Lösen von CAPTCHAs automatisieren und das Scraping von Daten ohne Unterbrechungen fortsetzen.
Hauptmerkmale:
- Automatisiert Browser-Aktionen wie Klicken, Tippen und Navigation.
- Integration with CIntegration mit CAPTCHA-Lösungsdiensten zur Automatisierung.
- Geeignet für die Handhabung dynamischer Inhalte und CAPTCHA-Herausforderungen.
5. Bright Data (früher bekannt als Luminati)
Bright Data bietet ein großes Proxy-Netzwerk mit der Möglichkeit, IP-Adressen zu rotieren, was Ihnen hilft, beim Scraping von Websites unentdeckt zu bleiben. Bright Data kann dabei helfen, CAPTCHAs zu umgehen, indem es menschliches Surfverhalten nachahmt und rotierende Proxys verwendet, die die Wahrscheinlichkeit verringern, von Websites markiert oder gesperrt zu werden. Dieses Tool ist besonders hilfreich für groß angelegte Web-Scraping-Aufgaben.
Hauptmerkmale
- Rotierendes Proxy-Netzwerk.
- Echtzeit-Datenextraktion.
- Vermeidet IP-Sperren und CAPTCHA-Erkennung.
6. DataMiner (Chrome-Erweiterung)
DataMiner ist eine Chrome-Erweiterung, die Benutzern dabei helfen soll, Daten von Websites zu scrapen, ohne Code schreiben zu müssen. Es verfügt über integrierte Unterstützung zum Umgehen von CAPTCHAs und hilft mit Proxy-Verwaltung dabei, Sperren beim Scraping zu vermeiden. DataMiner ist ideal für nicht-technische Benutzer und kann verwendet werden, um Daten von einer Vielzahl von Websites zu extrahieren, einschließlich solcher, die durch CAPTCHAs geschützt sind.
Hauptmerkmale
- Zeigen-und-Klicken-Oberfläche für einfache Bedienung.
- Unterstützt CAPTCHA-Umgehung mit Proxy-Unterstützung.
- Kann Daten in Excel, CSV oder andere Formate exportieren.
7. ProxyMesh
ProxyMesh ist ein Proxy-Dienst, der es Benutzern ermöglicht, IP-Adressen beim Scraping zu rotieren und so CAPTCHA-Mechanismen zu umgehen. Durch die Verwendung rotierender Proxys stellt ProxyMesh sicher, dass die Scraping-Aktivität auf mehrere IPs verteilt wird, was es für Websites schwieriger macht, Ihre Scraping-Bemühungen zu erkennen und zu blockieren. Es ist ein wertvolles Tool zur Skalierung Ihrer Scraping-Operationen und zur Bewältigung von CAPTCHA-Herausforderungen.
Hauptmerkmale:
- Rotierendes Proxy-Netzwerk für mehrere IP-Adressen.
- Verhindert CAPTCHA-Auslöser und IP-Sperren.
- Hohe Skalierbarkeit für groß angelegte Datenextraktion.
8. Web Scraper (Chrome-Erweiterung)
Web Scraper ist eine weitere beliebte Chrome-Erweiterung für Web-Scraping. Es bietet Benutzern eine einfache Zeigen-und-Klicken-Oberfläche zum Erstellen von Sitemaps für das Scraping von Websites. Um CAPTCHA-Herausforderungen zu umgehen, kann Web Scraper in Kombination mit Proxy-Netzwerken und CAPTCHA-Lösungsdiensten verwendet werden. Es ist ideal für Benutzer, die ein leichtgewichtiges, einfach zu bedienendes Tool zum Scraping suchen.
Hauptmerkmale:
- Chrome-Erweiterung für einfache Einrichtung.
- Unterstützt Proxy-Integration zur CAPTCHA-Umgehung.
- Ermöglicht den Datenexport in CSV oder JSON.
9. Distill.io (Chrome-Erweiterung)
Distill.io ist eine Browser-Erweiterung, die automatisiertes Web-Scraping ermöglicht. Sie umfasst Funktionen zum Lösen von CAPTCHAs durch die Verwendung von Proxy-Netzwerken und CAPTCHA-Lösungsdiensten. Sie ist besonders nützlich für die Überwachung von Änderungen auf Websites und das Umgehen von CAPTCHA-Herausforderungen während der Datenerfassung.
Hauptmerkmale:
- Echtzeit-Web-Scraping und -Überwachung.
- Integration mit CAPTCHA-Lösungsdiensten.
- Unterstützt Proxy- und IP-Rotation.
10. Puppeteer (Python-Bibliothek)
Puppeteer ist ein leistungsstarkes headless Browser-Automatisierungstool für das Scraping, das hauptsächlich mit Node.js verwendet wird, aber auch mit Pyppeteer (Python-Version) integriert werden kann. Puppeteer simuliert echte Benutzeraktionen, einschließlich des Lösens von CAPTCHAs. In Kombination mit CAPTCHA-Lösungsdiensten von Drittanbietern ist Puppeteer eine ausgezeichnete Lösung zum Umgehen von CAPTCHA-Herausforderungen beim Scraping.
Hauptmerkmale:
- Simuliert menschenähnliches Surfverhalten.
- Unterstützt das Scraping dynamischer Inhalte.
- Umgeht CAPTCHAs durch Integration mit CAPTCHA-Lösern.
Wie man Amazon CAPTCHA in Octoparse beim Scraping umgeht?
Amazons CAPTCHA-System, das textbasierte, bildbasierte und interaktive CAPTCHAs sowie die erweiterten Herausforderungen von AWS WAF umfasst, kann Ihren Scraper sofort stoppen.
Octoparse bietet eine vollständige Lösung zur automatischen Bewältigung von Amazon CAPTCHAs ohne Programmierung.
Vier Möglichkeiten, Amazon CAPTCHA zu lösen
Verwenden Sie Octoparses vorgefertigte Amazon-Vorlagen (Schnellmethode)
- Wählen Sie Octoparses Amazon-spezifische Scraping-Vorlagen für Ihre Anforderungen
- Vorlagen sind mit vordefinierten Anti-Blockierungs-Maßnahmen und CAPTCHA-Behandlung vorkonfiguriert
- Erhalten Sie eine schnelle, effiziente Einrichtung ohne manuelle Konfiguration
Beginnen Sie noch heute mit dem Umgehen von CAPTCHAs, indem Sie die folgende Vorlage ausprobieren!
https://www.octoparse.de/template/amazon-product-scraper-by-keywords
https://www.octoparse.com/template/amazon-reviews-scraper
CAPTCHA-Lösung in Ihren Scraping-Workflow integrieren
- Fügen Sie den Schritt „CAPTCHA lösen” während der Scraper-Einrichtung hinzu
- Verarbeitet reCAPTCHA v2 und bildbasierte CAPTCHAs automatisch
- Hält die Extraktion am Laufen, wenn Herausforderungen auftreten
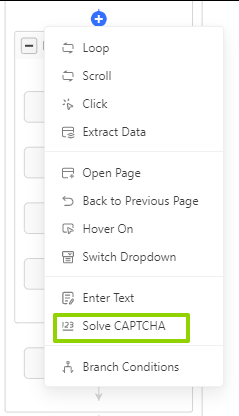
📑Für detaillierte Möglichkeiten zur Lösung verschiedener CAPTCHAs lesen Sie unseren vollständigen Leitfaden zum Lösen von CAPTCHAs.
Proxy-Rotation aktivieren
- Konfigurieren Sie die Proxy-Verwaltung in den Einstellungen
- Rotiert IP-Adressen automatisch, um einer Erkennung zu entgehen
- Verhindert, dass Amazon Ihre Aktivitäten durch Rate-Limiting einschränkt
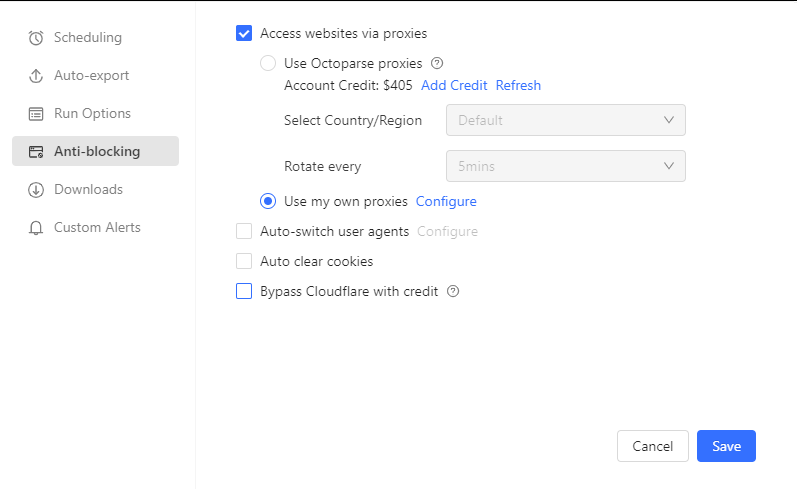
📑Hier ist eine Schritt-für-Schritt-Anleitung zur Einrichtung eines Proxys in Octoparse..
Cloud-basiertes Scraping verwenden
- Führen Sie Aufgaben in Octoparses Cloud-Umgebung aus
- Umgehen Sie lokale IP-Beschränkungen und Sperren
- Reduzieren Sie das Erkennungsrisiko durch Amazons Anti-Bot-Systeme
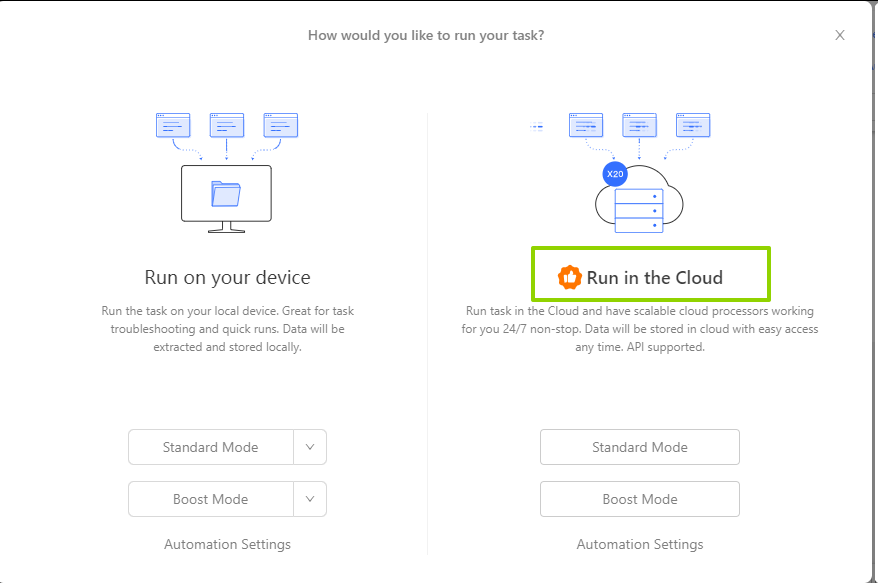
📑FFür detaillierte Implementierungsschritte und erweiterte Konfigurationen lesen Sie unseren vollständigen Leitfaden zum Umgehen von Amazon CAPTCHA beim Scraping.
Abschließende Gedanken
Das Umgehen von CAPTCHAs ist einer der wichtigsten Aspekte beim erfolgreichen Web-Scraping, insbesondere beim Umgang mit Websites wie Amazon, die CAPTCHA-Mechanismen einsetzen, um automatisierte Bots zu verhindern.
Von leistungsstarken Tools wie Octoparse bis hin zu Browser-Erweiterungen und Python-Bibliotheken stehen mehrere Methoden zur Verfügung, um CAPTCHA-Herausforderungen effizient zu umgehen.
Für ein nahtloses Scraping-Erlebnis bietet Octoparse eine automatisierte Lösung zur Bewältigung von CAPTCHAs ohne manuelle Eingriffe, während Tools wie 2Captcha, Selenium und ProxyMesh zusätzliche Flexibilität und Kontrolle bieten. Wählen Sie das Tool, das am besten zu Ihren Scraping-Anforderungen passt, und beginnen Sie mit der Datenerfassung ohne Unterbrechungen.
Häufig gestellte Fragen zur CAPTCHA-Umgehung
1. Wie deaktiviere ich die CAPTCHA-Überprüfung?
Sie können CAPTCHA nicht direkt deaktivieren, da es von der Website kontrolliert wird, aber Sie können es mithilfe von CAPTCHA-Lösungstools oder APIs umgehen. Gängige Optionen umfassen:
- 2Captcha – ein kostenpflichtiger Dienst, bei dem echte Menschen CAPTCHAs in Echtzeit lösen
- Anti-Captcha – ein automatisierter Dienst mit API-Integration für reCAPTCHA und hCaptcha
- DeathByCaptcha – erschwingliche, API-basierte CAPTCHA-Lösungsunterstützung
- ImageTyperz – funktioniert mit verschiedenen CAPTCHA-Formaten, einschließlich reCAPTCHA
Für Nicht-Programmierer integrieren Scraping-Tools wie Octoparse Proxy-Rotation und CAPTCHA-Behandlungsfunktionen, sodass Sie die Datenextraktion fortsetzen können, ohne CAPTCHAs manuell lösen zu müssen.
2. Wie geht man mit ungültigem CAPTCHA um?
Ungültiges CAPTCHA tritt häufig auf, wenn die Lösung nicht übereinstimmt oder die Sitzung abläuft. Um dies zu beheben:
- CAPTCHA aktualisieren und erneut lösen
- Cookies und Cache löschen, um Sitzungen zurückzusetzen
- Scraping-Tools verwenden, die automatisch Wiederholungsversuche und Sitzungsverwaltung handhaben, wodurch CAPTCHA-Fehler reduziert werden
3. Wie vermeidet man CAPTCHAs durch Verbesserung des Request-Fingerprintings?
Websites lösen CAPTCHAs aus, wenn sie bot-ähnliches Verhalten erkennen. Um das Request-Fingerprinting zu verbessern:
- User-Agents und IPs rotieren
- Verzögerungen hinzufügen, um menschliche Surfmuster nachzuahmen
- Eine Scraping-Lösung wie Octoparse verwenden, die bereits Header, Cookies und IP-Rotation optimiert, um menschenähnlicher zu erscheinen
4. Was ist CAPTCHA?
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) ist eine Sicherheitsmaßnahme, die verwendet wird, um Menschen von Bots zu unterscheiden. Häufige Typen umfassen:
- Bilderkennung
- Texteingabe-Rätsel
- reCAPTCHA (Googles Version mit Kontrollkästchen oder unsichtbarer Überprüfung)
5. Wie implementiert man Selenium zum Umgehen von reCAPTCHA auf Websites?
Selenium kann mit CAPTCHA-Lösungsdiensten von Drittanbietern verwendet werden. Allgemeine Schritte:
- CAPTCHA-Lösungs-API in das Selenium-Skript integri
- Die CAPTCHA-Herausforderung erfassen und an den Löser senden
- Das gelöste Token zurück in das Formular eingeben
Dies erfordert Programmierkenntnisse, aber für Nicht-Programmierer – warum nicht Octoparse ausprobieren?



