Bilder sind oft das bevorzugte Medium für die Darstellung von Informationen auf der Website, und Sie möchten vielleicht alle Bilder von der Website speichern. Es ist jedoch etwas schwierig, die Bilder allein von der Website zu extrahieren, da es viele andere Medien auf der Website gibt. Hier werden wir über die kostenlosen Bilder Crawlers sprechen, um Ihre speziellen Bedürfnisse zu befriedigen.
Bilder spielen eine wichtige Rolle bei der Informationsdarstellung auf Websites. Wenn Sie alle Bilder einer Website speichern möchten, können spezielle Tools wie Browser-Erweiterungen oder Web-Scraping-Tools wie Octoparse Ihre Arbeit erheblich erleichtern.
Browser-Tools zum Scrapen der Bilder
1. extract.pics
extract.pics ist ein weiteres ausgefallenes Tool mit einer einfachen und klaren Benutzeroberfläche. Das Beste daran ist, dass Sie die Möglichkeit haben, alle Bilder vor dem Herunterladen in einer Vorschau anzusehen und sie auszuwählen oder abzuwählen. Allerdings können Sie auf diesen Fehler stoßen, wenn Sie versuchen, alle Bilder mit einem Klick herunterzuladen.
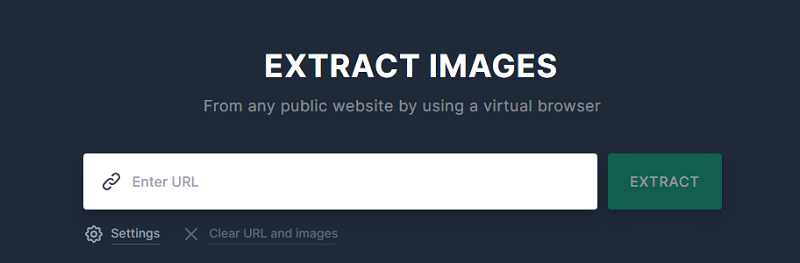
2. Chrome-Erweiterung: Image Downloader
- Schritt 1: Öffnen Sie das Erweiterungsprogramm.
- Schritt 2: Wählen Sie “Select all” und dann “Download“.
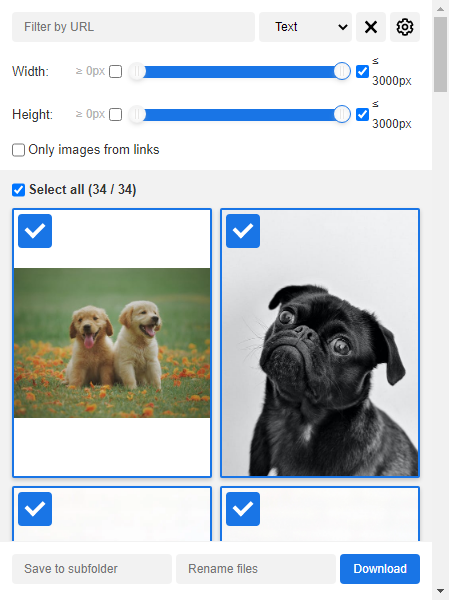
3. Image Cyborg
Mit diesem Tool können Sie die Bilder der Ziel-Website in Sekunden herunterladen, aber das ist nur geeignet für einzelne Seite. Wenn Sie Bilder mehrerer Webseiten von einer Website extrahieren möchten oder neben den Bildern auch die Daten benötigen, die mit der Bilder zusammenhängen (z. B. die Produktnamen und die Preise der Produkte), ist das Web Scraping-Tool eine bessere Wahl für Sie.
Web Scraping Tool zum Erstellen eines Bilder-Crawlers
Es gibt verschiedene Web-Scraping-Tools sowohl für Menschen, die keine Programmierkenntnisse haben, als auch für Programmierer. Hier stellen wir Ihnen Octoparse, ein Web-Scraping-Tool ohne Programmierung vor.
Im Vergleich zu dem Download der einzelnen Webseite hilft Ihnen Octoparse, die URLs der benötigten Bilder zu erhalten. Dann können Sie die Bilder einfach in großen Mengen herunterladen. Dann schauen wir uns an, wie man einen Bild Scraper mit Octoparse erstellen kann. Hier nehmen wir die Bilder auf der Website mit Link https://www.amazon.com/ref=nav_logo?language=de_DE¤cy=USD als Beispiel.
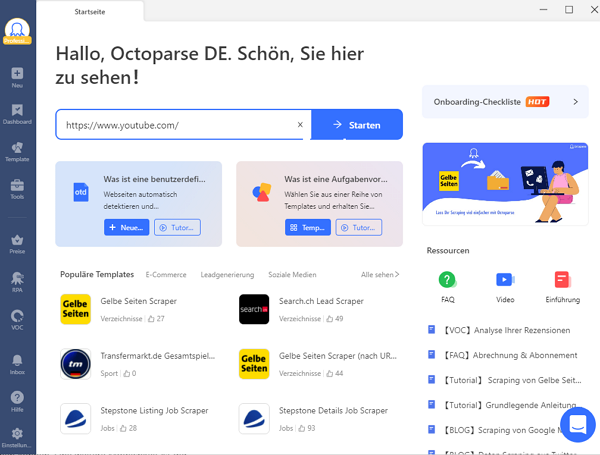
Schritt 1: Öffnen Sie Octoparse und geben die URL der Webseite ein.
- Wenn Sie Octoparse noch nicht heruntergeladen haben, dann gehen Sie bitte zu dieser Download-Seite.
- Geben Sie die URL in den Suchkasten ein und klicken auf “Start”, um eine Aufgabe yu erstellen.
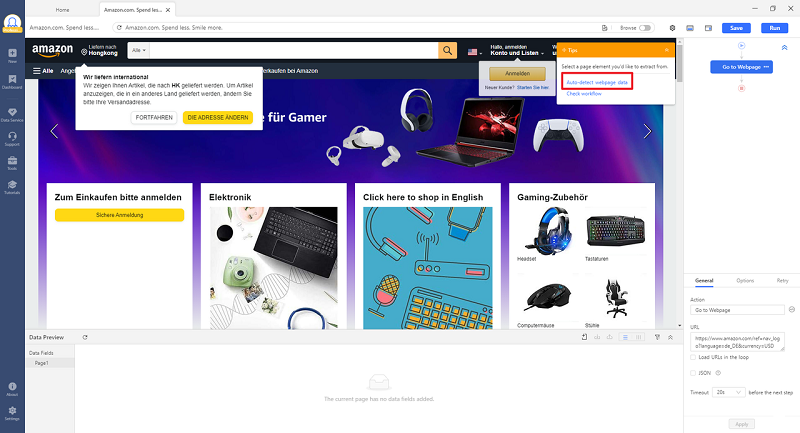
Schritt 2: Lassen Sie Octoparse die Daten automatisch detektieren und konfigurieren Sie die Aufgabe weiter.
- Wählen Sie zuerst “Auto-detect webpage data”.
- Dann werden die URL von allen Bildern auf der Seite im Vorschaufenster dargestellt.
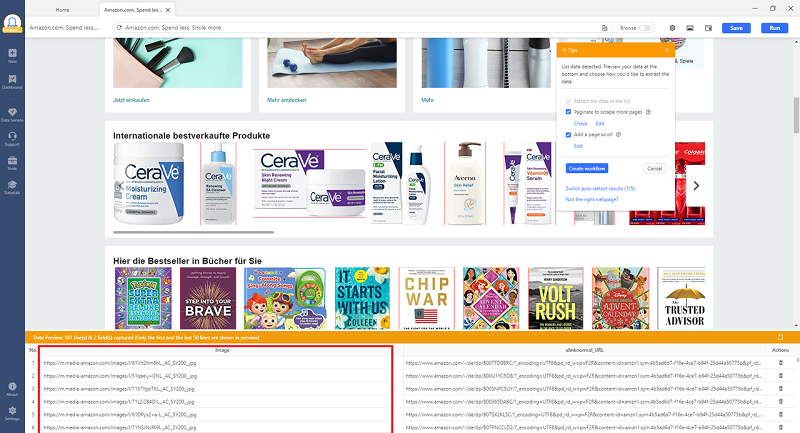
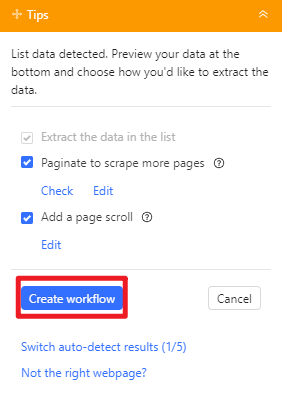
- Dann klicken Sie auf “Create workflow”, um einen Workflow für die spätere Konfiguration der Aufgabe zu erstellen.
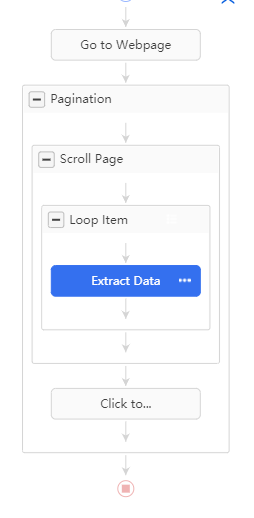
- Überprüfen Sie den Workflow und stellen die Datenfelder ein.
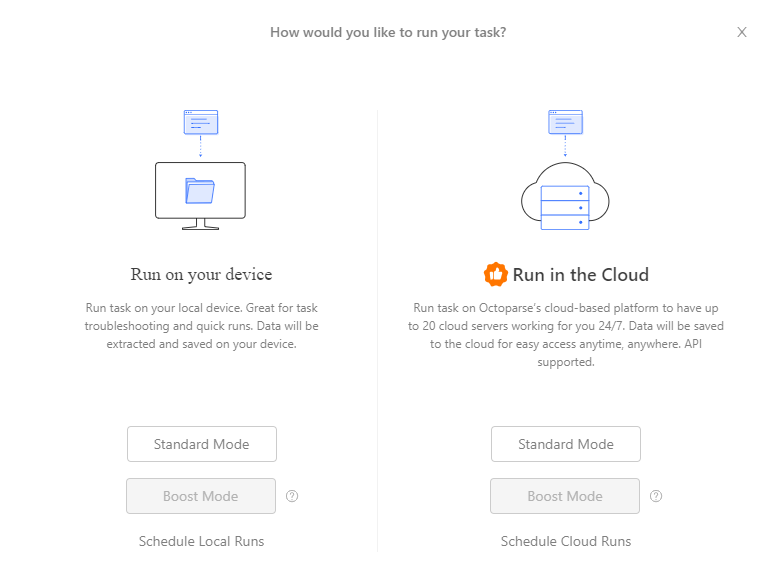
Schritt 3: Führen Sie die Aufgabe aus und geben die Daten aus.
- Klicken Sie auf “Save”>>“Run” und führen Sie die Aufgabe aus.
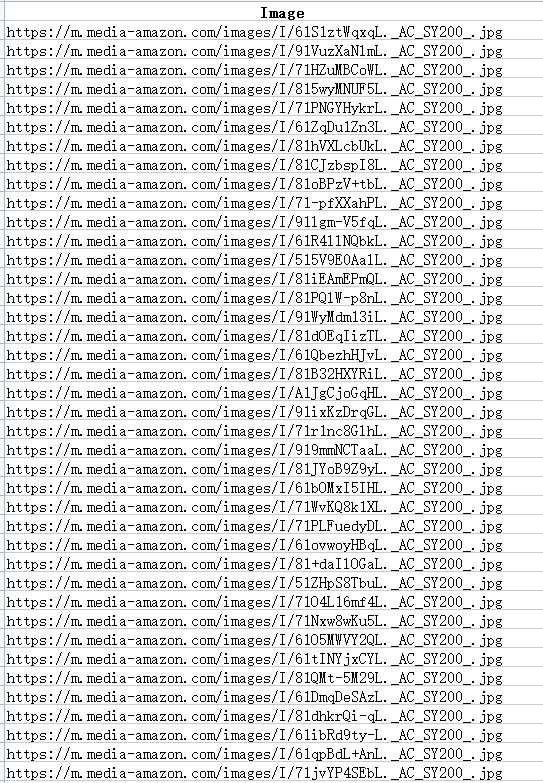
- Hier ist ein Beispiel der extrahierten URLs der Bilder.
Zusammenfassung
In diesem Artikel werden verschiedene kostenlose Tools zum Scraping von Bildern vorgestellt, darunter extract.pics, die Chrome-Erweiterung Image Downloader und Image Cyborg, mit denen Benutzer problemlos Bilder von Websites extrahieren können. Octoparse, ein Web-Scraping-Tool ohne Programmierkenntnisse, wird ebenfalls empfohlen, mit dem Benutzer die URLs von Bildern im Stapelverfahren abrufen und herunterladen können, indem sie Bild-Scraping-Aufgaben für eine effizientere Bilderfassung erstellen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



