List Crawling ist die mit Abstand häufigste Aufgabe bei der Web-Datenextraktion; mehr als 70 % aller Web-Datenextraktionsaufgaben betreffen Listen. Preisüberwachung, Wettbewerbsanalyse, Lead-Generierung – sie alle folgen wiederholbaren Mustern, die systematisch gecrawlt werden können.
Der schnellste Weg zum Erfolg besteht darin, list-crawling-freundliche Websites zu identifizieren, einen einheitlichen Satz von Extraktionsregeln auf jedes Element anzuwenden und von Anfang an Paginierung, Rate-Limits und Anti-Bot-Maßnahmen einzuplanen. Diese Anleitung zeigt Ihnen genau, wie das geht.
List Crawling vs. Allgemeines Web Crawling
List Crawling ist fokussiert und strukturiert. Anstatt jede Seite zu besuchen, zielen Sie auf eine bestimmte Gruppe von Seiten ab, die dasselbe Layout teilen – zum Beispiel eine Produktkategorie, eine Jobbörse oder eine Bewertungsliste – und extrahieren dieselben Felder aus jedem Element (Titel, Preis, Beschreibung usw.).
Allgemeines Web Crawling hingegen zielt darauf ab, so viele Seiten wie möglich zu besuchen und deren Inhalte zu indexieren – ähnlich wie Google das Internet crawlt, um Suchergebnisse zu erstellen. Es ist breit angelegt, wenig tiefgehend und darauf ausgelegt, Seiten zu entdecken.
Stellen Sie es sich so vor: Allgemeines Crawling = „Finde mir alles.“
List Crawling = „Sammle genau diese Art von Daten von jedem Element in dieser Liste.“
List Crawling umfasst in der Regel auch den Umgang mit Paginierung, unendlichem Scrollen und wiederkehrenden Mustern, während allgemeines Crawling einfach Links folgt, ohne sich um die Datenstruktur zu kümmern.
Welche Arten von Websites eignen sich am besten für List Crawling?
Nach dem Crawlen von Tausenden von Websites habe ich festgestellt, dass bestimmte Merkmale den Erfolg zuverlässig vorhersagen.
Kurzfassung: Wo Listings am häufigsten vorkommen
| Kategorie | Beispiele | Warum sie wichtig sind |
|---|---|---|
| Soziale Medien | Instagram-Profile, LinkedIn-Mitarbeiterverzeichnisse, Twitter-Hashtags | Wettbewerbsanalyse, Influencer-Marketing, Talent-Mapping |
| E-commerce | Amazon-Produktvariationen, abgeschlossene eBay-Angebote | Preisanalyse, Marktforschung |
| Professionelle Daten | AngelList-Finanzierungsrunden, GitHub-Repositories | Investitionsrecherche, Personalgewinnung |
| Lokal/Karten | Google Business-Einträge | Lokale SEO-Audits, Wettbewerbsbeobachtung |
1. E-Commerce und Produktkataloge
Wenn ich Websites wie Hersteller-Produktseiten oder Marktplatz-Listings besuche, achte ich auf
- Einheitliche Datenfelder über alle Einträge hinweg.
- Preis, Titel, Beschreibung und Bilder erscheinen an denselben Stellen mit minimalen Abweichungen.
- Klare Paginierungsmuster und vorhersehbare URL-Strukturen machen die systematische Extraktion unkompliziert.
Produktseiten gelten als der Goldstandard für List Crawling.
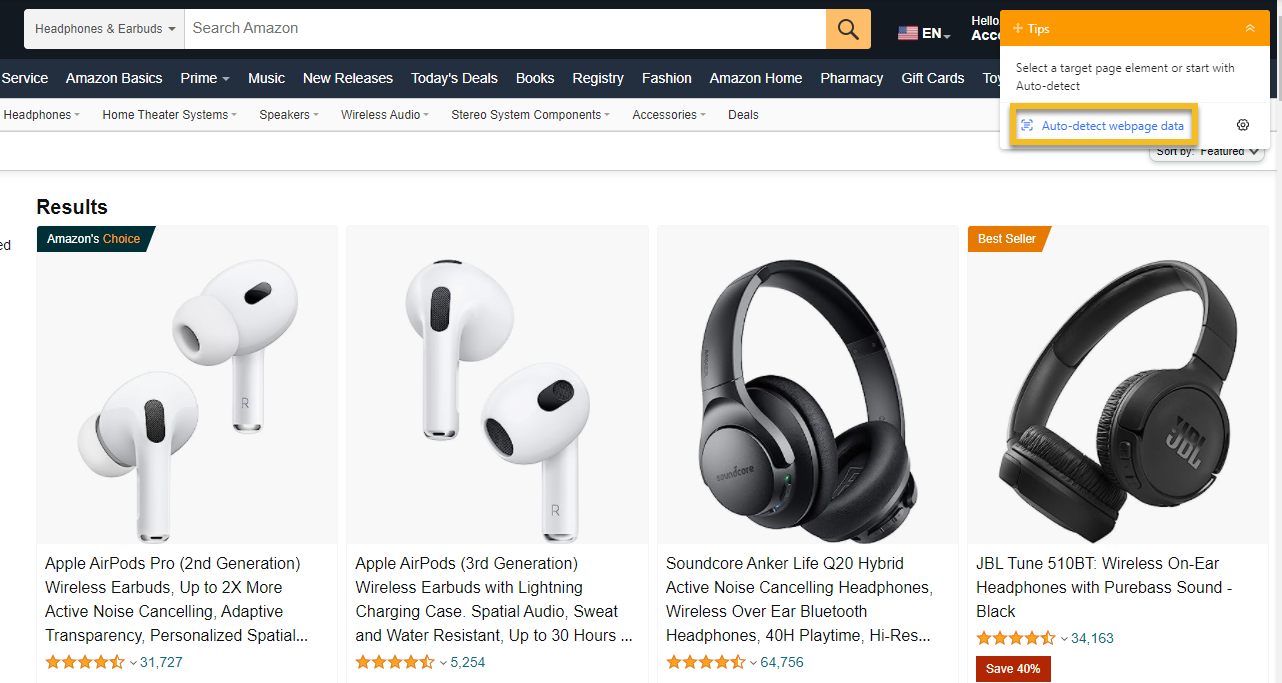
Jedes Produktlisting folgt derselben Vorlage, die Paginierung funktioniert vorhersehbar, und die Datenstruktur bleibt konsistent, selbst wenn sich das visuelle Design ändert.
2. Unternehmensverzeichnisse und Dienstleistungs-Listings
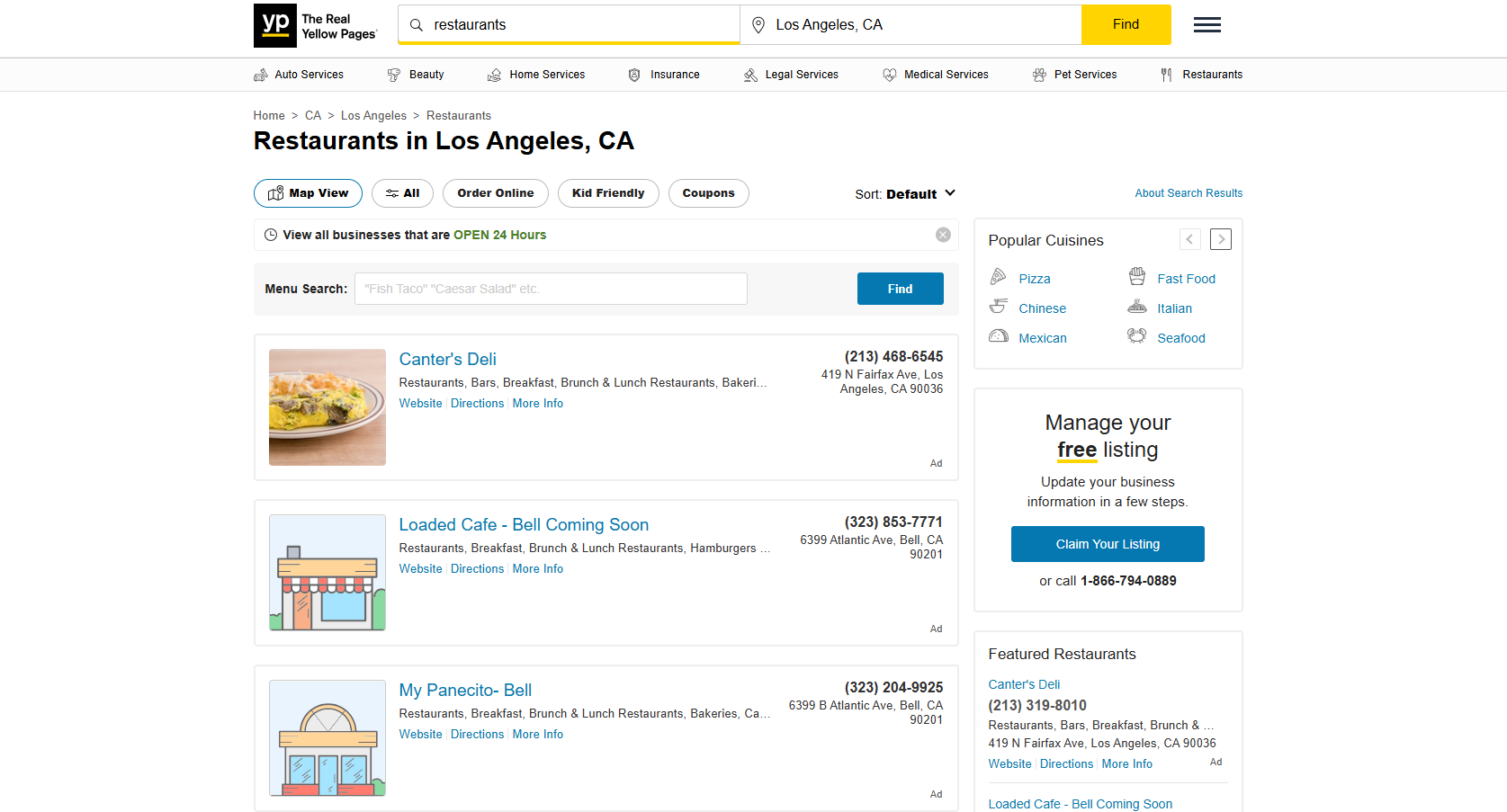
Listing-Seiten wie Yelp, Yellowpages.com oder Branchenverzeichnisse organisieren Unternehmensinformationen in einem standardisierten und leicht durchsuchbaren Format. Jeder Eintrag enthält in der Regel einheitliche Felder wie Kontaktdaten, Öffnungszeiten und Bewertungsdaten.
Wenn ich diese Verzeichnis-Websites analysiere, überprüfe ich, ob die Unternehmenseinträge dieselben Informationsfelder enthalten und ob die Organisation logisch bleibt. Darüber hinaus sollten geografische Filterung und Kategoriesuche auf der gesamten Website vorhersehbar funktionieren.
3. Jobbörsen und Karriere-Websites
Stellenausschreibungs-Websites verwenden standardisierte Formate, die eine zuverlässige Extraktion ermöglichen. Gehaltsinformationen, Standortdaten, Unternehmensdetails und Veröffentlichungsdaten erscheinen einheitlich in allen Listings.
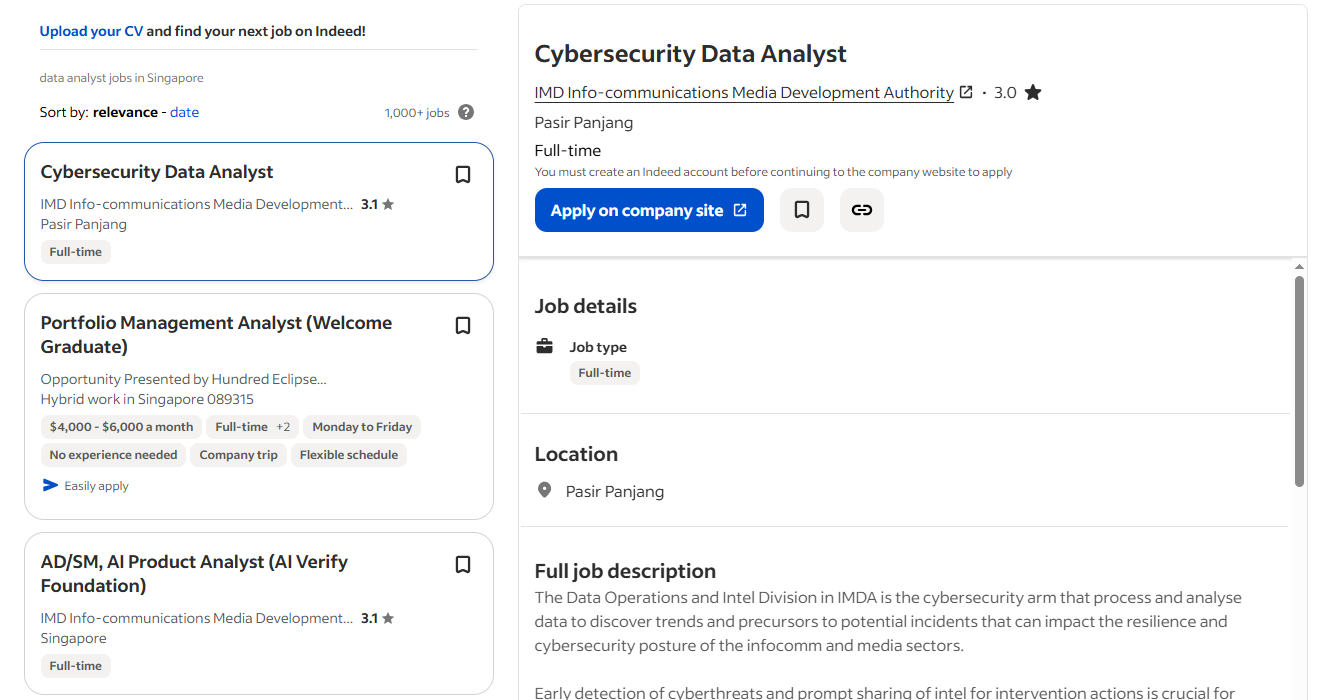
Ich habe ausgezeichnete Crawling-Ergebnisse mit Websites wie Indeed oder unternehmenseigenen Karriereseiten erzielt, da diese darauf angewiesen sind, dass Nutzer ähnliche Stellen schnell vergleichen können. Diese geschäftliche Anforderung erzwingt eine einheitliche Datendarstellung, was sie ideal für das Crawling macht.
4. Bewertungs- und Inhaltsplattformen
Bewertungsseiten präsentieren Nutzerfeedback in einheitlichen Strukturen mit konsistenten Bewertungssystemen und zeitlicher Organisation.
Nachrichtenaggregatoren und Inhaltsplattformen, wie Feedly oder Google News, verwenden standardisierte Artikelvorschauen mit Veröffentlichungsmetadaten.
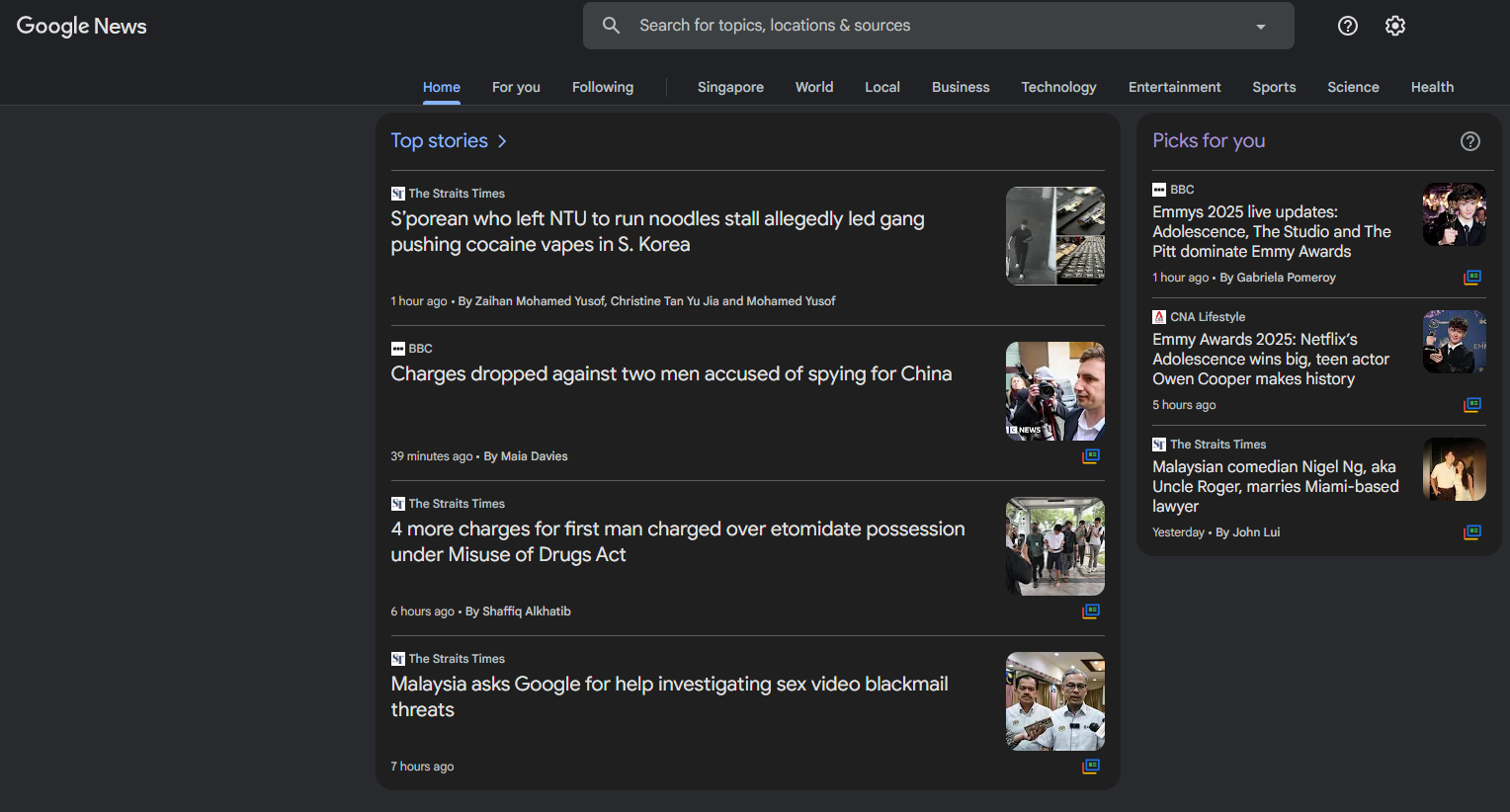
Der gemeinsame Nenner erfolgreicher Listing-Websites: Sie präsentieren ähnliche Informationen mit identischen Layouts. Wenn Sie dieselben Datenfelder mit minimaler Abweichung wiederholt sehen, haben Sie eine ideale List-Crawling-Website gefunden.
Wie erkennt man, ob die Listen einer Website crawlbar sind?
Bevor ich entscheide, ob ich eine Website list-crawlen kann, führe ich eine fünfminütige Bewertung durch. Diese Bewertung hilft mir zu entscheiden, ob die Website mit meinen Extraktionsversuchen kooperieren oder dagegen ankämpfen wird.
1. Seitenquelltext untersuchen
Um zum Seitenquelltext zu gelangen, können Sie einfach mit der rechten Maustaste auf ein beliebiges Listenelement klicken und den Seitenquelltext anzeigen. Suchen Sie dann nach HTML-Elementen, die Ihre Zieldaten enthalten, nach einheitlichen Klassennamen bei ähnlichen Elementen sowie nach strukturiertem Markup wie JSON-LD.
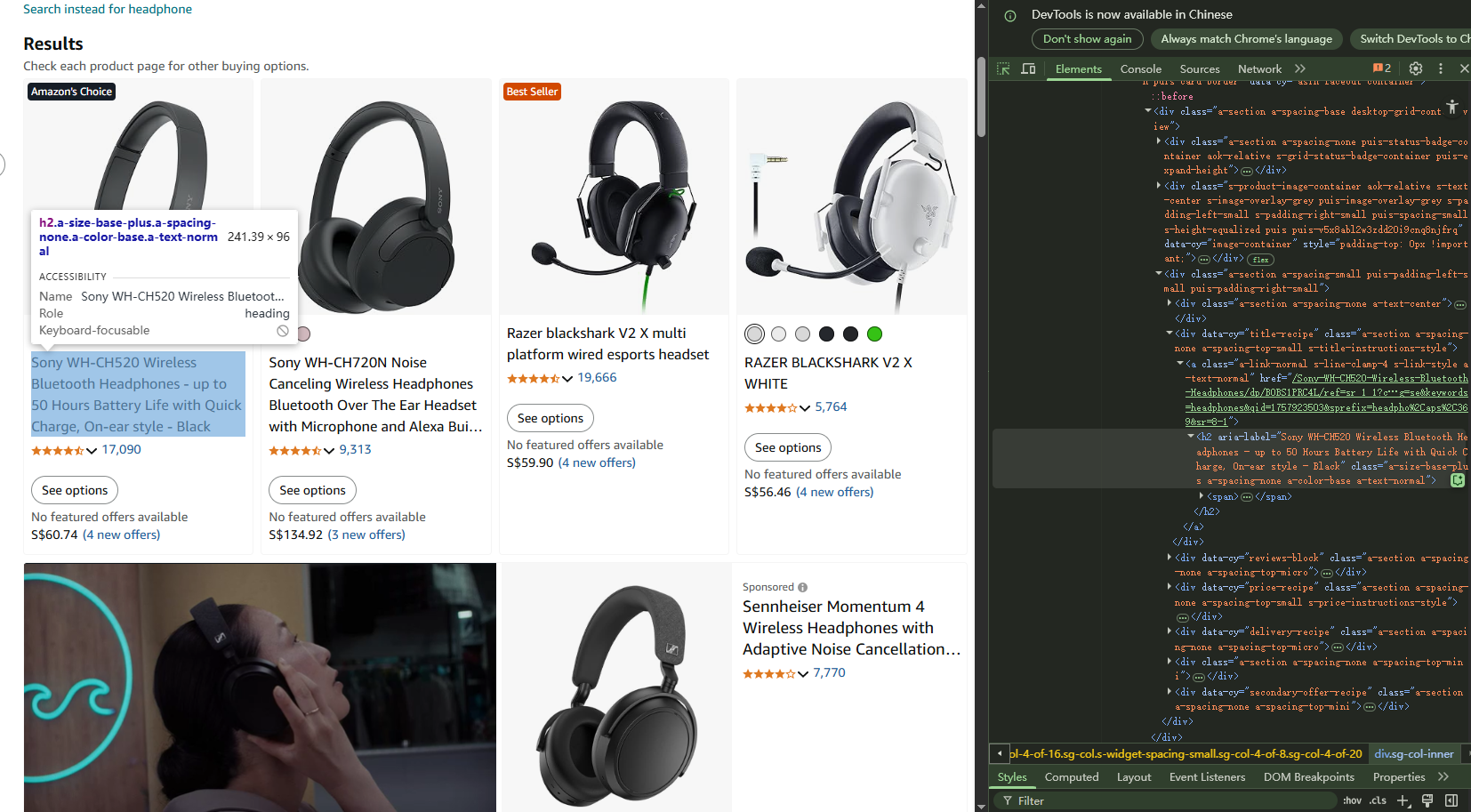
Wenn Sie Ihre Zieldaten im HTML-Quelltext klar erkennen können, ist die Seite crawlbar.
Hinweis: Leere Divs oder Platzhaltertext, der durch JavaScript befüllt wird, weist auf dynamische Inhalte hin, die ausgefeiltere Techniken erfordern.
2. URL-Strukturmuster überprüfen
Crawlbare Listen verwenden vorhersehbare URL-Muster für die Navigation. Ich empfehle, nach vorhersehbaren URL-Mustern bei der Paginierung zu suchen, wie zum Beispiel:
- example.com/products?page=1, das logisch zu page=2 fortschreitet, oder
- kategoriebasierte Strukturen wie example.com/electronics/p2.
Warnsignale sind URLs, die sich nicht ändern, oder solche mit komplexen JavaScript-generierten Tokens. Einmal verbrachte ich Tage auf einer Website, auf der alle Seiten dieselbe URL teilten, aber unterschiedliche Inhalte über JavaScript geladen wurden – die Paginierung war vollständig dynamisch.
3. Navigationsverhalten testen
Was ich tun würde, ist drei oder vier Seiten manuell durchzuklicken.
Seitenzahlen sollten konsistent funktionieren, die Browser-Zurück-Schaltfläche sollte ordnungsgemäß funktionieren, und Listenelemente sollten sofort ohne Verzögerungen geladen werden.
Wenn Sie fehlerhafte Paginierung, inkonsistente Navigation oder komplexe Ladesequenzen feststellen, muss Ihre Web-Crawler-Konfiguration möglicherweise angepasst werden, z. B. durch das Schreiben eines XPath für die Paginierung.
4. Rate-Limiting überprüfen
Öffnen Sie schnell fünf oder sechs Seiten in neuen Browser-Tabs.
Seiten, die nicht geladen werden, CAPTCHA-Abfragen anzeigen oder „Zu viele Anfragen”-Meldungen zeigen, weisen darauf hin, dass Ihr automatisiertes Crawling möglicherweise zu aggressiv ist.
List Crawling verschiedener Websites
Wenn ich mich nicht mit Programmierung und Debugging befassen möchte, bevorzuge ich Octoparse für das List Crawling, da es die technische Komplexität übernimmt und mir ermöglicht, mich auf das Abrufen der benötigten Daten zu konzentrieren.
Sie können es kostenlos herunterladen und es funktioniert unter Windows (eine Mac-Version ist ebenfalls verfügbar).
Verschiedene Websites strukturieren Listendaten unterschiedlich, daher passe ich meinen Ansatz immer an den jeweiligen Listentyp an, mit dem ich es zu tun habe. So gehe ich mit den drei häufigsten Listenstrukturen um:
1. Wie man tabellenbasierte Listen crawlt
Nachdem ich festgestellt habe, dass die Zieldaten eine Tabellenliste sind, öffne ich zunächst Octoparse. Ich klicke auf „Start with a URL” und füge die erste Seite der Liste ein, die ich crawlen möchte.
Die Software lädt die Seite in ihrem integrierten Browser, sodass ich genau sehen kann, womit ich es zu tun habe.
In diesem Fall crawle ich CNN Markets, eine typische Tabellenlisten-Seite.
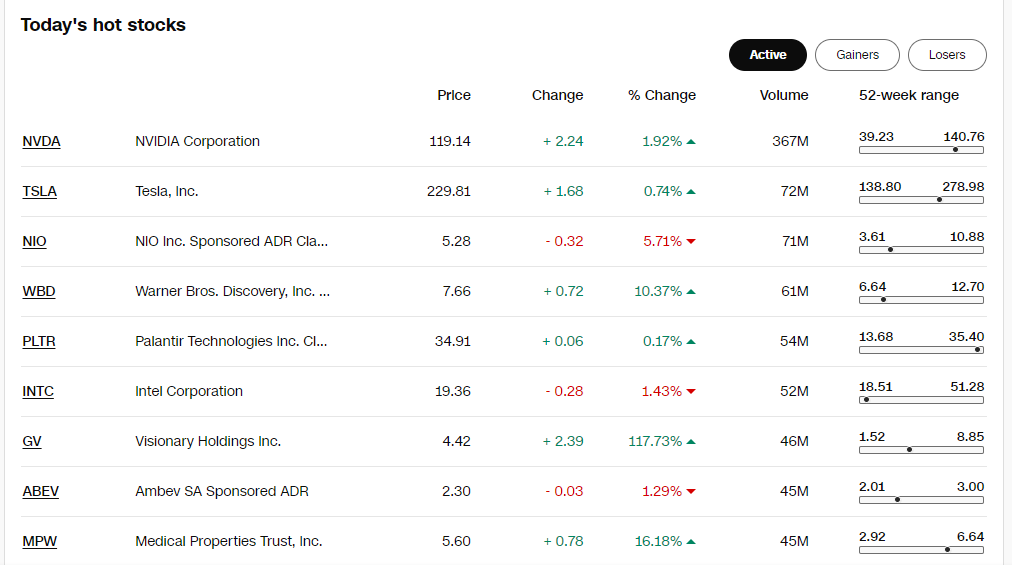
Anschließend verwende ich die Funktion „Auto-detect web page data“, die die Seite schnell scannt und die Tabellenelemente hervorhebt, wobei Zeilen und Spalten automatisch ausgewählt werden.
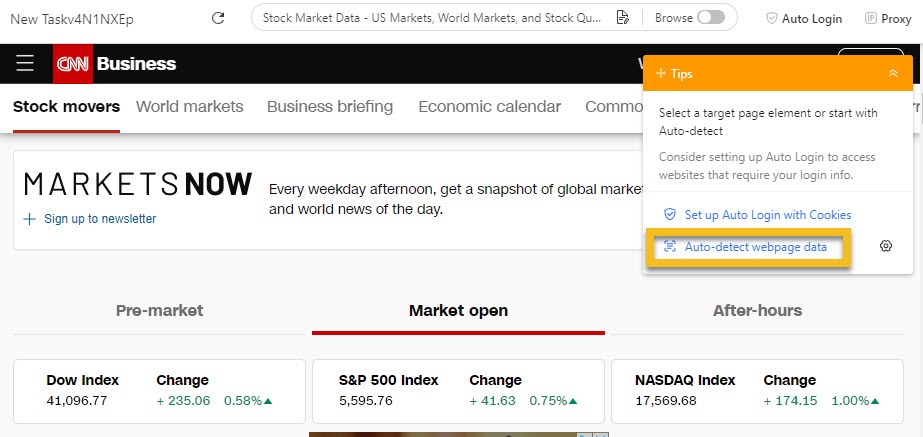
Wenn die automatische Erkennung etwas übersieht, wähle ich manuell die erste Zelle der ersten Zeile aus und erweitere die Auswahl, bis die gesamte Zeile hervorgehoben ist. Octoparse findet dann die anderen Zeilen mit ähnlichen Strukturen für mich.
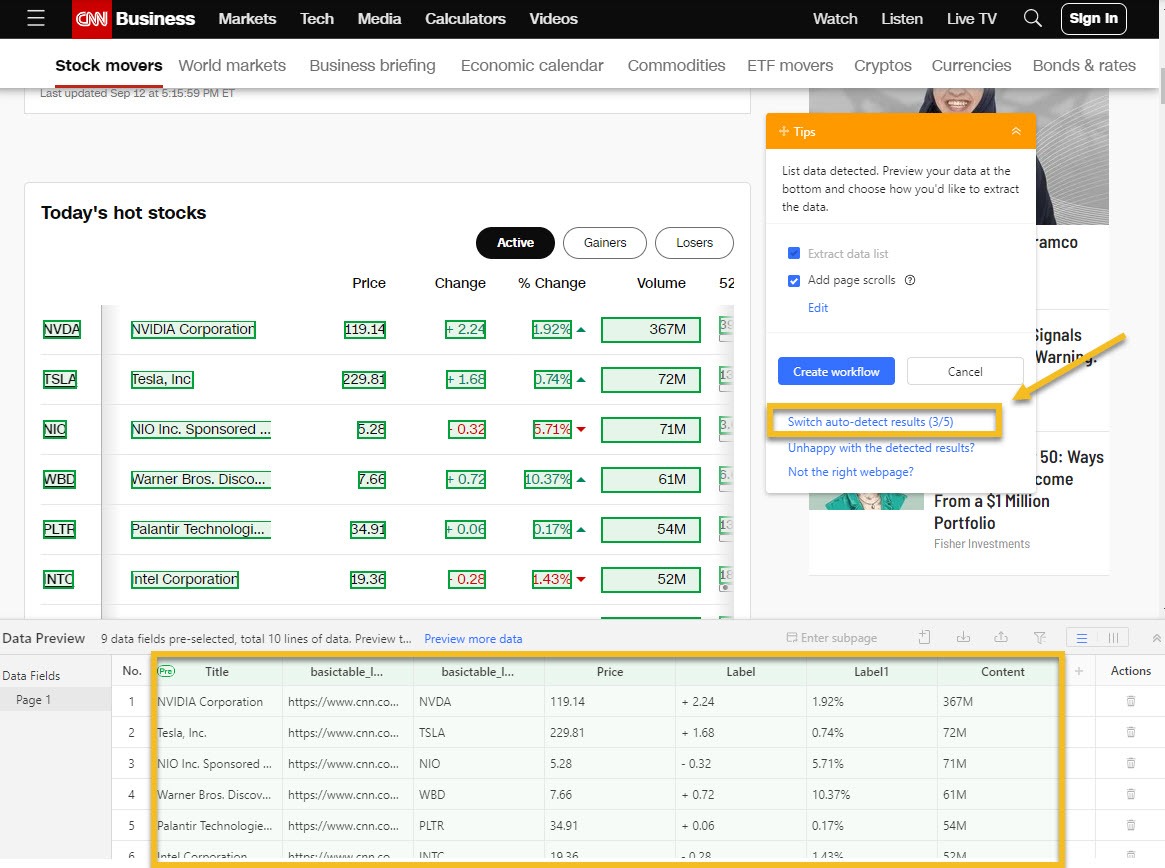
Danach überprüfe ich, ob alle gewünschten Spalten enthalten sind, benenne unklare Spaltenüberschriften um und entferne nicht benötigte Felder. Wenn sich die Tabelle über mehrere Seiten erstreckt, richte ich die Paginierung ein, indem ich Octoparse mitteile, wie es auf „Weiter” klicken soll, um weitere Seiten zu crawlen.
Abschließend führe ich eine Testextraktion durch, um sicherzustellen, dass alle Zeilen und Zellen korrekt erfasst werden, bevor ich das vollständige List Crawling starte und die Daten im CSV- oder Excel-Format exportiere.
Weiterführende Literatur Weitere Informationen zum Crawlen oder Scrapen von Tabellendaten in Octoparse finden Sie in unserem Tutorial.
2. Daten in Tabs oder Tab-Oberflächen crawlen
Manchmal verwenden Websites Tabs, um Listendaten innerhalb einer Seite zu organisieren – zum Beispiel Produktvarianten, technische Daten oder Nutzerbewertungen in separaten Tab-Bereichen.
Ich lade die Webseite mit den Tabs und richte Aktionen ein, um jeden Tab nacheinander anzuklicken, damit der darin enthaltene Inhalt für die Extraktion sichtbar wird. Anschließend verwende ich die Auto-Erkennungsfunktion oder die manuelle Auswahl, um die Daten innerhalb jedes Tabs zu erfassen.
Wenn es mehrere Tabs oder verschachtelte Listen gibt, konfiguriere ich eine Schleife, damit Octoparse jeden Tab-Bereich dynamisch besucht und die Informationen daraus extrahiert.
Ein wichtiger Trick besteht darin, beim Wechseln zwischen Tabs angemessene Wartezeiten in den Workflow einzufügen, damit der Seiteninhalt vollständig geladen wird – insbesondere wenn die Tabs Daten über JavaScript oder AJAX laden.
3. Listing- und Detailseiten-Strukturen crawlen
Bei Websites, die Produkt- oder Artikellistings mit Links zu Detailseiten anzeigen, umfasst der Crawling-Prozess zwei Hauptschritte: das Scrapen der Übersicht auf der Listing-Seite und anschließend das Aufrufen jeder Detailseite, um zusätzliche Informationen zu extrahieren.
Ich beginne damit, die URL der Listing-Seite in Octoparse einzugeben und die Auto-Erkennungsfunktion auszuführen, um alle Elemente auf der Seite zu identifizieren. Dadurch wird ein Schleifen-Element erstellt, das allgemeine Daten wie Produkttitel, Preis oder Zusammenfassung extrahiert.
Als nächstes konfiguriere ich Octoparse so, dass es automatisch auf jedes Listing klickt und zur Detailseite navigiert, wo ich zusätzliche Datenfelder einrichte, um feinere Details zu extrahieren – wie vollständige Beschreibungen, technische Daten oder Bewertungen.
Die Paginierung wird ebenfalls eingerichtet, sodass Octoparse Daten von mehreren Listing-Seiten lädt und extrahiert. Nachdem ich in einem Testlauf bestätigt habe, dass alles reibungslos funktioniert, führe ich den vollständigen Crawl aus. Dieser Ansatz ermöglicht es mir, umfangreiche Datensätze zu erstellen, die zusammenfassende und detaillierte Informationen effizient kombinieren.
Weiterführende Literatur Weitere Details zum Crawlen von Detailseitendaten finden Sie in diesem kurzen Tutorial.
Warum ich diesen mehrschichtigen Ansatz so schätze
Die Unterteilung des Prozesses nach Listentyp hält die Dinge für Anfänger überschaubar, während technisch versierte Leser bei Bedarf tiefer eintauchen können. Außerdem bedeutet die visuelle Point-and-Click-Oberfläche von Octoparse, dass selbst komplexe List-Crawls zugänglich sind.
Wenn Sie mehr über diese Techniken erfahren möchten, habe ich detaillierte Tutorials verlinkt, die Sie Schritt für Schritt durch den Prozess führen.
Häufige List-Crawling-Probleme und wie man sie behebt
1. Keine oder nur teilweise extrahierte Daten
Das bedeutet in der Regel, dass die Seite nicht vollständig geladen wurde oder die Auswahl Elemente übersehen hat. So beheben Sie das Problem:
- Erhöhen Sie das Timeout für den Schritt „Go to Web Page”, um den Seiten mehr Ladezeit zu geben.
- Manchmal stellt das Hinzufügen einer Scroll-Aktion sicher, dass die gesamte Liste vor der Extraktion geladen wird.
- Ich füge kurze Wartezeiten zwischen den Schritten ein, insbesondere beim Umgang mit dynamischen Inhalten.
2. Paginierung überspringt Seiten oder übersieht Daten
Falsch konfigurierte Paginierung führt häufig zu Datenverlust. Ich:
- Überprüfe, ob der XPath für die Schaltfläche „Nächste Seite“ präzise und stabil ist.
- Teste die Paginierung manuell in Octoparse, um sicherzustellen, dass sie die Seiten nacheinander durchklickt.
- Manchmal hilft das Verlängern des AJAX-Lade-Timeouts dabei, dass Seiten vollständig geladen werden, bevor es weitergeht.
3. Doppelte Zeilen in exportierten Daten
Doppelte Daten entstehen häufig durch Paginierungsfehler, beispielsweise wenn Octoparse dieselbe Seite zweimal aufruft oder die Schleife falsch konfiguriert ist. Meine Lösungsansätze umfassen:
- Verfeinern des Paginierungs-XPath oder Wechseln des Schleifenmodus.
- Nutzung der automatischen Duplikatentfernung von Octoparse bei Cloud-Ausführungen.
- Hinzufügen von Logikschritten zur Erkennung und Überspringung doppelter Seiten bei Bedarf.
4. Aufgabe bleibt stecken oder friert während der Ausführung ein
Dynamische Websites oder umfangreiches JavaScript können zu Hängern führen. Sie sollten:
- Das Ereignisprotokoll und das Fehlerprotokoll überprüfen, um das Problem zu lokalisieren.
- Längere Timeouts, Scroll-Verzögerungen oder manuelle Schrittunterbrechungen hinzufügen.
- Erwägen Sie, große Crawls in kleinere Abschnitte aufzuteilen.
5. CAPTCHAs oder Sperren begegnen
CAPTCHAs können das Crawling vollständig stoppen. Ich gehe damit folgendermaßen um:
- Verwendung des CAPTCHA-Lösungsschritts von Octoparse für gängige Typen wie ReCAPTCHA.
- Implementierung von Proxy-Rotation und Variation der Anfrage-Header, um weniger wie ein Bot zu wirken.
- Verlangsamung der Crawl-Geschwindigkeit und Hinzufügen zufälliger Verzögerungen zwischen den Anfragen.
Zusammenfassend
| Problem | Wahrscheinliche Ursache | Schnelle Lösung in Octoparse |
|---|---|---|
| Keine oder unvollständige Daten | Seite nicht vollständig geladen | Scroll-Aktion oder längere Wartezeit hinzufügen |
| Paginierung überspringt Seiten | Instabiler XPath | „Auto-Paginierung“ verwenden oder Schaltfläche neu auswählen |
| Doppelte Zeilen | Dieselbe Seite wird zweimal in der Schleife aufgerufen | „Duplikate entfernen“ im Workflow aktivieren |
| Aufgabe friert während der Ausführung ein | JavaScript-lastige Website | Verzögerungen hinzufügen oder Crawl in kleinere Aufgaben aufteilen |
| CAPTCHAs erscheinen | Zu schnelle Anfragen | Proxy-Rotation und zufällige Wartezeiten verwenden |
Wie ich meine gescrapten Daten bereinige und aufbereite
Nach dem Scrapen einer Datenliste ist es normal, einige Probleme zu finden, die Ihre spätere Analyse erschweren können. Zum Beispiel könnten Sie Folgendes feststellen:
- Doppelte Zeilen, die dasselbe Element mehr als einmal anzeigen.
- Fehlende Informationen in einigen Datensätzen.
- Daten, Preise oder Kategorien, die auf viele verschiedene Arten geschrieben sind.
- Zufällige HTML-Tags oder seltsame Symbole in Textfeldern.
Folgendes tue ich, um meine Daten in einen guten Zustand zu bringen:
- Doppelte Zeilen entfernen
Duplikate können die Analyse verwirren und Elemente mehrfach zählen. Ich verwende Tools wie Excels „Duplikate entfernen“ oder in Pythondf.drop_duplicates()in Pandas, um sie zu bereinigen. - Fehlende Daten auffüllen oder entfernen
Wenn Preise oder Datumsangaben fehlen, versuche ich, die Lücken mit Durchschnittswerten oder ähnlichen Einträgen zu füllen. Wenn zu viele Daten fehlen, lösche ich diese Zeilen möglicherweise. - Formate vereinheitlichen
Ich stelle sicher, dass alle Datumsangaben dasselbe Format verwenden und Preise denselben Währungsstil haben. Zum Beispiel werden sowohl$19.99als auch19.99 USDzu19.99. - Textfelder bereinigen
Manchmal enthalten Beschreibungen übrig gebliebenen Webcode oder seltsame Symbole. Ich entferne HTML-Tags und überflüssige Leerzeichen, um die Beschreibungen übersichtlich zu halten.
Tools, die ich zur Datenbereinigung verwende
- Excel oder Google Sheets: Ideal für kleine Datensätze oder schnelle Korrekturen unordentlicher Daten.
- Python mit der Pandas-Bibliothek: Perfekt für größere Datensätze oder fortgeschrittenere Bereinigungen wie das Entfernen von Duplikaten, das Auffüllen fehlender Werte und die Formatierung von Spalten.
- OpenRefine: Ein No-Code-Tool, das dabei hilft, unordentliche Daten zu bereinigen, indem es ähnliche Einträge gruppiert und Inkonsistenzen behebt.
Hier ist ein einfaches Python-Beispiel zum Entfernen von Duplikaten und zum Auffüllen fehlender Preise:
Eine gute Datenbereinigung spart mir später Zeit, verbessert die Genauigkeit meiner Analyse und hilft mir, den Erkenntnissen aus meinen gescrapten Listen zu vertrauen.
Häufige Fragen zum List Crawling
1. Wie kann ich dynamisch geladene Listeninhalte wie unendliches Scrollen oder Inhalte in Tabs verarbeiten?
Viele moderne Websites verwenden JavaScript, um Listenelemente dynamisch zu laden, während Sie scrollen oder auf Tabs klicken. Um damit umzugehen, verwenden Sie Tools, die JavaScript ausführen können, wie den integrierten Browser von Octoparse oder Selenium. Möglicherweise müssen Sie Scroll-Aktionen oder Tab-Klicks simulieren und Wartezeiten hinzufügen, damit der Inhalt vor der Extraktion Zeit zum Laden hat.
2. Wie vermeide ich, dass mein Crawler beim Scrapen dynamischer Listen blockiert wird?
Verwenden Sie Proxy-Rotation, verlangsamen Sie die Anforderungsgeschwindigkeit mit zufälligen Verzögerungen, rotieren Sie User-Agents und respektieren Sie die Rate-Limits der Website. Octoparse bietet IP-Proxy-Unterstützung und CAPTCHA-Lösung, um Sperren zu minimieren.
3. Kann ich Daten aus login-geschützten oder sitzungsbasierten Listen scrapen?
Wenn eine Website eine Anmeldung erfordert, um die gewünschten Daten anzuzeigen, muss Ihr Crawler den Anmeldeprozess automatisch verwalten. So gehe ich dabei in einfachen Schritten mit Octoparse vor:
1. Öffnen Sie die Anmeldeseite im integrierten Browser von Octoparse.
2. Klicken Sie auf das Benutzernamen-Feld, wählen Sie „Text eingeben“ und geben Sie Ihren Benutzernamen ein.
3. Klicken Sie auf das Passwort-Feld, wählen Sie „Text eingeben” und geben Sie Ihr Passwort ein.
4. Klicken Sie auf die Schaltfläche „Anmelden“ und wählen Sie „Schaltfläche klicken”, um sich anzumelden.
5. Um sicherzustellen, dass bei jedem Mal eine neue Anmeldung erfolgt, löschen Sie Cookies, bevor die Seite geladen wird (dies wird unter „Go to Web Page“ > „Optionen” eingestellt).
6. Speichern Sie Cookies nach der Anmeldung über „Go to Web Page“ > „Optionen” > „Cookie von aktueller Seite verwenden“, um die Anmeldung beim nächsten Mal zu überspringen (gültig bis zum Ablauf des Cookies).
7. Wenn lokal ein CAPTCHA erscheint, geben Sie es manuell ein.
Wenn Sie eine detaillierte Anleitung zum Scrapen von Daten hinter einem Login wünschen.
4. Kann ich in Schwierigkeiten geraten, wenn ich öffentlich zugängliche Listen crawle?
Im Allgemeinen ist das Crawlen öffentlich zugänglicher Listenseiten (wie Produktkataloge oder Verzeichnisse) erlaubt.
Einige Websites verbieten jedoch in ihren Nutzungsbedingungen ausdrücklich die automatisierte Datenerfassung, was zu IP-Sperren oder rechtlichen Problemen führen kann. Ich empfehle Ihnen, immer die Richtlinien der Website zu prüfen und im Zweifelsfall um Erlaubnis zu bitten.
Weiterführende Literatur Wir haben in unserem Blog ausführlicher über das Thema „Ist Web Scraping legal?“ diskutiert. Schauen Sie gerne vorbei.
Fazit
List Crawling ist das Rückgrat der meisten Web-Datenextraktion heute, und zu wissen, wie man strukturierte Daten von mit Listen gefüllten Seiten abruft, macht den entscheidenden Unterschied.
Der Trick besteht darin zu wissen, wann eine Website crawl-freundlich ist, wie man häufige Fallen wie fehlerhafte Paginierung oder CAPTCHAs umgeht, und Tools wie Octoparse zu verwenden, um es einfach zu machen – auch wenn man kein Programmierer ist.
Und vergessen Sie nicht den rechtlichen Aspekt: Halten Sie sich an die Website-Richtlinien, respektieren Sie die Datenschutzgesetze der Nutzer und sammeln Sie nur Daten, die Sie verwenden dürfen.
Wenn Sie diese Grundsätze beherrschen, wird List Crawling zu einem praktischen und leistungsstarken Werkzeug, um die hochwertigen Daten zu sammeln, die Sie benötigen.



