Web Scraping ist eine Technik, die häufig zur Automatisierung des menschlichen Surfverhaltens eingesetzt wird, um große Datenmengen effizient aus den Webseiten abzurufen.
Verschiedene Web-Scraping-Tools wie Octoparse können Datenanalyse vereinfachen, aber sie haben auch ihre Probleme. Ein einfaches Beispiel ist, dass Web Scraping einen Webserver überlasten und zu einem Serverausfall führen kann. Deswegen haben viele Web-Besitzer ihre Websites mit Anti-Scraping-Techniken ausgestattet, um Scraper zu blockieren, die Web-Scraping erschweren. Trotzdem gibt es noch Möglichkeiten, sich gegen die Blockierung zu wehren.
Wie kann man scrapen, ohne blockiert zu werden?
In diesem Artikel werden wir 5 Tipps vorstellen, damit Sie beim Web-Scraping nicht so einfach auf die schwarze Liste gesetzt oder blockiert werden.
1. Verlangsamen Sie das Scraping
Die meisten Web-Scraping-Aktivitäten zielen darauf ab, Daten so schnell wie möglich zu scrapen. Wenn jedoch ein Mensch eine Website besucht, wird das Surfen viel langsamer sein als beim Web-Scraping. Daher ist es für eine Website sehr einfach, Sie als Scraper zu erwischen, indem sie Ihre Zugriffsgeschwindigkeit beobachten. Sobald sie feststellt, dass Sie die Seiten zu schnell durchlaufen, wird sie vermuten, dass Sie kein Mensch sind, und Sie sperren.
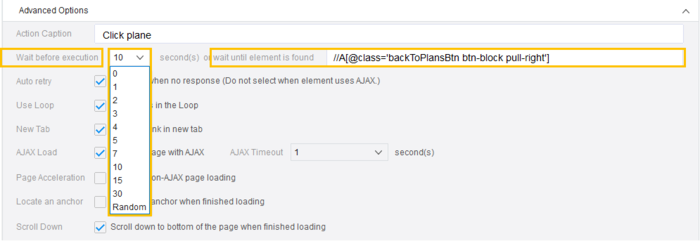
Deswegen überlasten Sie die Website nicht. Sie können eine zufällige Zeitverzögerung zwischen den Anfragen einstellen und den gleichzeitigen Zugriff auf 1-2 Seiten jedes Mal reduzieren. Wenn Sie eine Website gut behandeln und nicht überlasten, dann können Sie die Website auch weiterhin scrapen.
In Octoparse können Benutzer eine Wartezeit für jeden Schritt im Arbeitsablauf einstellen, um die Geschwindigkeit des Scrapings zu steuern. Es gibt sogar eine “random”-Option, um das Scraping menschenähnlicher zu gestalten.
2. Proxy-Server verwenden
Wenn eine Website feststellt, dass viele Anfragen von einer einzigen IP-Adresse ausgehen, wird sie diese IP-Adresse einfach blockieren. Um das zu vermeiden, können Sie Proxy-Server verwenden. Ein Proxy-Server ist ein Server (ein Computersystem oder eine Anwendung), der als Vermittler für Anfragen von Clients fungiert, die Ressourcen von anderen Servern anfordern (aus Wikipedia: Proxy-Server). Er ermöglicht es Ihnen, Anfragen an Websites über die von Ihnen festgelegte IP-Adresse zu senden und so Ihre echte IP-Adresse zu verschleiern.
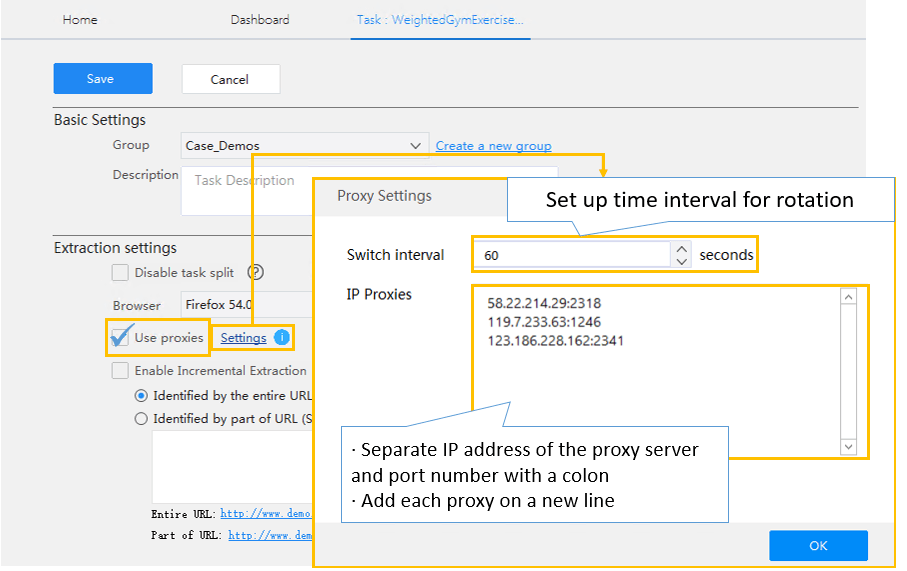
Wenn Sie eine einzige IP-Adresse im Proxy-Server verwenden, können Sie auch einfach blockiert werden. Sie müssen einen Pool von IP-Adressen erstellen und diese nach dem Zufallsprinzip verwenden, um Ihre Anfragen durch viele verschiedenen IP-Adressen zu senden.
Viele Server, wie z. B. VPNs, können Ihnen helfen, eine rotierende IP zu erhalten. Der Octoparse Cloud Service wird von Hunderten von Cloud-Servern unterstützt, die jeweils eine eigene IP-Adresse haben. Wenn eine Scraping-Aufgabe in der Cloud ausgeführt werden soll, werden die Anfragen an die Ziel-Website über verschiedene IPs ausgeführt, wodurch die Wahrscheinlichkeit, dass sie zurückverfolgt wird, minimiert wird. Bei der lokalen Extraktion mit Octoparse können Sie Nutzer Proxys einrichten, um die Blockierung zu vermeiden.
3. Verschiedene Scraping-Muster anwenden
Menschen durchsuchen eine Website mit zufälligen Klicks oder Betrachtungszeiten; Web Scraping folgt jedoch immer dem gleichen Crawling-Muster, da programmierte Bots einer bestimmten Logik folgen. Daher können Anti-Scraping-Mechanismen den Crawler leicht erkennen, indem sie das sich wiederholende Scraping-Verhalten auf einer Website identifizieren.
Sie sollen Ihr Scraping-Muster von Zeit zu Zeit ändern und zufällige Klicks, Mausbewegungen oder Wartezeiten einbauen, um das Web Scraping menschlicher zu gestalten.
In Octoparse können Sie einen Workflow innerhalb von 3-5 Minuten einrichten. Sie können Klicks und Mausbewegungen einfach mit Ziehen und Punkten hinzufügen oder einen Workflow schnell aufbauen. Octoparse spart Programmierern viel Zeit für die Programmierung und hilft Nicht-Programmierern, ihre eigenen Scraper einfach zu erstellen.
4. User-Agent wechseln
Ein User-Agent (UA) ist eine Zeichenfolge in der Kopfzeile einer Anfrage, die den Browser und das Betriebssystem gegenüber dem Webserver identifiziert. Jede von einem Webbrowser gestellte Anfrage enthält einen User-Agent. Die Verwendung des gleichen User-Agents für eine ungewöhnlich große Anzahl von Anfragen führt zur Sperrung.
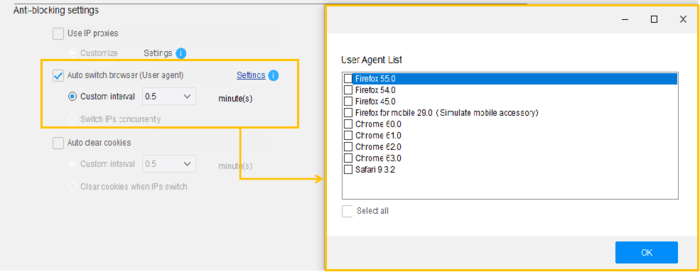
Um die Sperre zu umgehen, sollten Sie ab und zu Benutzer-Agenten wechseln, anstatt bei einem einzigen zu bleiben.
Viele Programmierer fügen gefälschte User-Agents in den Header ein oder erstellen manuell eine Liste von User-Agents, um nicht blockiert zu werden. Mit Octoparse können Sie ganz einfach die automatische UA-Rotation in Ihrem Crawler aktivieren, um das Risiko der Blockierung zu verringern.
5. Vorsicht vor Honigtopf-Fallen
Honeypots sind Links, die für normale Besucher unsichtbar sind, aber im HTML-Code vorhanden sind und von Web-Scrapern gefunden werden können. Sie sind wie Fallen, die Scraper aufspüren, indem sie sie auf leere Seiten leiten. Sobald ein bestimmter Besucher eine Honeypot-Seite aufruft, kann die Website relativ sicher sein, dass es sich nicht um einen menschlichen Besucher handelt, und beginnt, alle Anfragen von diesem Client zu drosseln oder zu blockieren.
Bei der Entwicklung eines Scrapers für eine bestimmte Website ist es wichtig, genau zu prüfen, ob es Links gibt, die für Benutzer mit einem Standardbrowser verborgen sind.
Octoparse verwendet XPath für präzise Erfassungs- oder Klick-Aktionen, um das Anklicken der gefälschten Links zu vermeiden (siehe hier, wie man XPath zum Auffinden von Elementen verwendet).
Alle in diesem Artikel genannten Tipps können Ihnen helfen, die Blockierung zu vermeiden, während die Web-Scraping-Technik und die Anti-Scraping-Techniken sich immer entwickelt. Teilen Sie uns Ihre Ideen mit, wenn Sie beim Web-Scraping Problemen gestoßen haben.
Einige E-Commerce-Websites wie Amazon und eBay haben strenge Blockiermechanismen, sodass es schwieriger sein kann, die Daten auf diesen Websites zu scrapen. Aber keine Sorge, Octoparses Daten-Service kann Ihnen die gewünschte Lösung bieten.
Wir arbeiten eng mit Ihnen zusammen, um Ihren Datenbedarf zu verstehen und sicherzustellen, dass wir das liefern, was Sie brauchen. Sprechen Sie jetzt mit dem Datenexperten von Octoparse, und erfahren, wie Web Scraping Ihnen helfen können.
Zusammenfassung
Abschließend lässt sich sagen, dass durch die Anwendung der genannten Strategien Web-Scraping sicherer und effizienter gestaltet werden kann, ohne blockiert zu werden. Anpassungen an das menschliche Surfverhalten sind hierbei entscheidend.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



