Als beliebter Online-Marktplatz im deutschsprachigen Raum taucht auf eBay Kleinanzeigen ständig neue Informationen auf – minuteweise kommen unzählige neue Angebote hinzu. Möchte man aus dieser Fülle öffentlich zugänglicher Daten wertvolle Informationen extrahieren, kommt ein eBay Kleinanzeigen Scraper ins Spiel. Was genau ist das eigentlich? Welche Daten lassen sich damit extrahieren? Und welche praktischen Methoden und Vorsichtsmaßnahmen gibt es? Im Folgenden erklären wir Ihnen das ausführlich.
Was ist ein eBay Kleinanzeigen Scraper?
Ein Web-Scraper ist ein Programm (oder ein No-Code-Workflow), das Webseiten automatisiert aufruft, den HTML-Quelltext analysiert und gezielt Informationen extrahiert. Bei eBay Kleinanzeigen bedeutet das konkret:
1. Die Such- oder Kategorie-URL wird per HTTP/HTTPS geladen.
2. Der Scraper identifiziert wiederkehrende HTML-Container (jeder entspricht einer Anzeige).
3. Er holt definierte Felder – z. B. Titel, Preis, PLZ, Bilder-URL – heraus und speichert sie strukturiert (CSV, Excel, Datenbank …).
Wichtig: Es werden nur öffentlich sichtbare Daten gesammelt. Das Umgehen von Logins, Captchas oder das Abgreifen personenbezogener Informationen (Telefonnummern, E-Mails) ist tabu und verstößt gegen AGB und DSGVO.
Welche Daten kann man von eBay Kleinanzeigen scrapen?
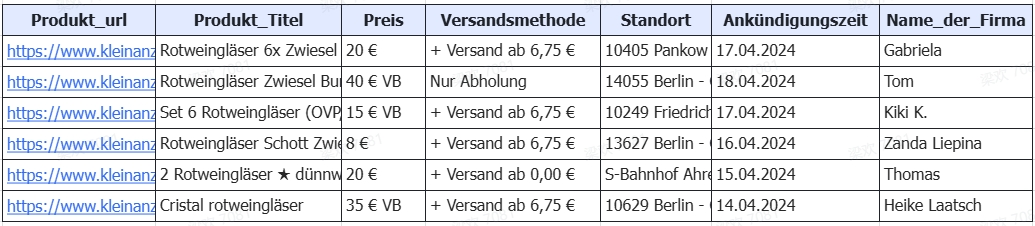
Eine Anzeige auf eBay Kleinanzeigen enthält weit mehr Informationen als nur Titel und Preis. Wer die Felder gezielt ausliest, erhält nicht nur Rohdaten, sondern verwertbare Signale zu Produktzustand, Nachfrageniveau und regionalen Marktunterschieden. Die folgende Tabelle zeigt die wichtigsten Datenpunkte, ein konkretes Beispiel und den jeweiligen potenziellen Analyse-Nutzen auf einen Blick.
| Feld | Beispiel | Nutzen |
| Titel | Bosch AkkuschrauberGSR 12V | Produkt- bzw.Modellerkennung |
| Preis | 55 € VB | Preisanalyse,Verhandlungsspielraum |
| Beschreibung | Akku neu, Rechnung von 2023 | Zustands- undEchtheitsprüfung |
| Kategorie | Heimwerken >Elektrowerkzeuge | Segmentierung,Wettbewerbsmatrix |
| Ort / PLZ | Hamburg (22305) | Regionale Nachfrage &Preiscluster |
| Erstelldatum | 14.07.2025 | Angebotsdauer,Nachfragetendenz |
| Profil ID | user_2348761 | Mehrfachangebotedesselben Verkäufers |
| Bilder Links | https://i.ebayimg.com/images/… | Sichtprüfung, Bilder‑KI,CDN‑Download |
| Aufrufe / Likes | 152 Views, 3 ❤︎ | Beliebtheit,Trend‑Früherkennung |
Warum überhaupt scrapen? – Use Cases
EBay Kleinanzeigen zählt zu den populärsten Online-Marktplätzen im deutschsprachigen Raum. Im Minutentakt tauchen hier neue Angebote auf – vom günstigen Smartphone bis zum exotischen Ersatzteil. Wer diese Daten systematisch sammelt, kann sich damit einen Marktvorteil verschaffen, indem Trends schneller erkannt, Preise realistischer kalkuliert und neue Geschäftsmodelle bedarfsorientiert aufsetzen werden können. Die wichtigsten Anwendungsfälle lassen sich in sechs Kategorien bündeln:
Marktanalyse: Durchschnitts-, Mindest-, Höchstpreise pro Produkt & Region ermitteln.
Preis-Monitoring: Alarm auslösen, wenn ein Artikel unter Schwellenwert X fällt.
Wettbewerbsbeobachtung: Welche Händlerinnen bieten in „meinem“ PLZ-Gebiet?
Lead-Generierung: Frisch inserierte Schnäppchen sofort erkennen und ankaufen.
Sortiments-Benchmarking: Sortimentsbreite & -tiefe von Mitbewerbern nachvollziehen.
Datenanreicherung: Interne Produktkataloge um Echtbilder, Beschreibungen, Stichwörter ergänzen.
Praxis-Szenario: „IKEA Kallax in Berlin” wöchentlich tracken
Ziel
Ein kleiner Gebrauchtmöbel-Händler möchte wissen, zu welchen Preisen das Regal „IKEA Kallax 4×4“ in Berlin gehandelt wird, um realistische Ankauf- und Verkaufspreise festzulegen.
Rahmen
- Zeitraum: jeweils die letzten 7 Tage
- Region: Berlin (PLZ-Bereich 10115 – 14199)
- KPI: Median-Preis + Mindest-Preis + Anzahl neuer Anzeigen
Ablauf
1. Crawler ruft jeden Freitagabend die Such-URL: https://www.kleinanzeigen.de/s-berlin/kallax/k0l3331
(PLZ-ID 3331 steht für Berlin) ab.
2. Datensätze werden in CSV gespeichert und auf Google Drive abgelegt.
3. In Google Sheets berechnet eine einfache Formel automatisch Median- und Minimal- preis.
4. Ein Bedingtes-Format markiert Inserate 20 % unter Median als potenzielle Ankauf-Kandidaten.
Ergebnis eines echten Laufs (KW 28 / 2025):
142 Inserate → Median 55€, Minimum 20€, 41 Anzeigen ≤ 44€ (= 20 % unter Median). Quelle: Crawl vom 15. 07. 2025.
Wie kann man eBay Kleinanzeigen ohne Codierung scrapen?

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Methode 1: Vorgefertigter eBay Kleinanzeigen Scraper (Template)
https://www.octoparse.de/template/kleinanzeigen-scraper-product-details
So funktioniert es in der Praxis: Öffnen Sie zunächst Octoparse und wechseln Sie in das Template Center. Suchen Sie dort nach „Kleinanzeigen Scraper – Product Details“ und wählen Sie die Vorlage aus. Anschließend geben Sie entweder ein Stichwort oder die komplette Listen-URL Ihrer gewünschten eBay-Kleinanzeigen-Suche ein. Aktivieren Sie den Proxy-Pool „Europa West“, um IP-Sperren zu vermeiden, prüfen Sie die Vorschau und starten Sie den Crawl. Während der Ausführung können Sie den Fortschritt live beobachten; danach exportieren Sie die Ergebnisse wahlweise als CSV, Excel, JSON oder rufen sie über die REST-API ab.
Der große Vorteil dieser Vorlage: Sie arbeitet extrem schnell, weil im Backend optimierte Python-Selektoren zum Einsatz kommen, nutzt eine integrierte IP-Rotation inklusive Captcha-Bypass und erfordert praktisch keinen Einrichtungsaufwand – ideal für spontane Ad-hoc-Analysen.
Methode 2: Auto-Detect in Octoparse
Nutzen Sie den Auto-Detect-Modus, wenn die feste Template-Struktur nicht zu Ihrem speziellen Listing passt, wenn Sie zusätzliche Felder wie Lieferoption oder Artikelzustand auslesen müssen oder wenn sich das Seiten-Layout häufiger ändert.
Die Vorgehensweise ist denkbar einfach: Fügen Sie zunächst die gewünschte Such- oder Kategorie-URL in Octoparse ein, klicken Sie auf „Auto-Detect Website Data“ und lassen Sie das Tool automatisch jede Anzeigen-Kachel markieren. Sollten einzelne Felder fehlen, ergänzen Sie sie per Mausklick – etwa die vollständige Beschreibung oder das Thumbnail-Bild. Aktivieren Sie anschließend Infinite-Scroll sowie AJAX-Pagination, damit auch dynamisch nachgeladene Anzeigen erfasst werden. Schalten Sie die Proxy-Rotation ein, speichern Sie den Workflow und starten Sie ihn als Cloud-Run.
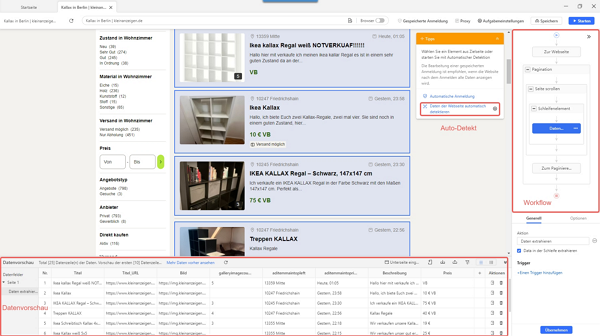
Der Auto-Detect-Ansatz bietet Ihnen deutlich mehr Flexibilität: Sie können eigene Felder definieren, exotische Kategorien problemlos scannen und UI-Änderungen mit wenigen Klicks nachtrainieren, ohne den gesamten Workflow neu aufzusetzen.
Zusammenfassung: Greifen Sie zum Template, wenn Sie ohne Vorarbeit schnell zahlreiche Standarddaten extrahieren möchten; wählen Sie Auto-Detect, sobald das Layout abweicht oder Sie zusätzliche, individuell definierte Felder benötigen.

Mit Python scrapen
Für Teams mit Entwickler-Know-how kann sich ein eigener Crawler lohnen. Die Vorteile eines eigenen Python-Crawlers liegen in der lückenlosen Kontrolle über jeden einzelnen Request, der Möglichkeit, die extrahierten Daten ohne Zwischenschritte direkt in Ihre Datenbank zu schreiben, und der Freiheit, sämtliche unternehmensspezifischen Regeln, Filter und Nachbearbeitungsschritte exakt nach Ihren Anforderungen umzusetzen.
Python-Code – Zeile für Zeile erklärt
Imports:
- requests für HTTP-Abrufe
- pandas zum Speichern / Auswerten
- time & random für Pausen + Proxy-Rotation
- BeautifulSoup zum HTML-Parsen
Konstanten: zwei frei wählbare HTTP-Proxies (Platzhalter) und ein Browser-typischer
User-Agent, damit der Request nicht wie ein Bot aussieht.
fetch()
- holt eine Seite ab
- wählt zufällig einen Proxy
- bricht bei Fehlern sauber ab (raise_for_status) – wichtig für Retry-Logik
parse()
- baut einen Soup aus dem HTML
- iteriert über jeden (eine Anzeige)
- liest Titel, Preis, Ort, relativen Link aus
- gibt ein Dict – der Generator spart Speicher
- Pagination – die URL hat den Platzhalter ?seite={}
- es werden fünf Seiten abgegrast (anpassbar)
- 1,2 s Pause schrumpft die Request-Rate unter 1 Request / Sekunde
- DataFrame erstellen
- Text „55 € VB“ → 55 via RegEx
- schnelle KPI-Berechnung direkt in Python – dieselben Formeln funktionieren auch in Excel / Sheets.
Export in UTF-8, sofort in Excel oder BI-Tool importierbar.
Möchten Sie mehr Ergebnisse, erhöhen Sie den Seitenbereich zum Beispiel auf range(1, 11) – das liefert rund hundert Inserate. Für eine andere Region tauschen Sie die PLZ-ID aus, etwa von l3331 (Berlin) auf l3332 (Potsdam). Mehrere Suchbegriffe lassen sich über eine Schleife mit verschiedenen Basis-URLs verarbeiten. Soll der Crawl automatisch laufen, legen Sie das Skript auf einem Linux-Server ab und hinterlegen einen Cron-Job über crontab -e. Und wenn Sie die Daten direkt in Ihre Datenbank schreiben möchten, verbinden Sie sich per SQLAlchemy und speichern sie mit df.to_sql(‘tab_kallax’, engine) unmittelbar in der gewünschten Tabelle.
Vollständiges Code-Beispiel
Zusammenfassung – kompletter Workflow in 4 Punkter
1. Praxisnutzen
Egal ob Sie das Octoparse-Template, den Auto-Detect-Workflow oder einen kompakten Python-Crawler einsetzen: Bereits ein Mini-Crawl von 50 – 150 Inseraten pro Woche liefert belastbare Preis- und Nachfragestatistiken.
2. Vorgehensweise
URL eingeben ➜ Crawl starten (Template / Auto-Detect oder fetch → parse → Loop)
➜Daten als CSV oder direkt in Ihre Datenbank exportieren – der Ablauf ist modular und lässt sich mit wenigen Klicks beziehungsweise Code-Zeilen anpassen.
3. Fair-Use-Regeln
Unabhängig von der Methode gilt: ≤ 1 Request / Sekunde, Proxy-Rotation aktivieren, keine personenbezogenen Daten sammeln – so vermeiden Sie Blockaden und bleiben DSGVO-konform.
4. Nächste Schritte
Qualität und Skalierung erhöhen Sie mit Retry-Logik (Back-off), Headless-Browsern für endlos scrollende Listen sowie automatischen Reports / BI-Dashboards.
Rechtliche Best Practices
Für einen rechtssicheren Crawl gilt: Erfassen Sie ausschließlich öffentlich zugängliche Daten und lassen Sie jegliche Login-Bereiche außen vor. Prüfen und respektieren Sie die AGB sowie die robots.txt von eBay Kleinanzeigen. Drosseln Sie Ihre Abrufrate auf weniger als eine Anfrage pro Sekunde, speichern Sie keine personenbezogenen Angaben wie Telefonnummern oder E-Mail-Adressen und richten Sie Löschroutinen plus eine klar erkennbare Abuse-Kontaktadresse ein, falls sich jemand über die Datennutzung beschweren möchte.
Fazit
Wenn Sie die beschriebenen Workflows selbst ausprobieren möchten, können Sie Octoparse in einer 14-tägigen Testphase kostenfrei nutzen. Legen Sie einfach einen Account an, wählen Sie das Kleinanzeigen-Template aus und starten Sie Ihren ersten Crawl – ganz ohne Zahlungs- oder Kreditkartendaten. So sehen Sie in wenigen Minuten, ob der Ansatz zu Ihrem Anwendungsfall passt. Viel Spaß beim selbst probieren!
Wenn Sie Probleme bei der Datenextraktion haben, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Weiterführende Links
- Octoparse-Template „Kleinanzeigen Scraper – Product Details“
- Auto-Detect-Tutorial (Octoparse-Blog) https://www.octoparse.com/blog/extract-data-with-auto-detection
- eBay Kleinanzeigen – Allgemeine Geschäftsbedingungen (Stand April 2025) https://themen.kleinanzeigen.de/nutzungsbedingungen/?utm_source=google& utm_medium=organic&utm_campaign=themen
- BeautifulSoup-Dokumentation https://www.crummy.com/software/BeautifulSoup/bs4/doc/



