Wenn Sie jemals Stunden in die Entwicklung eines Web Scrapers investiert haben, nur damit er am nächsten Tag nicht mehr funktioniert, weil sich das Layout geändert hat, dann kennen Sie diesen Frust. Wer website änderungen überwachen muss, weiß, wie fehleranfällig das ist.
Genau das passierte mir bei der Entwicklung eines Instagram-Post-Scrapers. Die Elemente lassen sich nicht auswählen, die Knoten bleiben nicht konsistent und automatisch generierte Browser-Selektoren lassen Sie genau dann im Stich, wenn Sie sie am meisten brauchen. Tatsache ist: Wenn es um zuverlässiges Web Scraping geht, sind diese Selektoren ein Rezept für eine Katastrophe. Das Geheimnis für stabile Scraper ist, unseren XPath Spickzettel zu lernen.
CSS-Selektoren sind großartig für grundlegendes Styling und die Auswahl von Elementen, aber wenn Sie durch einen komplexen DOM-Baum navigieren und Elemente basierend auf ihrem tatsächlichen Inhalt auswählen müssen, reichen sie einfach nicht aus. Genau dann wird XPath unverzichtbar und das ist der Grund, warum die meisten Produktions-Scraper darauf aufbauen.
Schnelle Antwort
| Ausdruck | Was er tut |
| //tag | Wählt übereinstimmende Knoten überall im Dokument aus (relativer Pfad; bevorzugt gegenüber absolutem /) |
| contains(@attr, ‘val’) | Findet einen teilweisen Attributwert — sicher für dynamische Klassennamen und gehashte IDs |
| contains(text(), ‘val’) | Wählt Elemente aus, deren sichtbarer Text eine bestimmte Zeichenfolge enthält |
| //tag/parent::* | Navigiert nach oben zum direkten übergeordneten Element (Aufwärtsnavigation, die CSS nicht kann) |
| //tag/following-sibling::tag[1] | Wählt das unmittelbar folgende Geschwisterelement aus — wichtig für das Scraping von Label-Wert-Paaren |
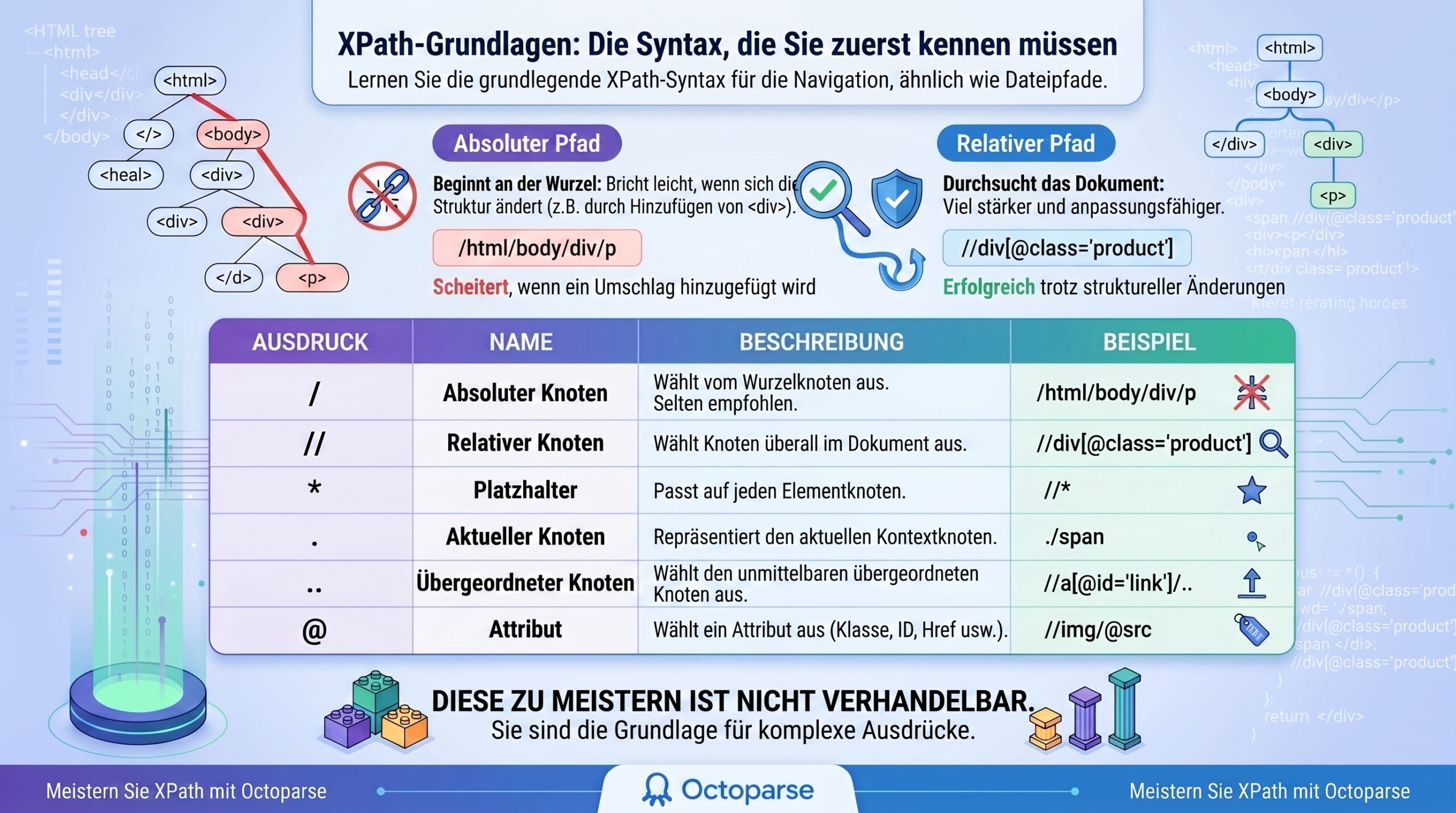
XPath Grundlagen: Syntax, die Sie zuerst kennen müssen
Sie müssen die Grundlagen der XPath-Syntax kennen, bevor Sie erweiterte Funktionen nutzen und in komplexen Dokumenten navigieren können. XPath verwendet eine pfadähnliche Syntax, um durch die HTML- oder XML-Baumstruktur zu navigieren, genau wie Sie sich durch Dateien und Ordner auf Ihrem Computer bewegen.
Als Erstes müssen Sie den Unterschied zwischen absoluten und relativen Pfaden lernen. Absolute Pfade beginnen an der Wurzel (Root) des Dokuments, sodass sie sehr leicht brechen, wenn der Seite nur ein einziges Wrapper-<div> hinzugefügt wird. Relative Pfade hingegen durchsuchen das gesamte Dokument, was Ihre Scraper viel robuster macht.
Hier ist eine kurze Referenztabelle der grundlegenden Syntax, die Sie auswendig lernen sollten:
| Ausdruck | Name | Beschreibung & Anwendungsfall | Beispiel |
| / | Absoluter Knoten | Wählt ab dem Wurzelknoten aus. Für Web Scraping selten empfohlen, da er leicht bricht. | /html/body/div/p |
| // | Relativer Knoten | Wählt Knoten überall im Dokument ab dem aktuellen Knoten aus, die der Auswahl entsprechen. | //div[@class=’product’] |
| * | Platzhalter (Wildcard) | Entspricht jedem Elementknoten. Nützlich, wenn der Tag-Name unbekannt oder variabel ist. | //*[@id=’main’] |
| . | Aktueller Knoten | Repräsentiert den aktuellen Kontextknoten. Nützlich in verschachtelten Schleifen beim Scraping. | ./span |
| .. | Übergeordneter Knoten | Wählt das direkte übergeordnete Element (Parent) des aktuellen Knotens. Ideal, um im Baum nach oben zu gehen. | //a[@id=’link’]/.. |
| @ | Attribut | Wählt ein Attribut aus (wie class, id, href oder src). | //img/@src |
Die Beherrschung dieser Bausteine ist nicht verhandelbar. Sie sind das Fundament, auf dem jeder komplexe XPath-Ausdruck aufbaut.
XPath Achsen Spickzettel
Die grundlegende Syntax sagt Ihnen, wie Sie ein Element auswählen, und XPath-Achsen (Axes) sagen Ihnen, wie Sie sich um es herum bewegen. Sie können sich mit Achsen durch den DOM-Baum bewegen, indem Sie betrachten, wie Knoten zueinander in Beziehung stehen. Das ist die Superkraft von XPath, mit der CSS-Selektoren einfach nicht mithalten können. Wenn ein Element keine eindeutige ID oder Klasse hat, können Sie es finden, indem Sie seine Beziehung zu einer Komponente betrachten, die eine hat.
Dies ist eine vollständige Liste der häufigsten XPath-Achsen, die beim Web Scraping verwendet werden:
child::
Erklärung: Dies wählt alle direkten Kinder des aktuellen Knotens aus. Hinweis: //div/child::p und //div/p sind dasselbe.
Zum Beispiel: //ul[@class=’menu’]/child::li
parent::
Erklärung: Wählt den übergeordneten Knoten (Parent) des aktuellen Knotens. Es funktioniert genauso wie ..
Zum Beispiel: //span[@class=’price’]/parent::div
ancestor::
Erklärung: Dies wählt alle Vorfahren des aktuellen Knotens aus, vom Elternteil bis zum Großelternteil und so weiter, bis hin zur Wurzel. Großartig, um übergeordnete Wrapper-Container zu lokalisieren.
Zum Beispiel: //td[contains(text(), ‘Total’)]/ancestor::table
descendant::
Erklärung: Dies wählt alle Kinder, Enkelkinder und so weiter des aktuellen Knotens aus. (Wie die Verwendung von // nach einem Knoten).
Zum Beispiel: //div[@id=’content’]/descendant::a
following-sibling::
Erklärung: Dies wählt alle Geschwisterknoten aus, die im HTML-Dokument nach dem aktuellen Knoten erscheinen, vorausgesetzt, sie teilen denselben Elternteil. Dies ist eine enorme Hilfe beim Scrapen von Definitionslisten oder Formular-Labels neben Eingabefeldern.
Zum Beispiel: //label[text()=’Email’]/following-sibling::input
preceding-sibling::
Erklärung: Dies wählt alle Geschwisterknoten aus, die im HTML-Dokument vor dem aktuellen Knoten stehen.
Zum Beispiel: //button[@type=’submit’]/preceding-sibling::input[@type=’text’]
self::
Erklärung: Dies wählt den aktuell ausgewählten Knoten aus. Wird oft mit anderen Prädikaten verwendet, um die Eigenschaften eines Knotens zu überprüfen.
Zum Beispiel: //div/self::*[@class=’active’]
Wenn Sie Achsen verwenden, verlässt sich Ihr Scraper auf logische strukturelle Beziehungen anstatt auf Styling-Klassen, die sich oft ändern.

XPath Funktionen Spickzettel
XPath ist mehr als nur ein Weg, auf einen Pfad zu verweisen. Es enthält auch viele integrierte Funktionen, die Strings verarbeiten, boolesche Ausdrücke auswerten und Knoten zählen können. Sie müssen keinen komplizierten Post-Processing-Code in Ihrem Scraping-Skript schreiben, wenn Sie diese Funktionen kennen.
Hier ist eine Tabelle der wichtigsten XPath-Funktionen, die jeder Web Scraper kennen sollte:
| Funktion | Syntax & Nutzung | Anwendungsfall verständlich erklärt | XPath Beispiel |
| contains() | contains(string1, string2) | Die absolut wichtigste Funktion. Prüft, ob ein String oder Attribut einen bestimmten Teilstring enthält. Adressiert alle Inhalte im XPath. | //div[contains(@class, ‘button’)] |
| text() | text() | Extrahiert den Textknoten eines Elements. Wird oft mit contains oder exakten Übereinstimmungsoperatoren gepaart. | //a[text()=’Hier klicken’] |
| starts-with() | starts-with(string1, string2) | Prüft, ob ein String oder Attribut mit einem bestimmten Wert beginnt. Perfekt für dynamische IDs, an die zufällige Zahlen angehängt werden. | //div[starts-with(@id, ‘post-‘)] |
| normalize-space() | normalize-space(string) | Entfernt führende und nachgestellte Leerzeichen und ersetzt mehrfache Leerzeichen durch ein einziges. Sehr empfehlenswert für unsauberes HTML. | //p[normalize-space(text())=’Sauberer Text’] |
| not() | not(boolean) | Kehrt eine Bedingung um. Nützlich zum Ausschließen von Elementen, wie versteckten Feldern oder bestimmten Klassen. | //input[not(@type=’hidden’)] |
| last() | last() | Wählt das letzte Element in einer Knotenmenge aus. Großartig, um die letzte Seite in einer Paginierungssequenz zu greifen. | //ul[@class=’pagination’]/li[last()] |
| position() | position() | Zielt auf ein Element basierend auf seiner Indexposition in der Knotenmenge ab. | //tr[position() < 4] |
| count() | count(node-set) | Gibt die Anzahl der Knoten in einer bestimmten Menge zurück. Nützlich zur Datenvalidierung während des Scrapings. | count(//div[@class=’item’]) |
| string-length() | string-length(string) | Gibt die Zeichenanzahl eines Strings zurück. Nützlich, um leere Tags herauszufiltern oder beschreibende Absätze zu finden. | //p[string-length(text()) > 100] |
Diese Funktionen befähigen Sie, intelligente Selektoren zu schreiben, die den Inhalt und Kontext der Seite verstehen, anstatt nur die rohe Tag-Struktur.
XPath Attribut contains() im Detail: Die am häufigsten falsch verwendete Funktion
Contains() ist die eine Funktion, die über Erfolg oder Misserfolg Ihrer Datenextraktion entscheiden kann. Viele moderne Websites verwenden dynamisch generierte CSS-Frameworks (wie Tailwind CSS oder styled-components) und JavaScript-Frameworks (wie React oder Vue). Ein Element durch teilweisen Text oder ein teilweises Attribut zu finden, ist notwendig, weil sich Klassen und IDs bei jedem Laden der Seite ändern.
Dieser Abschnitt zeigt Ihnen, wie Sie den XPath-Operator “contains” verwenden, um reale Probleme zu lösen.
contains() mit text(): Knoten nach partiellem Textinhalt auswählen
Wenn Sie wissen, was in einem Element steht, aber nicht, wo es sich befindet oder ob der Text zusätzliche Leerzeichen enthalten könnte, ist die beste Methode, XPath contains text zu verwenden. Um Text in XPath zu finden, verwenden Sie die Funktion contains() zusammen mit der Knotenfunktion text().
Um einen Button zu finden, auf dem “Bestellung absenden” steht, der aber am Ende zusätzliche Leerzeichen haben könnte, verwenden Sie diesen Code: //button[contains(text(), ‘Bestellung’)]
Wenn Sie einen XPath-Text finden möchten, der eine Überschrift enthält, verwenden Sie dies: //h2[contains(text(), ‘Spezifikationen’)]
Ein hilfreicher Trick für Text, der XPath-Abfragen enthält, ist der Umgang mit unsauberen Daten. Text() funktioniert möglicherweise nicht, wenn der Text innerhalb von Kind-Elementen oder Spans liegt. In diesem Fall verwenden Sie einen Punkt (.), um den String-Wert des Knotens und all seiner Kinder zu überprüfen: //div[contains(., ‘Gesamtpreis’)]
contains() mit Attributen: Partielle Klassennamen und URLs
Websites verwenden oft Utility-Klassen oder hängen zufällige Hashes an IDs an, wie class=”btn primary-btn flex-row” oder id=”user-12849″. Ein XPath-Attribut hat ein Abfrageziel, das auf den statischen Teil des Attributs zeigt.
Um einen Link mit einer URL zu finden, die einen bestimmten Teil enthält, verwenden Sie diesen Code: //a[contains(@href, ‘/category/electronics’)]
Wenn Sie eine XPath-Lösung benötigen, die mit dynamischen Klassennamen funktioniert, verwenden Sie dies: //div[contains(@class, ‘product-card’)]
contains() vs = (Exakte Übereinstimmung)
Es ist zwingend erforderlich zu wissen, wann Sie den XPath-Operator “contains” anstelle des Gleichheitszeichens (=) verwenden sollten.
Exakte Übereinstimmung (=): //a[text()=’Login’]. Es dürfen keine zusätzlichen Leerzeichen, Zeilenumbrüche oder HTML-Tags im Text sein. Es muss exakt “Login” sein.
Teilweise Übereinstimmung (contains()): //a[contains(text(), ‘Login’)]. Entspricht “Login”, “Benutzer Login” oder “Jetzt Login”.
Verwenden Sie eine exakte Übereinstimmung, wenn Sie einen XPath für eine genaue Textübereinstimmung wünschen. Aber für das Scraping ist contains() viel sicherer, da Webentwickler dem DOM oft unsichtbare Zeilenumbrüche hinzufügen.
Häufige Fehler, die Sie vermeiden sollten
- Groß-/Kleinschreibung: XPath 1.0, das von den meisten Browsern und Scraping-Bibliotheken verwendet wird, unterscheidet zwischen Groß- und Kleinschreibung. contains(text(), ‘login’) wird nicht mit “Login” übereinstimmen. Sie müssen Workarounds wie translate() verwenden, um sicherzustellen, dass die Groß-/Kleinschreibung keine Rolle spielt, aber meistens ist es einfacher, einfach die erwartete Schreibweise abzugleichen.
- Wenn Ihr HTML <p></p> ist, wird die Verwendung von text() auf verschachtelten Knoten fehlschlagen. Preis: <span>10€</span></p> Wenn Sie //p[contains(text(), ‘Preis: 10€’)] verwenden, wird es nicht funktionieren, weil text() nur den direkten Textknoten des <p>-Tags (“Preis: “) holt. Um dies zu beheben, verwenden Sie //p[contains(., ‘Preis: 10€’)].
- Leerzeichen sind essenziell, vergessen Sie sie also nicht. Es wird nicht funktionieren, wenn Ihr Ziel “Log In” ist und Sie contains(text(), ‘Login’) verwenden. Für maximale Sicherheit verwenden Sie //a[contains(normalize-space(text()), ‘Log In’)] damit.
XPath für Web Scraping: Muster aus der Praxis
Es ist eine Sache, die Syntax zu kennen, es ist eine andere, sie zu Scraping-Mustern zusammenzusetzen. Dies sind die exakten XPath-Muster, die Web Scraper verwenden, um durch komplexe, moderne Websites zu navigieren.
Auswahl von Teilen mit dynamischen oder partiellen Klassennamen
Wir haben darüber gesprochen, wie moderne Web-Frameworks Klassen wie styles__ProductCard-sc-12345 erstellen. Sie können den unverständlichen Hash überspringen, indem Sie direkt zum semantischen Teil des Klassennamens gehen: //div[contains(@class, ‘ProductCard’)]
Auswahl eines Links für die Paginierung
Zur “Nächsten” Seite zu gehen, ist ein Standardteil des Web Scrapings. Anstatt strukturelle Pfade zu verwenden, die sich ändern, je nachdem, wie viele Seiten es gibt, finden Sie den Button durch seinen Text oder aria-labels: //a[contains(text(), ‘Nächste’) or contains(@aria-label, ‘Nächste Seite’)]
Elemente mithilfe von Geschwistertext anvisieren
Eine der häufigsten Scraping-Herausforderungen ist das Extrahieren von Daten aus einer Tabelle oder einer Liste von Details, wenn die Klassennamen gleich sind. Sie benötigen den Namen neben dem Label “Autor:”. Sie verwenden das vorherige Geschwisterelement, um sich einzuklinken, und das nächste Geschwisterelement, um das folgende zu erhalten: //span[text()=’Autor:’]/following-sibling::span[1]
Attribute abrufen (href, src, data-*)
Beim Scraping geht es nicht nur um Text, sondern auch um Links und Medien. Wenn Sie alle hochauflösenden Bilder von einer Produktseite abrufen möchten, die langsam lädt, könnten Sie das benutzerdefinierte Datenattribut anstelle der Standardquelle verwenden: //img[@class=’product-image’]/@data-hires-src.
Umgang mit Tabellen und sich wiederholenden Strukturen
Sie wollen normalerweise nur bestimmte Spalten, wenn Sie Datenraster scrapen. Zum Beispiel können Sie die dritte Spalte (Preis) jeder Zeile in einer Tabelle abrufen, indem Sie Achsen und Positionen kombinieren: //table[@id=’pricing’]/tbody/tr/td[3].
Wenn Sie Chrome DevTools verwenden, um Selektoren automatisch zu erstellen (Rechtsklick → Kopieren → XPath kopieren), erhalten Sie oft so etwas Schreckliches wie /html/body/div[2]/div/div[3]/ul/li[4]/a. Dies funktioniert nicht mehr, sobald sich die Seite ändert. Wenn Sie die oben genannten Methoden verwenden, um Ihre eigenen logischen Muster zu schreiben, werden sie von Dauer sein.
Wenn XPath das richtige Element findet, die Daten aber noch nicht da sind, ist die Seite wahrscheinlich dynamisch. Wenn Sie Daten von Seiten abrufen, die Inhalte selbstständig laden, schauen Sie sich unseren Leitfaden an, wie man Ajax- und JS-Websites scrapt.
contains() mit parent:: für die Aufwärtsnavigation verketten
Eines der mächtigsten Muster in Produktions-Scrapern ist die Kombination eines textbasierten contains()-Prädikats mit der parent::-Achse. Dies ermöglicht es Ihnen, ein Element anhand seines lesbaren Labels zu lokalisieren und dann zu seinem enthaltenden Block aufzusteigen. Um beispielsweise das div zu finden, das ein beliebiges span umhüllt, dessen Text “Preis” enthält:
//span[contains(text(),’Preis’)]/parent::div
Dies ist stabiler, als das div direkt anzuvisieren, weil Sie den Pfad an sichtbarem Text verankern, der sich unwahrscheinlich ändert, anstatt an einer strukturellen Klasse, die möglicherweise neu generiert wird.
contains() mit AND / OR für mehrere Bedingungen
Sie können mehrere contains()-Aufrufe innerhalb eines einzigen Prädikats kombinieren, indem Sie die booleschen XPath-Operatoren and und or verwenden. Dies ist unerlässlich, wenn Sie Elemente abgleichen müssen, die zwei Bedingungen gleichzeitig erfüllen — zum Beispiel ein Button, der sowohl ein bestimmtes Klassenfragment als auch spezifischen Text hat:
//div[contains(@class,’btn’) and contains(text(),’Senden’)]
Die Verwendung von or funktioniert genauso und ist nützlich für die Paginierung, wo das klickbare Element entweder “Weiter” sagen oder ein aria-label tragen könnte: //a[contains(text(),’Weiter’) or contains(@aria-label,’Nächste Seite’)]
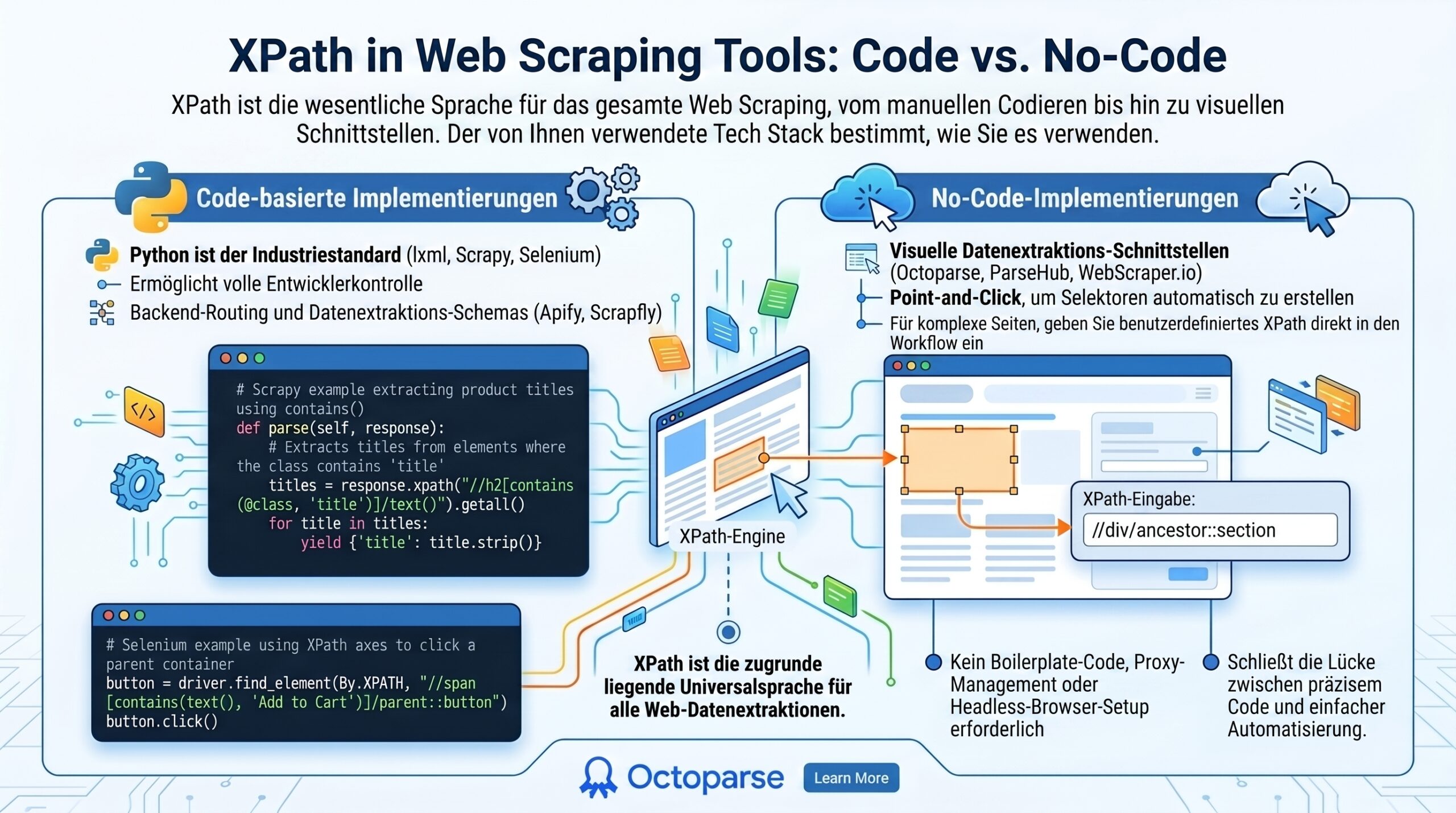
XPath in Web Scraping Tools: Code vs. No-Code
Der Technologie-Stack, den Sie verwenden, bestimmt, wie Sie XPath nutzen. XPath ist die Sprache, die jeder für Web Scraping verwendet, egal ob er Python-Code schreibt oder ein visuelles Datenextraktions-Tool nutzt.
Code-basierte Implementierungen
Wenn es um python web scraping deutsch geht, ist Python der Branchenstandard für Entwickler und unterstützt Bibliotheken wie lxml, Scrapy und Selenium. XPath ist ein wichtiger Bestandteil der Backend-Routing- und Datenextraktionsschemata für Python-Scraping-Bibliotheken wie lxml, Scrapy und Selenium.
So könnten Sie unsere XPath contains text-Muster in Python mit Scrapy verwenden:
Und hier ist ein kurzes Beispiel, wie Sie mit selenium element finden und auf einen dynamischen Button klicken können:
No-Code Implementierungen mit Octoparse
Nicht alle Scraping-Projekte erfordern ein maßgeschneidertes Python-Skript. Octoparse, ParseHub und WebScraper.io sind Beispiele für No-Code- und Low-Code-Tools mit leistungsstarken visuellen Schnittstellen für die Datenextraktion.
Sie können beispielsweise die Point-and-Click-Oberfläche von Octoparse verwenden, um Selektoren automatisch zu erstellen. Aber wenn Sie auf eine Website stoßen, die sehr komplex oder schlecht organisiert ist, lässt Octoparse Sie benutzerdefinierte XPath-Ausdrücke direkt in den Workflow eingeben. Mit anderen Worten, Sie können die erweiterten contains()-Funktionen und Achsen, über die wir gesprochen haben, verwenden, ohne Boilerplate-Code schreiben, sich mit Proxys befassen oder Headless-Browser einrichten zu müssen.
Octoparse kümmert sich um die Infrastruktur — Proxys, Rendering, Scheduling — sodass Sie sich darauf konzentrieren können, den richtigen XPath zu schreiben, anstatt den Stack darum herum zu warten.
Der integrierte XPath-Generator von Octoparse entfernt automatisch flüchtige Klassen-Hashes und Tracking-Attribute und synthetisiert dann einen stabilen relativen Pfad. Wenn Sie dies überschreiben oder feinabstimmen möchten, fügen Sie Ihren eigenen contains()-Ausdruck direkt in das Selektorfeld ein — kein Headless-Browser-Setup, keine Proxy-Konfiguration, kein Boilerplate.
Wie Octoparse robuste XPath-Selektoren im Hintergrund generiert
Wir haben den Selektor-Generator auf drei E-Commerce-Sites mit dynamischen Tailwind CSS-Klassen getestet — der generierte XPath blieb über 50+ Seitenneuladevorgänge ohne Änderung stabil.
In dem Moment, in dem Sie ein Element auswählen, initiiert Octoparse eine spezialisierte Pipeline, um einen präzisen und stabilen XPath zu konstruieren:
- DOM-Merkmalsextraktion
Die Engine sammelt Tags, ID-Werte, Klassennamen und die strukturelle DOM-Hierarchie, um sie als Hauptkandidaten für den Locator zu verwenden. - Semantische Rauschunterdrückung
Flüchtige Klassen-Hashes, Tracking-Attribute und irrelevanter Text werden aggressiv bereinigt, sodass nur die zuverlässigsten semantischen Signale übrig bleiben. - Eindeutigkeitssuche
Eine rigorose kombinatorische Suche bewertet Merkmalsätze, um die schlankste Kombination zu identifizieren, die ein eindeutiges Element-Targeting garantiert. - Optimale XPath-Synthese
Das System erstellt einen verfeinerten, änderungsresistenten Selektor, da Stabilität wichtiger ist als semantische Attribute und Text.
Der Octoparse-Generator kann die Herausforderungen moderner Websites bewältigen. Er beseitigt dynamisches Rauschen und bevorzugt elegante relative Ausdrücke gegenüber anfälligen absoluten Pfaden. Die Normalisierung von Text aus anderen Ländern, wie Englisch und Chinesisch, sowie von Zahlen stellt sicher, dass Ihre Scraping-Logik im gesamten Web funktioniert.
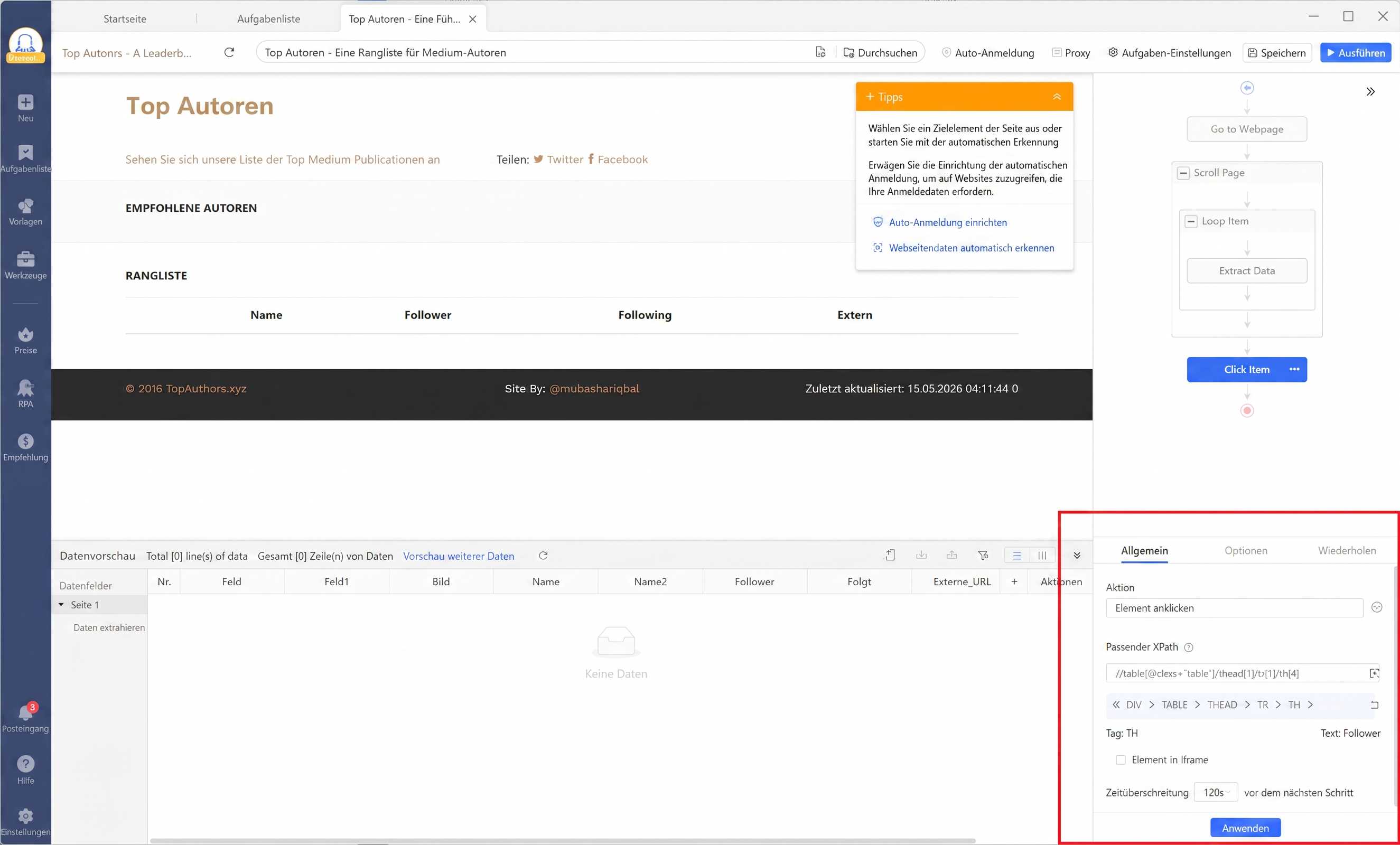
Octoparse XPath-Selektor-Panel auf einer Produktseite mit dynamischen Klassennamen.
XPath vs. CSS-Selektoren: Schnellreferenz
Die Debatte zwischen XPath und CSS-Selektoren läuft seit den Anfängen des Web Scrapings. CSS-Selektoren sind für einfache Aufgaben leichter zu lesen und zu tippen, aber XPath ist der beste Weg, um sich zu bewegen. Dies ist eine kurze Entscheidungsmatrix, die Ihnen hilft, das richtige Werkzeug für den Job auszuwählen.
| Funktion | XPath | CSS-Selektor |
| Syntax-Stil | Pfadbasiert (//div/p) | Stylingbasiert (div > p) |
| Auswahl nach Textinhalt | Ja (contains(text(), ‘val’)) | Nein (Erfordert externes JS/Regex) |
| Aufwärtsnavigation | Ja (parent::, ancestor::) | Nein (CSS4 hat :has(), aber Unterstützung variiert) |
| Geschwister-Navigation | Beide Richtungen (following, preceding) | Nur vorwärts (+, ~) |
| Attribut-Abgleich | Umfangreich (starts-with, contains) | Ja ([attr^=val], [attr*=val]) |
| Browser-Unterstützung | Universell | Universell |
| Scraping Tool Unterstützung | Exzellent (Scrapy, Selenium, Octoparse) | Exzellent (BeautifulSoup, Puppeteer) |
Das Fazit: CSS-Selektoren funktionieren gut bei einfachem, gut strukturiertem HTML, bei dem sich IDs und Klassen nicht ändern. Wenn Sie auf Textinhalte abzielen, durch eine komplexe DOM-Hierarchie navigieren oder im DOM nach oben gehen müssen, gewinnt XPath immer.
Wenn Sie mit dynamischen Seiten arbeiten, ist es genauso wichtig zu wissen, wie sie geladen werden, wie Ihre Selektoren zu kennen. Schauen Sie sich unseren Leitfaden zu dynamischen Webseiten an.
Kurzreferenz XPath Spickzettel Tabelle
Verwenden Sie diese Master-Tabelle, wenn Sie mitten in einem Scraping-Projekt stecken und die Syntax genau richtig hinbekommen müssen. Speichern Sie diese Seite als Lesezeichen und kopieren Sie diese Vorlagen dann direkt in Ihren Scraper.
| Ziel | XPath Vorlage | Beispiel |
| Auswahl nach exakter Klasse | //tag[@class=’exact-name’] | //div[@class=’product-grid’] |
| Auswahl nach partieller Klasse | //tag[contains(@class, ‘partial’)] | //button[contains(@class, ‘btn-primary’)] |
| Auswahl nach exaktem Text | //tag[text()=’Exact Text’] | //a[text()=’Mehr lesen’] |
| Auswahl nach partiellem Text | //tag[contains(text(), ‘Partial Text’)] | //h1[contains(text(), ‘Bewertung’)] |
| Text in verschachtelten Tags auswählen | //tag[contains(., ‘Nested Text’)] | //div[contains(., ‘Auf Lager’)] |
| Übergeordneten Knoten auswählen | //tag/parent::tag oder //tag/.. | //span[@id=’price’]/.. |
| Ein spezifisches Geschwisterelement auswählen | //tag/following-sibling::tag[1] | //dt[text()=’Gewicht’]/following-sibling::dd[1] |
| Auswahl nach mehreren Attributen | //tag[@attr1=’val1′ and @attr2=’val2′] | //input[@type=’text’ and @name=’search’] |
| Das n-te Kind auswählen | //tag[position()=n] | //ul[@id=’menu’]/li[3] |
| Element ohne ein bestimmtes Attribut auswählen | //tag[not(@attribute)] | //img[not(@alt)] |
Fazit
Die Verwendung von automatisch generierten Selektoren ist der schnellste Weg, um Web Scraper zu zerstören und Daten zu verlieren. Wenn Sie sich die Zeit nehmen, zu lernen, wie man XPath von Hand generiert, können Sie sich von jemandem, der nur klickt, zu einem Datenextraktionsexperten entwickeln, der in den feindlichsten DOM-Umgebungen arbeiten kann.
Die wahre Stärke von XPath ist seine logische Flexibilität. Sie können Scraper erstellen, die mit Website-Updates, dynamischen Klassenänderungen und Layout-Änderungen umgehen können, indem Sie strukturelle Achsen wie following-sibling:: verwenden und textbasierte Funktionen wie contains() beherrschen.
Speichern Sie sich für Ihr nächstes Projekt unbedingt diesen XPath Spickzettel. Wenn Sie die Genauigkeit von fortgeschrittenem XPath wünschen, aber nicht mit der Backend-Python-Infrastruktur Schritt halten möchten, sollten Sie Octoparse ausprobieren. Es bietet die beste Umgebung für die Ausführung komplexer XPath-Ausdrücke innerhalb eines robusten, visuellen Frameworks. Lernen Sie diese Formeln, wenden Sie sie richtig an, und dies wird der letzte XPath Spickzettel sein, den Sie jemals brauchen.
Häufig gestellte Fragen (FAQs) zu XPath
- Was ist der Hauptunterschied zwischen XPath und CSS-Selektoren?
Der Hauptunterschied liegt in ihren Navigationsfähigkeiten. CSS-Selektoren können sich nur vorwärts (den Baum hinab) bewegen und basierend auf Styling-Attributen (Klassen, IDs, Tags) auswählen. XPath ist mächtiger, da es sowohl Vorwärts- als auch Rückwärtsnavigation (aufwärts/Vorfahren) mit Achsen wie parent:: und ancestor:: ermöglicht und Elemente basierend auf ihrem Textinhalt mit Funktionen wie contains(text(), ‘value’) auswählen kann.
- Warum sollte ich relativen XPath (//) anstelle von absolutem XPath (/) für Web Scraping verwenden?
Absoluter XPath beginnt an der Dokumentwurzel (z.B. /html/body/div…) und ist extrem anfällig. Wenn ein einzelnes Element in der Nähe des Seitenanfangs hinzugefügt oder entfernt wird (wie ein Wrapper-<div>), bricht der Pfad. Relativer XPath (//) durchsucht das gesamte Dokument nach übereinstimmenden Knoten, was den Selektor wesentlich widerstandsfähiger gegen geringfügige Layoutänderungen macht.
- Wann sollte ich contains() anstelle einer genauen Übereinstimmung (=) verwenden?
Sie sollten contains() verwenden, wenn ein Attribut (wie @class oder @id) dynamisch generiert wird oder mehrere Utility-Klassen enthält (z.B. class=”btn primary-btn flex-row”) und Sie nur einen partiellen, statischen Teil abgleichen müssen. Sie sollten es auch für Textinhalte verwenden, wenn es unvorhersehbare Leerzeichen oder Zeilenumbrüche geben könnte oder wenn Sie nur eine Phrase innerhalb eines längeren Textblocks abgleichen müssen.
- Was ist der Zweck des Punktes (.) in einem XPath-Ausdruck wie //div[contains(., ‘Text’)]?
Der Punkt (.) repräsentiert den String-Wert des aktuellen Knotens und all seiner Nachkommen. Er ist entscheidend, wenn der Text, den Sie abgleichen möchten, das aktuelle Tag und seine verschachtelten Kind-Tags umfasst (z.B. <p>Preis: <span>10€</span></p>). Die Verwendung von text() würde nur den direkten Text des <p>-Tags zurückgeben, der möglicherweise nicht die gesamte Zeichenfolge enthält.
- Wie wähle ich ein Element basierend auf seiner Position aus, wie das letzte Element in einer Liste?
Sie verwenden die Funktion position() oder last(). Um das letzte Element in einer Knotenmenge auszuwählen, verwenden Sie [last()]. Zum Beispiel: //ul[@class=’items’]/li[last()]. Um ein Element anhand seines Index (z.B. das dritte) auszuwählen, verwenden Sie [position()=3] oder einfach [3].
- Funktioniert contains() in XPath 2.0 auf die gleiche Weise?
Die Kernfunktion contains() ist in XPath 2.0 identisch, aber XPath 2.0 führt auch matches() ein, das einen vollständigen regulären Ausdruck als zweites Argument akzeptiert. Zum Beispiel gleicht matches(@id, ‘^post-\d+$’) jede ID ab, die mit “post-” beginnt, gefolgt von Ziffern. Die meisten Browser und Scraping-Bibliotheken führen standardmäßig immer noch XPath 1.0 aus, daher bleibt contains() die sicherere umgebungsübergreifende Wahl, es sei denn, Sie sind sicher, dass Ihre Laufzeitumgebung XPath 2.0 unterstützt.
- Wie verwende ich contains(), wenn der String, nach dem ich suche, ein Anführungszeichen enthält?
XPath 1.0 unterstützt keine Escape-Sequenzen innerhalb von String-Literalen, sodass Sie contains(@title, “it’s”) nicht direkt schreiben können. Der Workaround ist die Funktion concat(), mit der Sie den String aus separaten Teilen mithilfe abwechselnder Anführungszeichenstile aufbauen können: contains(@title, concat(‘it’, “‘”, ‘s’)). Dies setzt den Apostroph aus einem in doppelte Anführungszeichen gesetzten Literal zusammen und vermeidet so den Anführungszeichenkonflikt vollständig.
- Wann sollte ich den CSS-Attributselektor [class*=’val’] anstelle von XPath contains(@class,’val’) verwenden?
Für einfache Klassen-Substring-Abgleiche auf einer modernen Seite ist der CSS-Selektor [class*=’btn’] etwas schneller, da Browser-Engines CSS nativ auswerten. Wechseln Sie zu XPath contains(@class,’btn’), wenn Sie im selben Ausdruck auch Textinhaltsabgleiche, Aufwärtsachsen-Navigation oder Geschwisterauswahl benötigen — alles Dinge, die CSS nicht in einem einzigen Selektor tun kann.
- Wie teste ich XPath-Ausdrücke direkt im Browser?
Öffnen Sie die Chrome- oder Edge-DevTools (F12), wechseln Sie zum Reiter “Console” (Konsole) und geben Sie $$x(‘//ihr-ausdruck-hier’) ein. Der Browser wertet den XPath gegen das Live-DOM aus und gibt eine Liste übereinstimmender Knoten zurück, die Sie inline untersuchen können. Zum Beispiel gibt $$x(‘//div[contains(@class,”product-card”)]’) sofort jedes übereinstimmende Element zurück. Firefox unterstützt dieselbe Kurzschreibweise $x() in seiner Konsole.