Ist das Web Scraping legal? Viel zu oft wird noch immer angenommen, dass es sich beim Web Scraping um eine Art Datendiebstahl handelt. Schließlich werden Daten im Internet gesammelt und danach benutzt.
Web Scraping wird im Großen und Ganzen für gute Zwecke eingesetzt. Etwa um die Unternehmensstrategie zu optimieren. Kunden können dadurch mehr Vorteile angeboten werden. Octoparse bietet Ihnen ein einfach zu bedienendes Web Scraping Tool. Der Anbieter achtet mit diesem Tool auf die Einhaltung der gesetzlichen Vorschriften für das Scrapen von Daten aus dem Internet.
Das digitale Zeitalter und die Mythen über das Web Scraping
In unserer digitalen Zeit sind Informationen eine wichtige Grundlage, um in Unternehmen Entscheidungen zu treffen. Mit dem Web Scraping erhält man eine Methode, eine Vielzahl von Daten innerhalb kurzer Zeit aus dem Internet zu sammeln.
Bewertungen von Dienstleistungen und Produkten zum Beispiel helfen dabei den Kundenwünschen nachzukommen. Viele Unternehmensbranchen haben bereits den Vorteil des Datensammeln erkannt und nutzen diese im Wettkampf mit der Konkurrenz.
Aus diesem Grund gibt es bereits unzählige Anbieter von Web Scraping Tools und die Nachfrage steigt stetig weiter. Die steigende Beliebtheit des Web Scraping ändert jedoch nichts an der Tatsache, dass es noch immer zahlreichende Missverständnisse und Mythen gibt. Zu diesen Missverständnissen zählt die Frage: “Ist Web Scraping legal?”.
Im Folgenden werden einige Mythen aufgedeckt und geklärt.
1. Mythos: Das Web Scraping ist nicht legal
Ist Web Scraping legal in Deutschland? Viele Menschen haben falsche Vorstellungen vom Web-Scraping, vor allem wegen des Missbrauchs durch einige, die Rechte an geistigem Eigentum verletzen. Die Wahrheit ist: Web Scraping ist an sich nicht illegal. Problematisch wird es jedoch, wenn Daten ohne Erlaubnis extrahiert werden oder wenn die Nutzungsbedingungen von Websites ignoriert werden. Um die Einhaltung der Vorschriften zu gewährleisten, sollten Sie stets die Nutzungsbedingungen der Website und die Datenschutzgesetze beachten:
- Verstoß gegen den Computer Fraud and Abuse Act (CFAA)
- Verstoß gegen den Digital Millennium Copyright Act (DMCA)
- Übergriff auf bewegliches Eigentum
- Veruntreuung
- Vertragsbruch
Octoparse ist relativ sicher und verfügt über entsprechende Sicherheitsmaßnahmen für Datenschutz und Compliance – die rechtmäßige Nutzung bleibt jedoch Sache des Benutzers.
- Datenspeicherung: Verarbeitet Daten nach branchenüblichen Standards. PII und Cloud-Scraping-Daten sind geschützt (nur autorisierte Mitarbeiter/der Benutzer selbst haben Zugriff). Lokale Daten liegen auf dem Benutzer-PC, Cloud-Daten sind verschlüsselt (Zugriff via Anmeldedaten). Benutzer können Daten exportieren/löschen.
- Rechtskonformität: Einziger Anbieter mit vollständiger Konformität zur DSGVO und CCPA, womit hohe Datenschutzstandards gewährleistet werden.
- Blockierungsverhinderung: Fortschrittlicher IP-Rotationsmechanismus reduziert Blockierungsrisiken und stabilisiert den Scraping-Prozess.
- Virenfrei: Obwohl Antivirenprogramme manchmal falsch positives erkennen, enthält die Software keine Viren (Whitelisting ermöglicht normale Nutzung

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
2. Mythos: Web Scraping und Web Crawling sind gleich
Nein, Web Scraping und Web Crawling sind nicht dasselbe.
Der Unterschied zwischen Web Crawling und Web Scraping besteht darin, dass Web-Crawler in der Regel eine große Menge an Seiten und Inhalten crawlen, um sie für Suchmaschinen zu aktualisieren, während Web-Scraper hauptsächlich dazu dienen, gewünschte Informationen zu suchen, zu extrahieren und in strukturierten Daten zur späteren Analyse auszugeben.
| | Web Crawling | Web Scraping |
| Zweck | Für die Sichtbarkeit in der Suchmaschine | Datenanalyse in allen Branchen |
| Mission | Suche nach neuen Seiten und aktualisierten Inhalten | Gewünschte Inhalte von bestimmten URL(s) finden und abkratzen |
| Anwen-dung | SEO | Marketing, Finanzen, Führung, Leben, Bildung, Social Media, Beratung… |
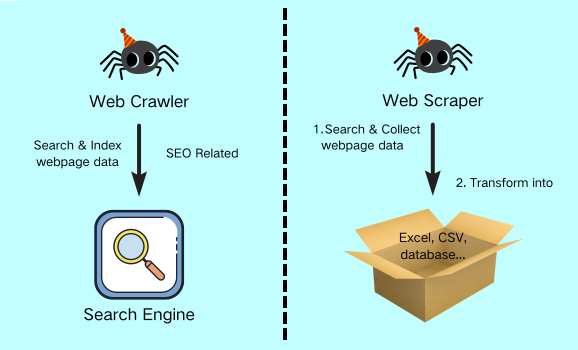
Web-Scraper sind daher ideal für Unternehmen oder Forscher, die große Mengen an Daten von Websites extrahieren und analysieren müssen. Im Gegensatz zu Web-Crawlern, die sich auf das Sammeln von Informationen konzentrieren, liegt der Schwerpunkt von Web-Scrapern auf der Extraktion und Aufbereitung von Daten. Auf diese Weise können sie Unternehmen dabei helfen, fundierte Entscheidungen zu treffen und wertvolle Erkenntnisse aus den gesammelten Daten zu gewinnen.
3. Mythos: Web Scraping ist nur für Entwickler
Dieser Mythos wird sehr oft erwähnt. Menschen ohne einen technischen Hintergrund befassen sich in der Regel nicht ausreichend mit der Kontrolle der Datenaufnahme. Das Web Scraping erfordert zwar einen geringen Prozentsatz technischer Fähigkeiten, aber es gibt Tools, die diese Voraussetzungen nicht benötigen.
Diese sogenannten Zero-Code-Tools automatisieren den Web Scraping Prozess durch vorgefertigte Vorlagen. Octoparse zum Beispiel bietet seinen Nutzern rund 500 fertige Vorlagen für das einfachere Web Scraping.
Sie können die folgende Vorlage kostenlos ausprobieren 👉
https://www.octoparse.de/template/email-social-media-scraper
4. Mythos: Web Scraper sind sehr vielseitig
Moderne Webseiten werden von Zeit zu Zeit in ihrer Struktur und den Einstellungen aktualisiert. Durch die Aktualisierung werden viele Änderungen vorgenommen. Octoparse wird jedoch regelmäßig aktualisiert, um sich an solche Änderungen anzupassen.
5. Mythos: Web Scraping und API sind das gleiche
Dieser Mythos stimmt auch nicht! API wird dazu verwendet, um eine Datenabfrage bei einem Webserver zu stellen und die benötigten Daten abzurufen. Die API gibt über ein http-Protokoll Daten im JSON-Format zurück. Aus diesem Grund können nicht beliebige Daten erhalten werden. Web Scraping ist somit durch den Erhalt von benötigten Daten etwas anderes als API.
Beide Methoden haben ihre eigenen Vor- und Nachteile, abhängig von den Anforderungen Ihrer Daten. Mit Octoparse können Sie beide Techniken nutzen, um die beste Lösung für Ihre Datenerfassungsaufgaben zu finden. Egal ob API oder Web Scraping, der Schlüssel liegt darin, die Daten effizient und zuverlässig zu erfassen, um fundierte Entscheidungen treffen zu können.
6. Mythos: Web Scraping ist Daten Hacking
Diese Annahme ist absolut falsch! Das Hacking ist eine illegale Aktivität, die darauf ausgelegt ist, Daten von privaten Netzwerken oder ganzen Computersystemen zu stehlen. Der Grund, warum Daten gehackt werden, ist immer mit Diebstahl verbunden! Daten werden illegal gesammelt, um einen persönlichen Vorteil zu erhalten.
Web Scraping legal ist das Nutzen öffentlicher Informationen auf Webseiten. Diese Informationen werden freiwillig gegeben mit dem Wissen, dass andere diese Daten etwa für die Verbesserung der Wettbewerbsfähigkeit nutzen. Das Scraping führt in diesem Fall zu fairen Angeboten und verbesserten Dienstleistungen für die Verbraucher.
7. Mythos: Daten aus dem Web Scraping sind immer einsatzbereit
Normalerweise ist das nicht der Fall! Werden Daten gesammelt, sind sehr viele Faktoren zu berücksichtigen. Zum Beispiel das Format, in dem Daten erfasst werden und das genutzte Format für die Verarbeitung.
Ein Beispiel hierfür: Die gesammelten Daten sind im JSON-Format gespeichert worden. Ihr System kann dieses Format nicht bearbeiten, denn Sie nutzen das CSV-Format. Um die Daten zu verarbeiten, ist es notwendig, die Daten zu bereinigen, zu synthetisieren und zu vereinigen. Aber die Octoparse Cloud-Funktion kann doppelte und beschädigte Daten automatisch entfernen.
8. Mythos: Web Scraping Vorgänge können einfach skaliert werden
Dieser Mythos ist ein echter Mythos! Es wird eine interne Hard- und Software betrieben, die die Datenerfassung ermöglicht. Um rund Skalierung vorzunehmen, wird ein technisches Team benötigt, das sich um die Betriebsabläufe kümmert. Um den Betrieb richtig zu skalieren, werden zusätzliche Server benötigt. Zusätzliche Server benötigen mehr Teammitglieder, die neue Scraper erstellen. Das wiederum kostet ein Unternehmen viel Geld. Nutzt man hingegen ein Web Scraping Tool von einem Anbieter. Mit dem Tool ist die Skalierung enorm einfach.
9. Mythos: Das Web Scraping ist ein automatischer Vorgang
Sehr viele Menschen denken, dass man einfach auf einen Knopf drückt und der Bot automatisch Daten erfasst und speichert. Das ist aber nicht richtig. Damit der Bot Daten suchen kann, benötigt er Angaben. Diese Angaben werden manuell eingegeben. Erst nach der Eingabe der Suchkriterien kann das System automatisch mit der Datensuche beginnen. Web Scraping ist ein komplexer Prozess, der nicht vollständig automatisch erfolgt.
FAQs
Kann eine Webseite erkennen, dass Web Scraping legal durchgeführt wird?
Webseiten können durch die Überprüfung des Verhaltens und der IP-Adresse einen Web Scraper erkennen. Wird vom Webseitenserver ein auffälliges Verhalten festgestellt kann eine IP-Adresse den weiteren Zugriff verwehrt bekommen. Das bedeutet der Zugriff wird verweigert oder gesperrt. Weitere rechtliche Hintergründe werden im Beitrag von RA Dr. Dominik Ingendaay, LL.M. „Screen Scraping und Datenschutz“ erläutert.
Wie erkennt man, ob man Web Scraping durchführen kann?
Ob eine Webseite gescrapt werden kann, erkennt man durch die Überprüfung verschiedener Faktoren. Die Überprüfung der http-Header, der Robots.txt-Datei oder Meta-Tags. Diese Faktoren geben Auskunft, ob eine Webseite automatisch ausgelesen werden kann oder nicht.
Welche Webseiten dürfen gescrapt werden?
Das Web Scraping ist legal, wenn die benötigten Daten nicht durch ein Login geschützt werden. Bevor eine Webseite für das Web Scraping legal gewählt wird, sollten immer die geltenden AGB geprüft werden. So wird sichergestellt, dass das Web Scraping legal erfolgt!
Fazit
Wie an den aufgezeigten Mythen erkennbar ist, gibt es sehr viele Missverständnisse und Mythen über das Web Scraping legal. Die Aufzählung ist nur ein kleiner Ausschnitt der unzähligen Missverständnisse.
Octoparse bietet Ihnen ein Tool für das Web Scraping legal das einfach und unkompliziert genutzt werden kann. Falls Sie das Web Scraping selbst versuchen möchten, um einige Mythen aus der Welt zu schaffen, nutzen Sie das Angebot für einen kostenlosen Test.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
👉 Dieser Artikel ist ein Originalinhalt von Octoparse.



