Als bekannte Online-Publishing-Plattform deckt Medium ein breites Spektrum an Themen ab, darunter Technologie, Unternehmertum, Politik und kreatives Schreiben. Wer diese Datenmengen analysieren möchte, nutzt am besten ein Webseiten auslesen Tool. Evan Williams, Mitbegründer von Twitter, startete Medium im Jahr 2012 als eine Möglichkeit für professionelle und Amateur-Autoren, ihre Geschichten und Ideen mit einem weltweiten Publikum zu teilen. Die einfache und intuitive Benutzeroberfläche hat Millionen von Nutzern aus der ganzen Welt angezogen.
Das Web Scraping von Medium-Daten wird häufig eingesetzt, um eine große Menge an Informationen, einschließlich Artikeln, Autorenprofilen und mehr, für die Inhaltsanalyse und andere Forschungszwecke zu sammeln. Es bietet aufschlussreiche Informationen über das Engagement der Autoren, die Beliebtheit von Themen und inhaltliche Trends, die alle für akademische Studien, Marktforschung, Journalismus und KI-Training nützlich sind. Lassen Sie uns nun einen Blick auf die Hauptgründe werfen, warum Nutzer Medium scrapen möchten.
Top-Gründe für das Scrapen von Medium: Leseinteressen der Zielgruppe herausfinden
Inhaltsanalyse: Medium ist eine großartige Ressource für die Inhaltsanalyse, da es eine breite Palette von Artikeln zu einer Vielzahl von Themen bietet. Forscher, Vermarkter und Content-Strategen können Erkenntnisse gewinnen, vorherrschende Muster bestimmen und den Beliebtheitsgrad bestimmter Themen ermitteln, indem sie Medium-Inhalte systematisch analysieren und interpretieren. Diese datengesteuerte Methode kann verwendet werden, um beliebte Themen oder Probleme für gezielte Marketingkampagnen aufzudecken, Leitlinien für Content-Entwicklungsstrategien zu bieten und sogar dabei zu helfen, Pläne oder Empfehlungen für Richtlinien in bestimmten Bereichen zu gestalten.
Marktforschung: Einer der besten Orte, um einzigartige Ideen, Meinungen und Erfahrungen zu finden, ist das Ökosystem von Medium, das eine große Anzahl von Vordenkern, Innovatoren und Influencern der Branche beheimatet. Unternehmen können durch das Scrapen von Medium-Inhalten detaillierte Einblicke in Publikumspräferenzen, Marktdynamiken, neue Branchentrends und kreative Ideen gewinnen. Die Sammlung dieser reichhaltigen Inhalte ist eine Goldgrube an Informationen, die die Wettbewerbsfähigkeit eines Unternehmens auf dem Markt steigern kann, indem sie die Entscheidungsfindung unterstützt.
Wettbewerbsanalyse: In der schnelllebigen Geschäftswelt ist es entscheidend, über Branchentrends und -strategien auf dem Laufenden zu bleiben. Medium ist eine Plattform, die es wert ist, für Wettbewerbsanalysen untersucht zu werden, da Unternehmen und Vordenker häufig Inhalte zu ihren Fachgebieten veröffentlichen. Durch das Scrapen von Medium können Unternehmen die von Konkurrenten erstellten Inhalte überwachen und auswerten. Dies ermöglicht es ihnen, über Branchenentwicklungen auf dem Laufenden zu bleiben, die Geschäftspläne ihrer Rivalen besser zu verstehen und ihre eigenen Taktiken entsprechend anzupassen.
Stimmungsanalyse (Sentiment Analysis): Die große Nutzerbasis von Medium macht es zu einer perfekten Plattform, um Stimmungen zu analysieren, die öffentliche Meinung zu messen und starke Emotionen zu bestimmten Themen, Produkten oder Unternehmen zu erfassen. Datenwissenschaftler können durch das Scrapen von Medium eine erhebliche Menge an Textdaten erhalten. Dies ermöglicht es ihnen, spezielle Algorithmen einzusetzen, um die öffentliche Meinung zu messen. Indem sie Einblicke in die öffentliche Meinung bietet, kann diese analytische Methode für Organisationen und Markenstrategen sehr hilfreich sein. Sie kann dabei helfen, Marketingstrategien, Markenkampagnen und die Produktentwicklung zu gestalten.
Lead-Generierung: Medium dient als Treffpunkt für eine Vielzahl von Autoren und Meinungsführern aus vielen Wirtschaftssektoren. Unternehmen können durch den Einsatz von einem Webseiten auslesen Tool mögliche Leads basierend auf Autorenprofilen, Interessen und Kompetenzbereichen identifizieren. Diese fokussierte Strategie hat das Potenzial, den Kundenstamm zu vergrößern, wertvolle Networking-Möglichkeiten zu schaffen und die Bemühungen zur Lead-Generierung erheblich zu verbessern.
Data Mining für maschinelles Lernen: Medium kann eine wertvolle Quelle für Textdaten für Personen in den Bereichen Künstliche Intelligenz (KI) und Data Science sein. Sie können die vielfältigen Inhalte von Medium für maschinelles Lernen, das Training von KI-Modellen und Anwendungen der Verarbeitung natürlicher Sprache (NLP) nutzen, indem Sie diese scrapen. Die Vielfalt an Themen und Schreibstilen auf Medium bietet einen erstklassigen Korpus zum Testen und Trainieren von Algorithmen und trägt zu wichtigen Entwicklungen in den Methoden der KI und des maschinellen Lernens bei.
Methoden zum Scrapen von Medium: Eigene Textdatenbank für KI aufbauen
Medium-Beiträge mit Python scrapen
Web-Scraping-Tools wie BeautifulSoup und das leistungsstarke Scrapy-Framework sind in der Tat zu einem festen Bestandteil im Bereich der Datenerfassung und -verwaltung geworden. BeautifulSoup, ein benutzerfreundliches Python-Paket, vereinfacht den Prozess des Parsens von HTML- und XML-Dokumenten wunderbar und hilft so beim Scrapen von Medium. Andererseits bietet Scrapy eine robuste und flexible Lösung für die Bewältigung größerer und komplexerer Scraping-Aufgaben auf Medium, wie z. B. das Extrahieren verschiedener Artikel. Mit seiner Fähigkeit, leistungsstarke Spider-Bots zu erstellen, entfaltet sich Scrapy als ideales Werkzeug für die fortgeschrittene Datenextraktion aus Medium.
Python-Nutzer, die beispielsweise Online-Material von Medium scrapen möchten, müssen Requests und Web-Scraping-Pakete wie Beautiful Soup verwenden. Diese Bibliotheken machen es möglich, HTML-Inhalte aus Websites zu extrahieren, damit sie für die Datenanalyse verwendet werden können. Hier ist eine komprimierte Erklärung, wie diese Aufgabe zu bewältigen ist:
Bitte beachten Sie, dass Sie die Nutzungsbedingungen und die robots.txt-Datei jeder Website lesen und einhalten sollten, bevor Sie versuchen, diese zu scrapen. Die Nutzungsbedingungen von Medium könnten durch Web Scraping verletzt werden, was zur Sperrung Ihrer IP-Adresse führen könnte.
# Schritt 1: Notwendige Bibliotheken importieren
from bs4 import BeautifulSoup
import requests
# Schritt 2: Eine Anfrage an die Website senden
r = requests.get(‘http://medium.com/topic/popular’)
# Schritt 3: Den Seiteninhalt parsen
soup = BeautifulSoup(r.text, ‘html.parser’)
# Schritt 4: Erforderliche Informationen extrahieren
articles = soup.find_all(‘div’, class_=’postArticle’)
for article in articles:
title = article.find(‘h3’).text if article.find(‘h3’) else ‘[Kein Titel]’
print(‘Titel: ‘, title)
Dieses Skript sendet eine Anfrage an eine Medium-Themenseite, parst den HTML-Inhalt der Seite und findet alle div-Tags mit der Klasse ‘postArticle’. Auf diese Weise können Sie gezielt div container inhalte mit python ausgeben. Anschließend sucht es innerhalb jedes dieser Tags das h3-Tag (das Tag, das den Titel enthält) und gibt den Text aus.
Achtung: Sie müssen sicherstellen, dass Sie die richtigen Klassennamen verwenden, da die Website die Klassen und die Struktur der Website aktualisieren kann.
Medium-Beiträge ohne Programmierung scrapen
Als Ergänzung zur Vielfalt haben sich Web-Scraping-Tools wie das No-Code-Tool Octoparse als bemerkenswerte Werkzeuge etabliert, die automatisiertere Scraping-Optionen bieten und einen nutzerzentrierteren Ansatz verfolgen. Leistungsstarke Plattformen machen das Medium-Scraping so nahtlos wie möglich und bieten eine anfängerfreundliche, aber dennoch professionelle Umgebung für die Datenextraktion auf Medium. Mit seinen fortschrittlichen Web-Scraping-Funktionen beseitigt Octoparse die Komplexitäten, die normalerweise mit der Datenextraktion verbunden sind.
Es gibt mehrere Schlüsselfaktoren, die bei der Auswahl des richtigen Webseiten auslesen Tools für Scraping-Projekte zu berücksichtigen sind. Zum Beispiel diktieren die Größe und Komplexität des Projekts definitiv die Wahl; wenn es sich um eine groß angelegte und komplizierte Aufgabe handelt, kann ein umfassenderes Tool wie Scrapy erforderlich sein. Andererseits sind Programmierkenntnisse eine weitere Überlegung. Während BeautifulSoup eine sanfte Lernkurve für Anfänger bietet, sind Tools wie Octoparse fantastisch für diejenigen, die sich mit dem Programmieren nicht auskennen. Die Benutzerfreundlichkeit des Tools, seine Fähigkeit, dynamische Websites zu handhaben, und die Art der Daten, die Sie extrahieren möchten, sind weitere Faktoren, über die man nachdenken sollte. Für Websites wie Medium kann Octoparse mit seinem robusten integrierten Browser und der intelligenten Datenerkennung die Aufgabe vereinfachen. Lassen Sie uns nun im Detail eintauchen, wie man Octoparse verwendet, um Medium-Daten zu scrapen.
Wie man einen Medium Scraper in Octoparse erstellt
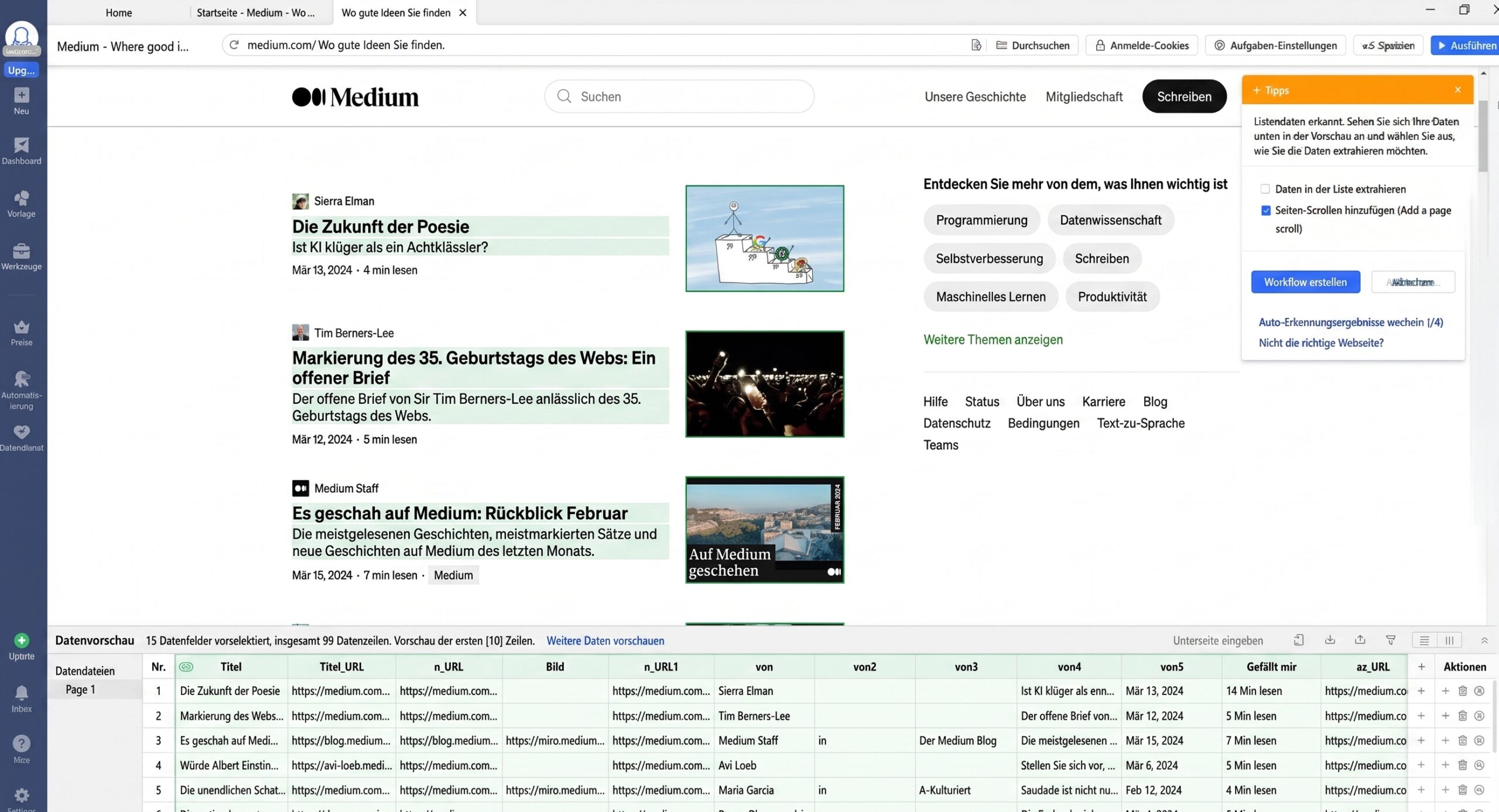
Schritt 1: Eine neue Aufgabe zur Erfassung von Medium-Daten erstellen
Kopieren Sie die Medium-URL und fügen Sie sie in die Suchleiste von Octoparse ein. Klicken Sie dann auf „Start“, um eine neue Scraping-Aufgabe zu generieren.
Schritt 2: Den Medium Scraper erstellen und anpassen
Die Medium-Seite wird in den integrierten Browser von Octoparse geladen. Klicken Sie im Tipps-Bedienfeld auf „Webseitendaten automatisch erkennen“, nachdem die Seite vollständig geladen ist. Alle extrahierbaren Daten werden auf der Seite mit einem grünen Hintergrund markiert, sodass Sie leicht überprüfen können, ob Ihre gewünschten Daten ausgewählt sind oder nicht. Generieren Sie dann einen Workflow, indem Sie auf „Workflow erstellen“ klicken, sobald Sie alle gewünschten Daten ausgewählt haben. Der Workflow wird auf der rechten Seite angezeigt. Er enthält jede Aktion des Vorgangs. Sie können auf jede einzelne klicken, um zu überprüfen, ob sie wie geplant funktioniert. Sie können in diesem Flussdiagramm auch neue Aktionen hinzufügen oder unerwünschte Schritte entfernen.
Schritt 3: Den Medium Scraper starten
Sobald Sie alles überprüft haben, klicken Sie auf die Schaltfläche „Ausführen“, um den Extraktionsprozess für Medium-Artikel zu starten. Sie können ihn je nach Bedarf lokal auf Ihrem Gerät oder remote über die Cloud ausführen. Exportieren Sie die Daten nach Abschluss der Ausführung schließlich zur weiteren Verwendung in lokale Dateien wie Excel und CSV oder in eine Datenbank wie Google Sheets.
Fazit
Insgesamt stellt Medium eine unschätzbare Ressource für eine Vielzahl von Nutzern dar. Seine vielfältigen Inhalte, die von persönlichen Essays bis hin zu professionellen Erkenntnissen reichen, machen es zu einem faszinierenden Ziel für das Data Scraping. Durch die Wahl eines geeigneten Webseiten auslesen Tools können Nutzer das volle Potenzial von Medium in Bezug auf Marktanalysen, akademische Forschung, Content-Erstellung und die Formulierung von Geschäftsstrategien freisetzen. Sei es BeautifulSoup für einfachere Aufgaben, Scrapy für komplexere Scraping-Anforderungen oder andere Web-Scraping-Software – diese Tools bieten den Schlüssel zur Nutzung der Macht der Daten im heutigen digitalen Informationszeitalter.