Die gecrawlten Daten können zur Bewertung oder Vorhersage in verschiedenen Bereichen verwendet werden. Hier möchte ich 3 Methoden vorstellen, die wir zum Crawlen der Daten aus einer Website einsetzen können.
Was ist ein Daten Crawler?
Crawler, auch bekannt als Webcrawler, sind Software-Programme, die das Internet durchsuchen. Sie sammeln und speichern Inhalte von Websites wie Texte, Bilder und Videos. Vor allem Suchmaschinen-Provider nutzen Crawler, um Websites zu indizieren.
Website-APIs verwenden
Viele große Social Media Websites wie Twitter, Instagram und Stack Overflow bieten APIs an, damit Nutzer auf Daten zugreifen können. Sie können die offiziellen APIs wählen, um strukturierte Daten zu erhalten.
Wie die Twitter API unten zeigt, können Sie nach Bedarf die API einstellen. Die Einführung der Twitter API und andere Details finden Sie unter: https://developer.twitter.com/en/docs/twitter-api
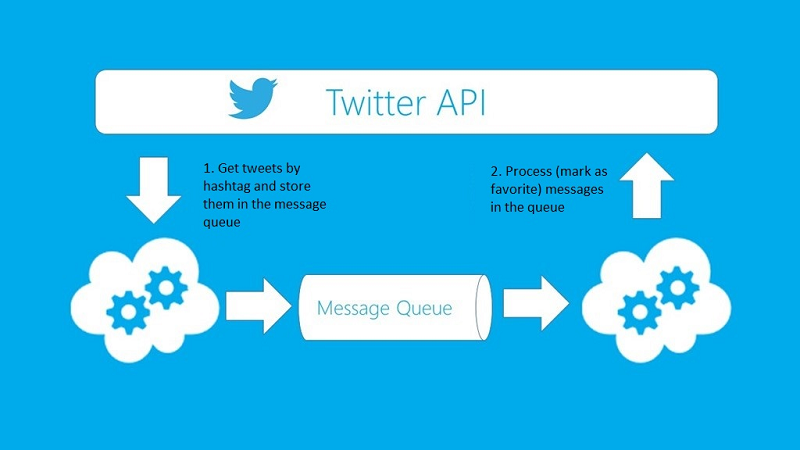
Andere API:
| API | Website |
| Facebook API | https://developers.facebook.com/docs/graph-api/ |
| Instagram API | https://developers.facebook.com/docs/instagram-api/ |
| WhatsApp API | https://developers.facebook.com/docs/whatsapp/ |
| Google API | https://developers.google.com/apis-explorer |
| Google Maps API | https://developers.google.com/maps?hl=de |
| You Tube API | https://developers.google.com/youtube/v3 |
| Twitter API | https://developer.twitter.com/en/docs/twitter-api |
| Spotify API | https://developer.spotify.com/documentation/web-api/ |
| LinkedIn API | https://developer.linkedin.com/ |
| Reddit API | https://www.reddit.com/dev/api/ |
Eigenen Crawler erstellen
Allerdings stellen nicht alle Websites den Nutzern APIs zur Verfügung. Einige Websites weigern sich, öffentliche APIs zur Verfügung zu stellen, weil sie technische Beschränkungen haben. Es kann sein, dass jemand RSS-Feeds vorschlägt, aber die Nutzung wird eingeschränkt, deswegen werde ich das nicht vorschlagen. In diesem Fall möchte ich darauf hinweisen, dass wir selbst einen Crawler bauen können, um mit dieser Situation umzugehen.
Wie funktioniert ein Crawler?
Ein Crawler ist eine Methode zur Erstellung einer Liste von URLs, das Sie in Ihrem Extraktor erstellen können. Die Crawler können als Werkzeuge zum Auffinden der URLs definiert werden. Sie geben dem Crawler zunächst eine Webseite als Startpunkt vor, und er wird allen Links auf dieser Seite folgen. Dieser Prozess wird dann in einer Schleife fortgesetzt.
Dann fahren wir mit dem Aufbau unseres eigenen Crawlers fort. Es ist bekannt, dass Python eine Open-Source-Programmiersprache ist, und Sie können viele nützliche funktionale Bibliotheken finden. Hier schlage ich BeautifulSoup (Python Library) vor, weil es einfacher zu benutzen ist, und viele intuitive Eigenschaften besitzt. Genauer gesagt, werde ich zwei Python-Module verwenden, um Daten zu crawlen.
BeautifulSoup crawlt die Webseite nicht für uns. Deshalb verwende ich urllib2 zur Kombination mit der BeautifulSoup-Bibliothek. Dann muss ich mit HTML-Tags arbeiten, um alle Links innerhalb der <a>-Tags der Seite und die richtige Tabelle zu finden. Danach müssen wir jede Zeile (tr) durchlaufen und dann jedes Element von tr (td) einer Variablen zuweisen und an eine Liste anhängen. Schauen wir uns zunächst die HTML-Struktur der Tabelle an (ich werde keine Informationen für die Tabellenüberschrift <th> extrahieren).
Mit der Methode wird Ihr Crawler angepasst. Er kann mit bestimmten Schwierigkeiten bei der API-Extraktion umgehen. Sie können den Proxy verwenden, um zu verhindern, dass er von einigen Websites blockiert wird, usw. Der gesamte Prozess liegt in Ihrer Hand. Diese Methode sollte für Personen mit Programmierkenntnissen sinnvoll sein. Der von Ihnen gecrawlte Datenrahmen sollte wie in der Abbildung unten aussehen.
Gebrauchsfertige Crawler-Tools verwenden
Allerdings kann es sehr zeitaufwändig sein, eine Website selbst durch Programmierung zu crawlen. Für Menschen ohne Programmierkenntnisse wäre dies eine schwierige Aufgabe. Deshalb möchte ich einige Crawler-Tools vorstellen.
1. Octoparse ⭐⭐⭐⭐⭐
Octoparse ist ein leistungsstarker visueller Web-Crawler. Mit seiner einfachen und freundlichen Benutzeroberfläche ist es für die Benutzer wirklich einfach, dieses Tool zu verstehen. Um es zu verwenden, müssen Sie diese Anwendung auf Ihren lokalen Desktop herunterladen.
Wie die Abbildung unten zeigt, können Sie die Blöcke im Workflow-Designer-Fenster anklicken und ziehen, um Ihre eigene Aufgabe anzupassen. Octoparse bietet nicht nur kostenpflichtige, sondern auch kostenlose Version. Beide können die grundlegenden Scraping- oder Crawling-Bedürfnisse der Benutzer erfüllen. Mit der Testversion können Sie Ihre Aufgaben auf dem lokalen Gerät ausführen.
✔️ Point & Click Interface
Octoparse kommt mit einer benutzerfreundlichen UI. Es ermöglicht Ihnen, die Interaktion mit Ihren bevorzugten Websites in seinem intergrierten Browser mit Point-und-Click-Aktionen zu verwirklichen.
✔️ Erweiterte Funktionen
Mit vielen leistungsstarken Funktionen hilft Octoparse Ihnen bei der Erleichterung des Artikel Scrapings, wie z.B. bei dem unendlichen Scrollen der Website, dem Behalten des Einloggen-Status und der Suche nach Stichwörter.
✔️ Cross-Plattform
Bei der Verwendung von Octoparse findet man es sehr günstig, dass Octoparse nicht nur mit Windows sondern auch mit Mac OS kompatibel ist. Sie können Octoparse einfach von octoparse.de herunterladen und die zu Hande nehmenden Vorlagen für Artikel Scraping. Vor dem Versuch können Sie zuerst die Tutorials durchschauen und dann einen Crawler erstellen.
✔️ Acceleration & Scheduling
Octoparse verfügt über einen Boost-Modus, der die Geschwindigkeit des Artikel-Scrapings sowohl auf lokalen Geräten als auch in der Cloud erheblich verbessert. Wenn Sie schnell und einfach aktuelle Artikel auslesen möchten, können Sie einen Scraper nach Ihrem Zeitplan wöchentlich täglich sogar stündlich einstellen.
✔️ Kundenservice
Das Octoparse-Team bietet auch einen hervorragenden Kundensupport und ist bestrebt, Ihnen bei allen Arten von Datenanforderungen zu helfen. Wenn die vorhandenen Vorlagen Ihre Wünsche nicht erfüllen, kann das Team auch nach Ihren Datenerfordeungen einen kundenspezifischen Daten Scraper entwickeln.
Hier nehmen wir ein Bespiel 👉 Gelbe Seiten Scraper: Wie kann man Leads aus gelbeseiten.de scrapen?
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs
2. WebHarvy ⭐⭐⭐⭐
WebHarvy ist eine weitere kundenorientierte Artikel Scraping-Software, aber erfordert Windows-Betriebssystem. Es kann verwendet werden, um Artikelverzeichnisse und Pressemitteilungen von PR-Websites zu durchsuchen.
✔️ Einfache Erklärungsserie
Sie können die Erklärvideos auf der offiziellen Website von WebHarvy ansehen, wie Sie eine Aufgabe erstellen können, um den Titel, den Namen des Autors, das Veröffentlichungsdatum, Schlüsselwörter und den Haupttext eines Artikels zu scrapen. Wenn Sie neu im Web Scraping sind, könnten sie ein guter Ausgangspunkt sein.
✔️ Evaluation Verison
Es wird sehr empfohlen, die Testversion herunterzuladen und die grundlegenden Tutorial-Videos anzusehen, um Ihre Datenreise zu starten. Es ist sehr einfach zu bedienen und unterstützt auch Proxies und geplantes Scraping. Wenn es Ihre Datenanforderungen erfüllen kann, können Sie Single User License von WebHarvy für nur 139 USD erwerben.
3. ScrapeBox ⭐⭐⭐
Als eines der leistungsfähigsten und beliebtesten SEO-Tools hat ScrapeBox ein Artikel-Scraper-Addon, mit dem Sie Tausende von Artikeln aus einer Rihe beliebter Artikelverzeichnisse ernten können.
✔️ Lightweight Add-on
Als leichtgewichtiges Addon bietet das Artikel-Scraper-Addon von ScrapeBox:
🔹 Proxy-Unterstützung
🔹 Multithreading für schnelles Abrufen von Artikeln
🔹 Rechungsfähigkeit für die gesamtliche Anzahl der gescrapten Artikeln.
🔹 Datenspeicherung in ANSI, UTF-8 oder Unicode-Format.
✔️ Keyword-based Filter
Mit ScrapeBox kann man auch die Links und E-Mail-Adressen automatisch aus Artikeln entfernen lassen. Die abgerufenen Artikeln können auch nach den Stichwörter kategorisiert werden.
Zusammenfassung
Wir können Daten effizient crawlen, indem wir Website-APIs nutzen, unsere eigenen Crawler erstellen oder Standard-Crawler-Tools verwenden. Jede der drei in diesem Artikel genannten Methoden hat ihre eigenen Vorteile, und Sie können je nach Ihrem persönlichen technischen Hintergrund und Ihren spezifischen Bedürfnissen die am besten geeignete Methode wählen. Ganz gleich, ob es sich um eine tiefgreifende Anpassung durch Programmierkenntnisse handelt oder um die Straffung des Prozesses mit benutzerfreundlichen Tools, sie können uns helfen, Webdaten effizient zu sammeln und zu nutzen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



