Ob Marktbeobachtung, Leadgenerierung, akademische Forschung oder das Trainieren von LLMs – wer große Datenmengen aus dem offenen Web bezieht, muss zwei grundlegende Disziplinen der digitalen Datengewinnung beherrschen: Web Crawling und Web Scraping. Obwohl die Begriffe häufig synonym verwendet werden, lösen sie unterschiedliche Probleme innerhalb desselben Datenflusses. Ziel des Web Crawling ist das Auffinden, Klassifizieren und Priorisieren von themenspezifischen URLs, beim Web Scraping werden anschließend die gewünschten Informationen für Reporting, Machine-Learning-Pipelines oder operative Systeme extrahiert. Wer diese Rollen sauber trennt, vermeidet unnötige Serverlast, reduziert rechtliche Risiken und erzeugt Datensätze, die langfristig wart- und nutzbar bleiben.
In diesem Leitfaden zeigen wir, wie Sie die beiden Prozesse optimal orchestrieren und mit Octoparse in wenigen Schritten eine robuste End-to-End-Pipeline für Ihre persönlichen oder geschäftlichen Zwecke aufbauen können.
Gegenüberstellung Web Crawling & Web Scraping
| Dimension | Web Crawling | Web Scraping |
| Zweck | Relevante URLs sammeln | Strukturierte Datenextrahieren |
| Input | Seed-URLs, Link-Parsing | Liste gecrawlter URLs |
| Output | URL-Frontier / Sitemap | CSV, JSON, Datenbank |
| Herausforderung | Coverage, robots.txt | Selektor-Stabilität, Anti-Bot |
| Typische Tools | Octoparse Crawl, Scrapy | Octoparse, Playwright |
| KPI-Beispiele | Duplicate-Rate, Crawl-Delay | Field-Completeness,Freshness |
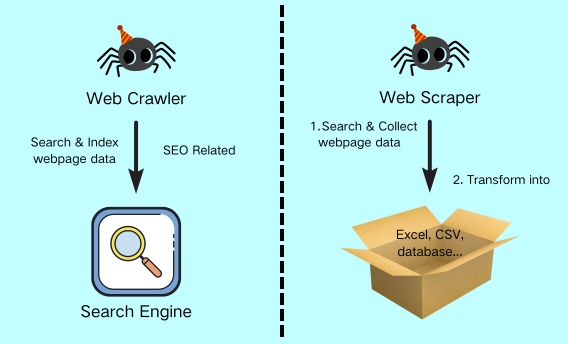
Was ist Web Crawling?
Beim Web Crawling setzt ein automatisierter Bot – häufig Spider genannt – an einer zuvor festgelegten, ersten Internetadresse an (Start-URL). Das Programm ruft die Seite per HTTP ab, analysiert deren Struktur und extrahiert sämtliche ausgehenden Links. Diese werden in einer Warteschlange gespeichert, vergleichbar mit einer dynamisch wachsenden Aufgabenliste. Eine integrierte Steuerungslogik priorisiert anschließend die Einträge: Adressen, die sich nachweislich oft ändern oder als thematisch besonders relevant eingestuft werden, rücken nach oben; weniger wichtige Links werden zurückgestellt. Damit nutzt der Crawler seine Ressourcen effizient und vermeidet unnötigen Traffic. Suchmaschinen wie Google oder Bing durchlaufen auf diese Weise täglich Milliarden von Seiten und setzen dabei hochentwickelte Priorisierungs-Algorithmen ein, um neue oder aktualisierte Inhalte nahezu in Echtzeit zu erfassen. In Unternehmens- oder Forschungsprojekten ist der Projektumfang naturgemäß geringer, das Vorgehen bleibt jedoch identisch: Erst wenn klar ist, welche Seiten existieren und in welcher Reihenfolge sie abgerufen werden sollen, lohnt sich der nächste Verarbeitungsschritt: Das Web Scraping.
Was ist Web Scraping?
Web Scraping setzt genau dort an, wo Web Crawling aufhört. Ein spezielles Programm – der Scraper – ruft jede zuvor im Crawling-Prozess ermittelte und hierarchisierte URL auf, rendert bei Bedarf auch clientseitiges JavaScript und filtert exakt die Informationen heraus, die später ausgewertet werden sollen: Etwa Überschriften, Preise, Produktbilder oder Meta-Tags. Diese Daten werden unmittelbar in ein strukturiertes Format geschrieben – zum Beispiel CSV, JSON, Parquet oder wahlweise direkt in eine Datenbank. Moderne Scraper arbeiten häufig mit sogenannten Headless-Browsern (unsichtbar laufende Browser-Instanzen wie Chromium oder Playwright) beziehungsweise dem integrierten Rendering-Modul von Octoparse. Dadurch können sie mit komplexen Seiten interagieren, Captchas über externe APIs lösen, Cookies verwalten und bei endlosem Scrollen (vgl. Infinite Scroll) automatisch nachladen. Gleichzeitig lassen sich Werte noch während der Erfassung vereinheitlichen – etwa Preise in eine einheitliche Währung oder Datumsangaben in ISO-Form.
Das Ergebnis ist ein sauber aufbereiteter, sofort auswertbarer Datensatz, der ohne manuelle Zwischenschritte direkt in Business-Intelligence-Dashboards oder Machine-Learning- Pipelines einfließt.
Web Crawling & Web Scraping in der Praxis
Beispiel einer schlanken End-to-End-Pipeline
Eine durchdachte Datenpipeline trennt Crawling und Scraping klar voneinander und definiert für jede Etappe eigene Qualitäts- und Kontrollpunkte. Mit Octoparse decken Sie den operativen Teil der Pipeline nahezu end-to-end ab. Nur die strategische Auswahl der Startpunkte und die datengetriebene Feinsteuerung im Feedback-Loop liegen (bewusst) außerhalb des Tools.:
1. Seed-Sammlung – Ein Analyst / eine Analystin stellt eine geprüfte Liste von relevanten Domains oder Deep-Links bereit, die als Startpunkte dienen.
2. Crawling – Ein Octoparse-Task im Modus Crawl Only folgt den Links bis maximal drei Ebenen tief, berücksichtigt die Vorgaben aus robots.txt und schreibt jede gültige Produkt-URL samt Zeitstempel in eine Cloud-Datenbank.
3. Vorfilter – Ein RegEx-Filter entfernt unerwünschte URL-Parameter (z. B. Affiliate-Tags) und Doppelungen wie /amp/-Varianten, um Datenballast zu vermeiden.
4. Scraping – Ein zweiter Octoparse-Task besucht jede gespeicherte URL, scrollt bei
Infinite Scroll automatisch nach, extrahiert Produktname, Preis, Lagerbestand, SKU, Bewertung und Kategorie und speichert das Ergebnis als CSV oder direkt per API im Data Lake-House.
5. Das integrierte Data-Cleaning-Modul von Octoparse kann Rohdaten bereits während des Exports aufbereiten: Spalten umbenennen, Werte normalisieren, Dubletten entfernen und Währungen vereinheitlichen. Anschließend überträgt das Tool die bereinigten Datensätze per API direkt in Ihr BI-System. Für tiefergehende Analysen – etwa Preisverteilungen oder statistische Modelle – lässt sich optional ein nachgelagertes Python- oder R- Notebook einsetzen.
6. Feedback-Loop – Erkenntnisse aus den Reports erzeugen neue Seeds oder modifizieren Crawl-Parameter; so bleibt die Pipeline fokussiert und aktuell.
Eine Seed-Sammlungkuratieren
Vielleicht haben Sie sich beim Lesen bereits gefragt, wie man diese ersten, entscheidenden Start-URLs überhaupt auswählt – schließlich steht und fällt die Qualität des gesamten Crawls mit ihnen. Die folgenden drei Schritte helfen dabei, ein belastbares Seed-Set zusammenzustellen:
1. Ziel ableiten – Domainliste erstellen
Bestimmen Sie zuerst, welche Daten Sie sammeln wollen (z. B. Preise, Stellenanzeigen). Sammeln Sie dann passende Domains oder Deep-Links: Hersteller- oder Shop-Startseiten, Kategorie-Übersichten, öffentliche Sitemaps oder Google-Suchergebnisse mit site: + Keyword.
2. Linkdichte & Relevanz prüfen
Bevor Sie die URLs in den Crawl geben, öffnen Sie Stichproben manuell: Enthält die Seite wirklich die gewünschten Inhalte? Hat sie viele interne Links, die weiterführen? Vermeiden Sie dynamische Such-URLs mit Session-IDs oder Parametern wie “sort=”, die nur Duplikate erzeugen.
3. Klein, sauber, versioniert
Ein kurzes, gut gepflegtes Seed-Set (oft < 50 URLs) liefert bessere Ergebnisse als tausend unkontrollierte Links. Dokumentieren Sie Datum und Zweck jeder Seed-URL; so können Sie später nachvollziehen, warum bestimmte Daten (nicht) gefunden wurden und bei Bedarf zielgerichtet nachjustieren.
Typische Anwendungsfälle
| Use-Case | Crawling-Anteil | Scraping-Anteil | Business-Nutzen |
| Preisbeobachtung E-Commerce | Hoch | Hoch | Sortimentsabdeckung & tagesaktuellePreise |
| News Monitoring | Mittel | Hoch | Inhalte ändern sichtäglich, URLs selten |
| Lead-Generierung | Hoch | Mittel | Viele Unterseiten, wenig Info pro Seite |
| SEO-Audit | Hoch | Gering | Struktur wichtiger alsInhalt |
| ML-Trainingsdaten | Mittel | Hoch | Diversität erfordertbreites Crawling |
Rechtliche und ethische Aspekte
Technische Machbarkeit garantiert noch lange keine Rechtmäßigkeit. In der EU schützt die sogenannte DSM-Richtlinie urheberrechtlich geschützte Inhalte; personenbezogene Daten unterliegen der DSGVO. Seriöse Projekte respektieren nicht nur robots.txt, sondern setzen auch angepasste Crawl-Delays und einen sprechenden User-Agent, der eine Kontakt-Adresse enthält. Ebenso sollte klar sein, dass das Umgehen technischer Schutzmaßnahmen wie Captcha-Bypassing juristische Graubereiche berührt, die vor Projektstart von einem spezialisierten Rechtsberater geprüft werden sollten.
Ein praxisbewährter Ansatz ist das Konzept Legal-by-Design:
1. Purpose Limitation – legitimen Zweck der Datenerhebung dokumentieren.
2. Data Minimisation – nur Daten extrahieren, die tatsächlich benötigt werden.
3. Storage Limitation – personenbezogene Daten pseudonymisieren oder zeitnah löschen.
4. Transparency – Opt-out-Möglichkeit bereitstellen und zügig auf Löschanfragen reagieren.
5. Audit Trail – Requests, Response-Header und Transformationsschritte loggen, um Compliance-Nachweise zu ermöglichen.
Häufige Stolpersteine – und wie Sie sie umgehen
Selector-Brüche, Layout-Shifts oder Anti-Bot-Hürden führen schnell zu unnötigem Leerlauf. Hier die drängendsten Probleme und ihre praxis erprobten Gegenmittel:
- HTML-Änderungen (Selector-Bruch) – Baut die Website ihr Layout um, treffen starre XPath-Pfade nicht mehr die gewünschten Elemente. Tipp: Verwenden Sie möglichst semantische Selektoren (Klassen-, ID- oder data-*-Attribute), die sich seltener ändern.
- Asynchrones Laden / Infinite Scroll – Inhalte erscheinen erst nach zusätzlichem Scrollen oder Klick. Tipp: Aktivieren Sie in Octoparse das Auto-Scroll-Feature oder definieren Sie Scroll-Events, bis keine neuen Elemente mehr auftauchen.
- Anti-Bot-Schutz – Captchas, IP-Blocking oder strenge Rate-Limits stoppen den Crawler. Tipp: Nutzen Sie Proxy-Rotation (residential oder ISP) und variieren Sie den User- Agent; Octoparse bringt beides standard mäßig mit.
- Unbemerkt sinkende Datenqualität – Fehler fallen erst auf, wenn Berichte falsch sind. Tipp: Implementieren Sie Live-Monitoring von HTTP-Status, Selektor- Trefferquote und Daten-Freshness in einem Dashboard (Octoparse-Cloud oder eigenes BI-Tool).
- Redundante Abrufe – Der Bot lädt täglich Tausende unveränderter Seiten. Tipp: Führen Sie inkrementelles Crawling ein: Vergleichen Sie Zeitstempel oder Checksummen und rufen Sie nur neue oder geänderte Seiten ab.
Mit diesen Best Practices halten Sie Ihre Pipeline stabil und sparen sich kostspielige Nacharbeiten.
Architekturentscheidungen für Skalierung
Wenn Ihr Projekt mehr Datenquellen oder höhere Abrufraten benötigt, hilft das Crawler- Scraper-Modell dabei, Last sauber zu verteilen – und Octoparse bringt diese Architektur praktisch schon mit.
1. Crawler-Task Aufgabe: Links beschaffen. Ein Octoparse-Job im Modus Crawl Only sammelt URLs und schreibt sie fortlaufend in eine gemeinsame Warteschlange (Message Queue).
2. Scraper-Task Aufgabe: Inhalte extrahieren. Ein zweiter Octoparse-Job liest die URLs aus der Queue, rendert JavaScript-Seiten bei Bedarf und speichert die extrahierten Daten direkt in Ihrer Zieldatenbank oder im Cloud-Speicher.
3. Horizontale Skalierung: Benötigen Sie mehr Durchsatz, starten Sie einfach weitere Scraper-Instanzen in der Octoparse-Cloud. Jeder zusätzliche Run greift sich URLs aus derselben Warteschlange, ohne dass Sie Infrastruktur anpassen müssen.
4. Lastverteilung & Fehlertoleranz: Fällt ein Scraper aus, bearbeiten die übrigen Instanzen die verbleibenden Links weiter; der Crawl selbst läuft stabil weiter. So vermeiden Sie Engpässe und Single Points of Failure.
Mit dieser Aufteilung können Sie klein starten und bei wachsendem Datenbedarf schrittweise skalieren – ganz ohne eigene Server oder komplexes Queue-Management.
Wo steht Octoparse im Tool-Ökosystem?
Am Markt gibt es primär drei Arten von Lösungen, wenn es um Datenextraktion geht:
1. Code-Frameworks – hohe Flexibilität, aber Programmier kenntnisse und Infrastruktur notwendig.
2. Managed APIs – komplette Data as a Service, dafür weniger Einfluss auf Detail regeln.
3. Visuelle No-Code-Plattformen – genau hier positioniert sich Octoparse und schlägt eine Brücke zwischen Self-Service und Enterprise-Skalierung.
Mit Octoparse arbeiten Sie nach dem Prinzip Zeigen, Klicken, Extrahieren: Selektoren werden per Point-and-Click festgelegt, Pagination oder Infinite Scroll via Assistent konfiguriert und der gesamte Workflow per Mausklick in die Cloud verlagert.
Kernfeatures auf einen Blick
- Visual Designer – Selector-Erstellung ohne Code, inklusive Vorschau und Auto- Detect.
- Automatisches Proxy-Management – integrierter Pool aus Residential- und ISP-IP- Adressen plus Rotationslogik.
- Headless-Rendering – JS-lastige Seiten werden serverseitig gerendert, Captchas lassen sich über Dritt-APIs lösen.
- Cloud-Scheduler – Tasks als Einzel- oder Parallel-Runs planen, Skalierung per Schieberegler.Erweiterte Authentifizierung – Cookie-Importer, Formular-Login, 2FA-Handling für passwortgeschützte Bereiche.
Damit eignet sich Octoparse gleichermaßen für Business-Analysten, die ohne Entwicklungsaufwand Daten extrahieren wollen, und für Tech-Teams, die ihre Pipelines schnell in Produktions umgebungen bringen möchten.
Zusammenfassung
Web Crawling (Suchen) und Web Scraping (Extrahieren) sind zwei komplementäre Schritte derselben Daten-Pipeline. Wer ihre Aufgaben klar trennt und trotzdem gemeinsam überwacht, gewinnt aktuelle, belastbare Informationen – und bleibt zugleich auf der sicheren Seite in Sachen Compliance.
Mit Octoparse stehen dafür alle Bausteine in einer einzigen No-Code-Plattform bereit: Visual Designer, Proxy-Management, Headless-Rendering und Cloud-Scheduler lassen sich per Mausklick kombinieren, ohne eigene Infrastruktur hochzufahren. So können kleine Teams schnell produktionsreife Workflows aufbauen, während erfahrene Entwicklerinnen und Entwickler dieselben Jobs bei wachsendem Bedarf horizontal skalieren.
Das Wichtigste auf einen Blick
1. Hochwertige Seeds entscheiden über Datenqualität.
2. Crawling und Scraping getrennt betreiben, aber gemeinsam monitoren.
3. Kernmetriken wie Trefferquote, Duplicate-Rate und Freshness regelmäßig prüfen.
4. Octoparse-Cloud für parallele Runs nutzen; keine eigene Infrastruktur nötig.
Mit diesem Werkzeug- und Methodenkasten sind Sie bestens gerüstet, um aus Suchen & Extrahieren eine skalierbare, belastbare Datenstrategie zu machen.
Bei Fragen zur Datenextraktion oder für Verbesserungsvorschläge kontaktieren Sie uns gerne per E-Mail (support@octoparse.com). 💬
Testen Sie Octoparse jetzt 14 Tage lang kostenlos!

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



