Lassen Sie mich ehrlich sein: Die meisten Tutorials zum Web Scraping lügen Sie an, wenn es um den Einsatz von einem Headless Browser geht.
Sie zeigen Folgendes:
- requests.get()
- BeautifulSoup
- Fertig.
Aber versuchen Sie das mal bei einer modernen Website aus der echten Welt, und Sie enden mit leeren Inhalten, fehlerhaften Seiten und fehlenden Daten.
Das liegt daran, dass moderne Websites Daten nicht mehr direkt ausliefern. Da sie einen echten Browser erwarten, haben Sie bereits verloren, wenn Sie keinen verwenden.
Genau hier kommen Headless Browser ins Spiel.
Im Grunde handelt es sich dabei um Chrome oder Firefox, die unsichtbar im Hintergrund laufen, JavaScript ausführen, auf Buttons klicken, dynamische Inhalte laden und sich wie ein echter Nutzer verhalten.
Sobald Sie anfangen, diese einzusetzen, hören Sie auf, mit modernen Websites zu kämpfen, und beginnen mit der Automatisierung und dem Scraping auf die Art und Weise, für die sie eigentlich entwickelt wurden.
Was ist ein Headless Browser?
Ein Headless Browser ist schlichtweg ein echter Browser, der ohne sichtbares Fenster oder Bildschirm läuft.
Diese Idee, „Chrome ohne Chrome auszuführen“, ist genau die Art und Weise, wie das Chromium-Team selbst den Headless-Modus beschreibt, bei dem die vollständige Browser-Engine in einer unbeaufsichtigten Umgebung ohne sichtbare Benutzeroberfläche (UI) ausgeführt wird.
Möchten Sie ein praktisches Beispiel? Denken Sie an Chrome oder Firefox.
Entfernen Sie nun das Fenster, die Tabs, die Buttons und alle visuellen Elemente.
Was übrig bleibt, ist nur die Engine, und genau diese Engine nennen wir einen Headless Browser.
Das Beste daran ist, dass diese Engine immer noch:
- Seiten lädt und das DOM rendert
- JavaScript ausführt und AJAX verarbeitet
- Cookies verwaltet
- sich einloggt und auf Buttons klickt
Aber anstatt dass Sie klicken, übernimmt Ihr Code das Klicken. Das ist alles.
Und genau das verschafft Ihnen einen unfairen Vorteil beim Web Scraping, bei der Automatisierung, bei QA-Tests und vielem mehr.
Um es noch deutlicher zu machen, stellen Sie sich das so vor:
- Normaler Browser: Sie öffnen Chrome, klicken, scrollen, tippen und die Daten werden geladen
- Headless Browser: Ihr Skript klickt, scrollt, tippt und die Daten werden geladen
Jetzt wissen Sie, was ein Headless Browser ist. Schauen wir uns also an, wie er tatsächlich funktioniert.
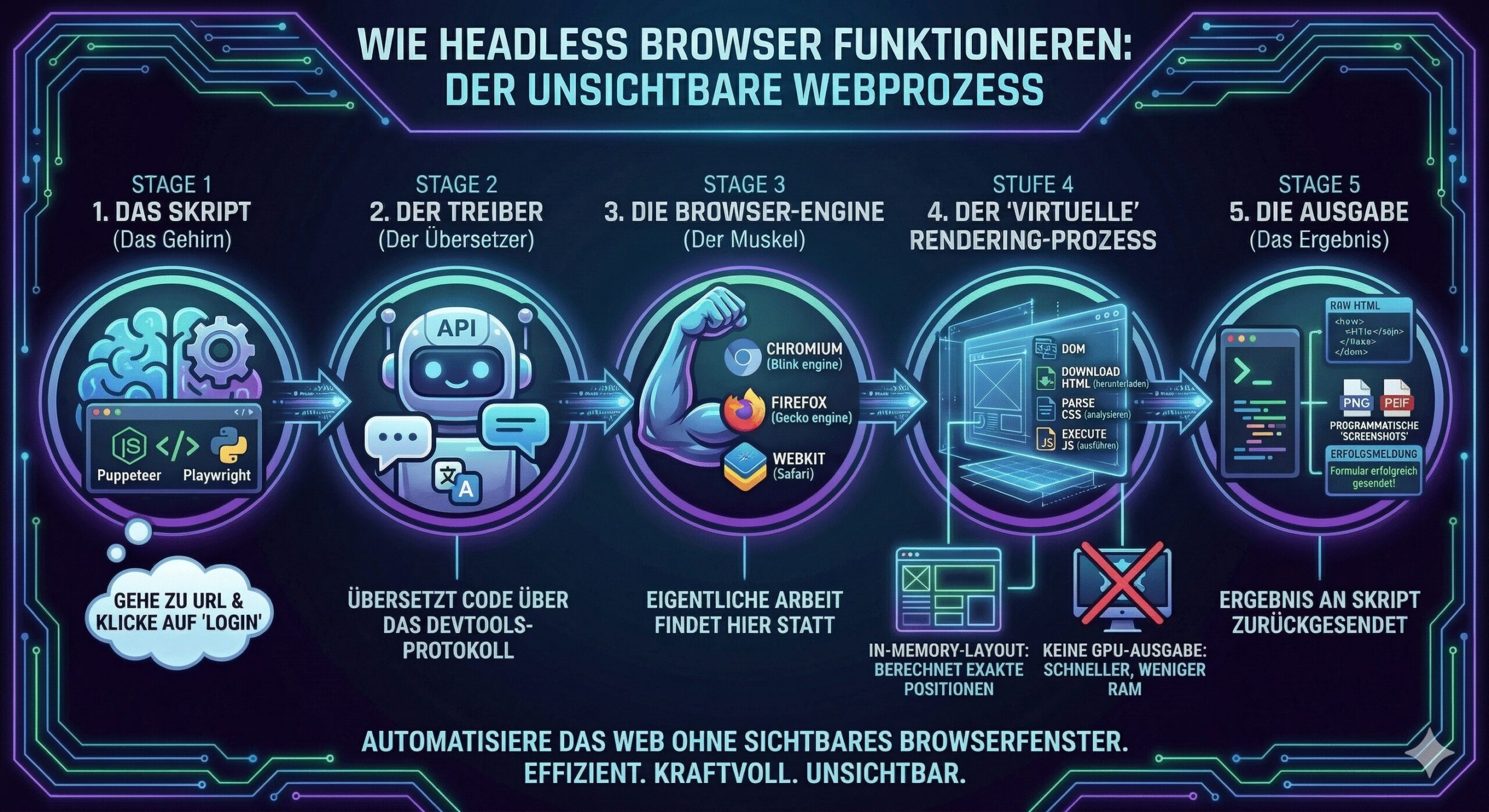
Warum cURL und Requests bei modernen Websites scheitern
Lassen Sie mich Ihnen zunächst das Problem zeigen, bevor wir mehr über Headless Browser lernen.
Angenommen, Sie versuchen Folgendes:
Und was Sie erwarten, sind JSON- oder HTML-Daten.
Stattdessen erhalten Sie:
Aber warum? Weil die Seite wie folgt geladen wird:
- Schritt 1: Der Server sendet eine leere Hülle
- Schritt 2: JavaScript wird ausgeführt
- Schritt 3: JS ruft die API ab
- Schritt 4: JS rendert die Produkte
Aber cURL führt Schritt 2 niemals aus. Es sieht also nie Schritt 3 oder 4.
Das ist der Grund, warum Requests fehlschlagen, HTML-Parser versagen und somit das Scraping scheitert.
Nicht, weil Sie etwas falsch machen, sondern weil Sie nicht innerhalb eines Browsers arbeiten.
Und Headless Browser beheben genau dieses Problem. Um es klarer auszudrücken, hier sind die Schritte, auf die sich Headless Browser konzentrieren:
- die Seite öffnen
- JavaScript ausführen
- warten, bis alles geladen ist
- dann die Daten extrahieren
Ja, genau wie ein menschlicher Browser, und das ist es, was beim Web Scraping, der Automatisierung, bei QA-Tests und anderen Aufgaben hilft.
Einen Headless Browser wählen (wie Headless Chrome) und Ihr erstes Skript ausführen
Jetzt wissen Sie, was ein Headless Browser ist und welches Problem er löst.
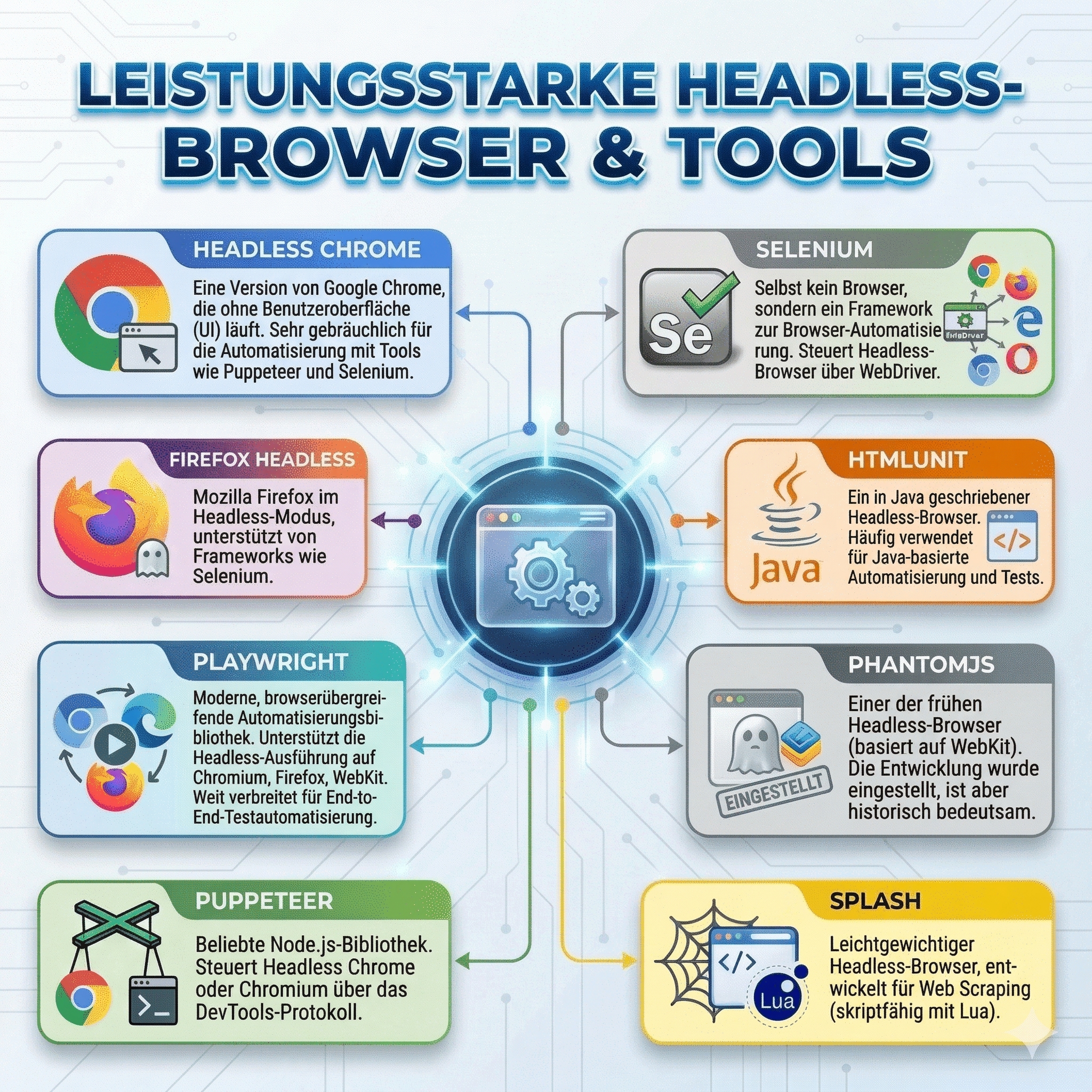
Dank dieser Technologie stehen uns verschiedene Headless Browser Tools zur Verfügung, von denen einige besonders beliebt sind.
Von all diesen Tools sind die folgenden am bekanntesten und am weitesten verbreitet:
Mehrere unabhängige Benchmarks und Tool-Guides zeigen, dass beim Vergleich Playwright vs Puppeteer beide in der Ausführungsgeschwindigkeit in der Regel Selenium übertreffen. Das liegt daran, dass sie direkt über das DevTools-Protokoll mit dem Browser kommunizieren, während die WebDriver-Schicht von Selenium zusätzlichen Overhead erzeugt.
Lassen Sie uns nun Playwright ausprobieren und unser erstes Headless-Browser-Skript ausführen.
Zuerst installieren:
npm install playwright
Und dann führen Sie den folgenden Code aus:
Nitin, was ist gerade passiert?
Nun, Ihr Skript hat Chrome gestartet, die Seite geöffnet, gewartet, bis sie gerendert wurde, die Daten extrahiert und dann den Browser geschlossen.
Es hat genau das getan, was Sie manuell tun würden, jedoch auf automatisierte Weise.
Wenn Sie es selbst ausprobieren möchten, führen Sie den folgenden Code aus:
Aber hier ist das Problem, über das niemand spricht
Hier ist der Teil, den die meisten Tutorials bequemerweise überspringen, da die meisten von ihnen Headless Browser nicht wirklich in realen Szenarien entwickeln und nutzen.
Ohne Zweifel sind Headless Browser wahnsinnig leistungsstark.
- Sie können JavaScript-lastige Apps rendern.
- Sie verhalten sich wie echte Nutzer.
- Sie funktionieren wunderbar in Serverless-Setups.
- Sie skalieren mit Proxys und ermöglichen es Ihnen, das Web Scraping zu automatisieren und zu beschleunigen.
Aber in der Praxis werden sie langsam mühsam und kompliziert.
Denn die Verwendung eines Headless Browsers ist niemals einfach nur „Headless Browser nutzen → Daten extrahieren → fertig“.
Es fängt einfach an, aber dann holt einen die Realität ein.
- Zuerst fügen Sie Wiederholungsversuche (Retries) hinzu, weil Requests zufällig fehlschlagen.
- Dann Proxys, weil Sie blockiert werden.
- Dann CAPTCHA-Handling, weil Cloudflare auftaucht.
- Dann Paginierungs-Logik, Login-Sitzungen, Rate Limiting.
- Dann Logging, Zeitplanung (Scheduling) und Exporte.
Und bevor Sie es merken, wird Ihr niedliches kleines 30-Zeilen-Skript zu 800 Zeilen Code.
An diesem Punkt „scrapen Sie nicht mehr nur eine Website“. Sie bauen im Grunde ein Mini-Scraping-Framework.
Sie sehen, am Ende verbringen Sie mehr Zeit mit dem Aufbau und der Wartung des Scrapers als mit dem eigentlichen Scraping der Daten.
Das sind die versteckten Kosten von Headless Browsern, von denen Ihnen niemand erzählt.
Und genau hier fangen Tools wie Octoparse an, sehr viel mehr Sinn zu machen.
Octoparse: Eine einfachere Alternative für automatisierte Datenerfassung
Nitin, was ist Octoparse? Nun, es ist eine No-Code-Lösung für Web Scraping, die für Sie mehr sein kann als nur ein reiner Headless Browser.
Aber wie? Zunächst einmal kümmert es sich um die Dinge, über die Sie nicht nachdenken wollen:
- Verwaltung mehrerer Browser-Instanzen
- Warteschlangen, Wiederholung fehlgeschlagener Läufe, Proxy-Handling und Rate Limiting
- CAPTCHA-Lösung und andere Maßnahmen gegen Bot-Erkennung
- Anpassung von Browser-Fingerprints und Request-Mustern, damit das Scraping menschlich wirkt und eine Entdeckung vermieden wird
- Zeitplanung, Cloud-Ausführung und Datenexport ohne das Schreiben von Code
Und das Beste daran? Es entscheidet basierend auf der Website, wie Ihre Aufgabe ausgeführt wird:
- nutzt eine leichtgewichtige Engine für einfache Seiten
- wechselt bei Bedarf zu vollständigen Headless- (oder sogar sichtbaren) Browsern
- wählt automatisch den stabilsten und kosteneffizientesten Ansatz
Sie sehen, es ist nicht nur eine visuelle Ebene über Headless Browsern, es verwaltet und steuert tatsächlich, wie diese ausgeführt werden.
Und genau das macht den Prozess so leicht verständlich und nachvollziehbar.
Um loszulegen, besuchen Sie einfach die offizielle Octoparse-Website, klicken Sie auf den Button „Start a free trial“, um Ihr Konto zu erstellen, und können anschließend die Web-Scraping-App herunterladen.
Anschließend können Sie eine benutzerdefinierte Aufgabe erstellen oder eine der vorgefertigten Scraping-Vorlagen verwenden, um Daten mit den von Ihnen benötigten Funktionen zu extrahieren.
Wenn also Ihr Ziel ist:
- 1.000 Seiten zu scrapen
- dies täglich auszuführen
- nach CSV zu exportieren
- und komplexe Logik zu vermeiden
Dann ist Octoparse in der Regel alles, was Sie brauchen, und Ihre Arbeit wird ohne Kopfschmerzen erledigt. Für die meisten geschäftlichen Anwendungsfälle ist das mehr als genug.
Wann Sie einen Headless Browser verwenden sollten (und wann nicht)
Jetzt wissen Sie, was ein Headless Browser ist, warum er existiert und wie Sie anfangen können, aber die meisten Anfänger nutzen ihn immer noch falsch.
Sie setzen Headless Browser überall ein, obwohl man sie in Wirklichkeit nur dann verwenden sollte, wenn sie auch tatsächlich benötigt werden.
Um genauer zu sein, verwenden Sie einen Headless Browser, wenn:
- die Website stark auf JavaScript angewiesen ist
- ein Login erforderlich ist oder Formulare abgeschickt werden müssen
- es Infinite Scroll (endloses Scrollen) gibt
- Klicks auf Buttons erforderlich sind, um Daten zu laden
- Sie es mit dynamischen Dashboards zu tun haben
- die Website über Anti-Bot-Schutzmaßnahmen verfügt
- Sie Screenshots oder PDF-Generierungen benötigen
Aber Nitin, wann sollte man ihn nicht verwenden? Verwenden Sie keinen Headless Browser, wenn die Website statische HTML-Seiten ausliefert, eine einfache API Ihnen bereits die Daten liefert oder Sie schnelles Bulk-Scraping mit minimalem Overhead benötigen.
Aber wann sollten Sie cURL, einen Headless Browser und Octoparse verwenden? Nun, hier ist das einfache mentale Modell, das ich nutze:
- Verwenden Sie cURL oder einfache HTTP-Clients, wenn es eine saubere API oder statisches HTML gibt. Das ist am schnellsten und verursacht den geringsten Overhead.
- Verwenden Sie Playwright oder Puppeteer, wenn Sie die volle Kontrolle benötigen. Für komplexe Abläufe, benutzerdefinierte Logik, tiefe Integrationen oder alles, bei dem Sie jeden Schritt kontrollieren möchten.
- Verwenden Sie Octoparse, wenn das eigentliche Problem nicht lautet „wie scrape ich“, sondern „wie führe ich das zuverlässig jeden Tag im großen Maßstab aus“. Sie wissen, dass es Browser-Orchestrierung, Infrastruktur und Anti-Bot-Details handhaben kann, wobei je nach Bedarf eine Mischung aus WebView, Headless- und Headed-Modus verwendet wird.
FAQs über Headless Browser
1. Sind Headless Browser langsamer als normale Scraping-Bibliotheken?
Ja, denn ein Headless Browser startet unter der Haube buchstäblich Chrome (als Headless Chrome) oder Firefox.
Das bedeutet eine höhere Speichernutzung, mehr CPU-Verbrauch, langsamere Startzeiten und weniger gleichzeitige Aufgaben.
Im Vergleich zu einfachen Bibliotheken wie Requests oder direktem API-Zugriff sind Headless Browser also immer langsamer.
2. Welches Tool sollte ich wählen: Playwright, Puppeteer oder Selenium?
Wenn Sie heute anfangen, nutzen Sie einfach Playwright. Es ist schneller, moderner und unterstützt von Haus aus mehrere Browser.
Puppeteer ist ebenfalls großartig, aber hauptsächlich auf Chrome fokussiert. Selenium ist auch leistungsstark, fühlt sich aber schwerfälliger und älter an, es sei denn, Sie benötigen es speziell für Enterprise-Tests.
3. Können Headless Browser blockiert oder erkannt werden?
Absolut. Websites können Headless Browser weiterhin anhand von Signalen wie zu vielen Anfragen, unnatürlichem Verhalten, fehlenden Verzögerungen, wiederholten IP-Adressen oder unvollständigen Headern erkennen.
4. Wann sollte ich auf Headless Browser verzichten und stattdessen etwas wie Octoparse verwenden?
Wenn Ihr Ziel darin besteht, Tausende von Seiten zu scrapen, tägliche Jobs auszuführen, Daten nach CSV oder Excel zu exportieren und Sie keine benutzerdefinierte Entwicklungslogik benötigen, dann ist Octoparse die bessere Wahl.
Die Verwendung von Playwright oder Puppeteer wird in diesem Fall einfach Ihre Zeit verschwenden, und Sie werden wahrscheinlich Wochen damit verbringen, etwas zu debuggen, das ein visuelles Tool in 20 Minuten lösen kann.



