Das 21. Jahrhundert ist die Informationsgesellschaft, und die Welt ist durch das Internet eng miteinander verbunden. Vor dem Hintergrund dieser Zeit füllt eine Flut von Daten die Augen und Köpfe der Menschen. Die genaue Suche nach Daten in Hunderten von Millionen von Computernetzen ist zu einer notwendigen Fähigkeit für hervorragende Talente geworden.
Aber es ist ohne Zweifel eine schwere Sache, manuell von der Datenwelt Ziel-Informationen durchzusuchen und zusammenzufassen. Web Scraping war garade geboren, um Menschen dabei helfen, schnell, effizient und regelmäßig gewünschte Daten zu sammeln. Wegen verschiedenen Form von Websites benötigt man, eine geeignete Methode für Ziel-Website zu finden.
Häufigste Paginierung beim Data Scraping
Paginierung mit „Nächst“-Button
Dies ist eine der am häufigsten verwendeten Formen oder Strukturen für das Umblättern von Seiten auf einer Webseite. Normalerweise befindet sich am unteren Ende der Listenleiste ein Block mit einer numerischen Seitenzahl, so dass der Benutzer die genaue Information über die aktuelle Seitenzahl erhalten kann.
Gebräuchliche Formulare:
- Anklickbarer Button mit Zeichen von „Nächst“ und „Vorherig“
- Anklickbarer Button mit Zeichen von „Weiter“ und „Zurück“
- Anklickbarer Button mit Zeichen von „>“ und „<“
Paginierung ohne „Nächst“-Button
In diesem Modus gibt es nur relativ wenige Seiten, die in der Regel nur mit Seitenzahlen und Ziffern beschriftet sind, und keine optionalen Vor- oder Zurück-Tasten. Im Vergleich zum vorherigen Muster sind die Schaltflächen zum Blättern in dieser Art von Struktur schwieriger zu überprüfen, und die Anforderungen an den Code für Web Scraping können etwas höher sein.
Gebräuchliche Formulare:
- 1, 2, 3, 4, 5 und die weitere Nummer blättert mit der gewählten Seitenzahl.
- 1, 2, 3, 4, …
Paginierung mit Unendlosem Scrollen
Dieses Layout-Muster ist eher für Job Scraping oder Business Scraper üblich. Die Besucher müssen die aktuelle Seite oder einen Teil des Moduls weiterblättern, um neue Informationen zu laden. Das heißt, Sie werden keine Aktionen über Pagination-Button nehmen aber dauerhaft nach unten scrollen.
Gebräuchliche Websites:
- Google Maps
- Indeed
Paginierung mit „Mehr Anzeigen“-Button
Diese Art des Ladens von Informationen ist ebenfalls üblich. Die Benutzer klicken immer wieder auf die neu geladene Schaltfläche „Mehr anzeigen“, um neue Seiten oder Informationen zu erhalten. Im Vergleich zum ständigen Blättern werden alle Informationen auf derselben Seite angezeigt, was für die Benutzer günstiger ist, um die Informationen auf demselben Bildschirm zu vergleichen, wenn sie die Informationen erhalten. Dies bedeutet in der Regel, dass die alten Informationen nicht auf der aktuellen Seite verschwinden, sondern ständig übereinander gestapelt werden.
Gebräuchliche Websites:
- Button von Mehr Laden
- Button von Mehr Anzeigen
- Button von Weiter Anzeigen
- Button von Weitere Ergebnisse, üblich in Suchmaschiene wie Google
Nach einer umfassenden Überblick über Paginationsarten glaube ich, dass Sie es kaum erwarten, Ihren eigenen Web Scraper einzubauen! Beim Web-Scraping werden Sie jedoch bestimmt auf solches Problem stoßen – wie kann ich mit dem Button „Mehr Anzeigen“ umgehen. Heute werden wir zusammen erkunden, wie man dieses Problem beim Data-Scraping mit einem Web-Scraping-Tool leicht lösen können.
Beispiel Tutorial: Google Scraper mit „Mehr Anzeigen“ Button
Wenn Sie kein Programmierer sind und keine Ahnung von Programmierung haben, empfehlen wir Ihnen Octoparse als das beste Web-Scraping-Tool, um das Problem zu beheben. Es ist ein kostenloses Tool für Windows- und Mac-Systeme, das einfach zu bedienen ist und keine Programmierkenntnisse voraussetzt.
Hier werden wir Google als Beispiel verwenden, um Ihnen zu zeigen, wie Octoparse einen Google Chrome Web Scraper zur Bewältigung des Problems erstellt.
Detaillierte Anleitung vom Google Scraper
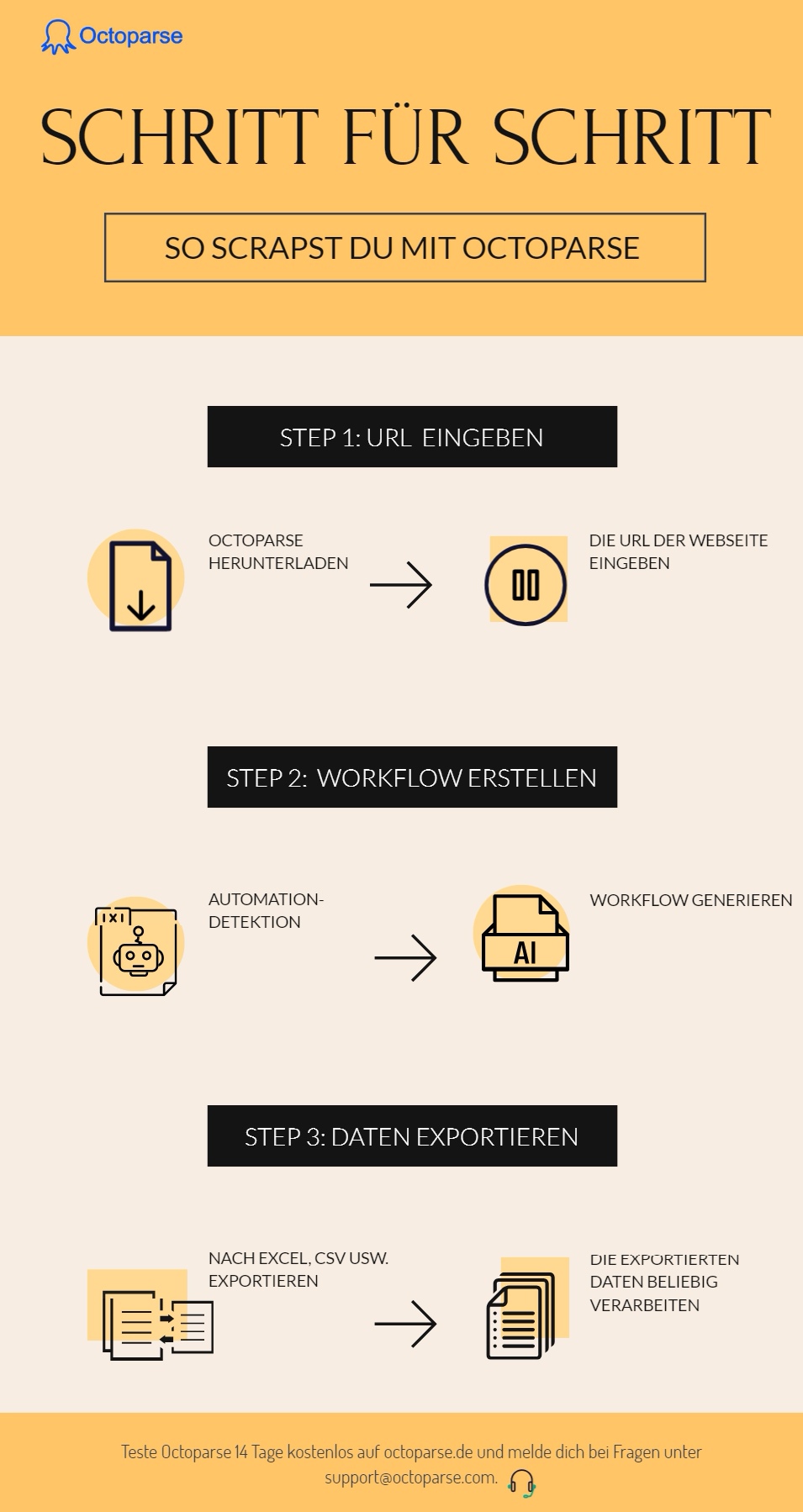
- Schritt 1: Zuerst geben Sie ein Schlüsselwort in Google Search ein, um die gewünschten Ergebnisse davon zu bekommen. Dann kopieren Sie diese URL. Öffnen Sie bitte Octoparse und geben Sie diesen Link auf die Homepage ein.
- Schritt 2: Sie befinden sich jetzt in die Ergebnisse-Seite, ganz ähnlich wie bei Chrome. Starten Sie Octoparse Auto-Detektionsfunktion zum Erhalten eines Workflows.
- Schritt 3: Oder Sie können auch manuell Ihren Workflow einrichten. Wählen Sie alle Items, was Sie erfassen möchten, dann scrapen Sie die geeignete Element-Form unter den Anleitungen bei der Tipps-Platte, wie Text, Link usw. Dann finden Sie den Button von „Weitere Ergebnisse“ ganz unten, darauf klicken und danach eine Schleife erstellen, um diesen Button wiederholend anzuklicken und immer weitere Ergebnisse zu bekommen.
- Schritt 4: Prüfen Sie Ihren Workflow, um zu sehen, ob alle Schritte gut funktionieren. Nachdem alle Datenfelder überprüft worden sind, führen Sie den erstellten Workflow aus. Octoparse bietet zwei Scraping-Modi, bei der Lokale oder bei der Cloud. Dann würden die gescrapten Daten erhalten, wenn der ausgewählte Button in Ordnung funktioniert.
Vorteile bei Octoparse Google Scraper
- Einfach zu verwenden. Nur mit einigen Schritte oder mächtiger Auto-Detektionsfunktion bekommt man einen Scraping-Workflow.
- Kein Code erforderlich. Visualisierungstafeln machen alle Prozesse einfach.
- Eine Menge von Funktionen. Cloud-Datenerfassung, Captcha-Lösungen, Aufgabenplanung… Alles macht Web Scraping interessant!
- Mehrsprachige Dienste. Produkte und Dienste zur Sprachlokalisierung ermöglichen ein besser auf Ihre Gewohnheiten zugeschnittenes Crawling.
- Octoparse bietet über 100 benutzerfreundliche Vorlagen, um Daten zu extrahieren. Über 30.000 Nutzer verwenden die Vorlagen
https://www.octoparse.de/template/google-search-scraper
Behebung des Web-Scraping von „Mehr Laden“ Button mit Python
„Wie kann man die Website scrapen, wenn sie einen ‚Mehr laden‘ Button hat, um mehr Inhalt auf der Seite zu laden?“
Vielleicht haben Sie die gleiche Frage wie oben auf Stackoverflow, obwohl Sie etwas über Programmierung wissen. Sie können dort Antworten und Diskussionen zu dieser Frage finden. Wir empfehlen Ihnen dennoch, Octoparse auszuprobieren, wenn Sie immer noch verwirrt sind.
Zusammenfassung
In diesem Artikel werden mehrere gängige Paging-Methoden und ihre Handhabung beim Web Scraping vorgestellt, insbesondere die Verwendung des Octoparse-Tools zur Lösung des Crawling-Problems mit der Schaltfläche „Mehr laden“. Er enthält detaillierte Schritte und Anleitungen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



