Immer wieder kommt man in die Situation, dass man Preise im Internet vergleichen möchte. Sei es für den Urlaub oder weil man etwas kaufen möchte. Auch im Geschäftsbereich ist es immer wieder notwendig, Daten zu suchen und für Vergleichs- oder Entscheidungszwecke zu nutzen. Web Scraping macht das Finden und Speichern von Daten einfach und unkompliziert möglich!
Beim Web Scraping handelt es sich um das Extrahieren von Daten und Inhalten auf Internetseiten mit der Unterstützung einer Software. Ein gutes Beispiel für einen Web Scraper stellt Google dar. Die Google Suchmaschine zum Beispiel scrapt Daten. Und zwar nach Ihrer Suchanfrage im Internet. Die gesuchten Begriffe werden gesucht und die Ergebnisse für Sie gereiht.
Ein anderes Beispiel ist ein Online-Dienst, der Preisvergleiche anbietet. Dieser Dienst nutzt ebenfalls das Web Scraping, um aus verschiedenen Webseiten die Preise auszulesen und für Sie aufzubereiten, um Vergleiche anstellen zu können.
Web Scraping – was ist das genau?
Um Daten automatisch aus dem Internet auslesen zu können, werden verschiedene Verfahren kombiniert und angewendet. Diese Sammlung von Verfahren für das Extrahieren von Daten wird Web Scraping genannt. Für das Web Scraping stehen mittlerweile unterschiedliche Tools zur Verfügung, die das Scrapen von Daten aus dem Web enorm vereinfachen.
Für den Begriff “Web Scraping” stehen weitere Begriffe, die die gleiche Bedeutung haben. Zum Beispiel “Data Scraping” oder auch “Content Scraping”. Welche Bezeichnung man nutzt, ist eigentlich ganz egal. Im Endeffekt geht es nur darum, Daten aus dem Internet zu filtern, kopieren und einfügen in eine andere Datei.
Einige Anwendungsgebiete für das Scraping sind zum Beispiel
● Preisvergleiche
● Marktforschungen
● Überwachung von Inhalten
und einiges mehr. Was genau beim Web Scraping passiert und wie es möglich ist, Daten auszulesen, erfahren Sie im folgenden Beitrag.
Wie genau funktioniert das Web Scraping?
Der Begriff Web Scraping hört sich für viele Menschen kompliziert an. Im Großen und Ganzen ist es aber nur das Finden der gewünschten Daten auf verschiedenen Webseiten. Wurden die gewünschten Informationen gefunden, werden sie kopiert und für das Einfügen in eine Excel-Tabelle oder andere Datei vorbereitet.
Haben Sie vielleicht schon einmal Daten auf einer Webseite kopiert und in einer anderen Datei gespeichert? Ja? Dann haben Sie Web Scraping händisch durchgeführt, ohne es zu wissen. Für das Scraping im Internet stehen unterschiedliche Methoden und Tools zur Verfügung.
Diese Methoden und Tools nutzen Scraper und Crawler, um automatisch die erforderlichen Daten auf verschiedenen Webseiten zu finden und auszulesen. Mit einem spezialisierten Tool, zum Beispiel Octoparse, können einfach viele verschiedene Webseiten innerhalb kurzer Zeit durchsucht werden. Sie erhalten damit die benötigten Daten rasch und sehr einfach.
Der grundlegende Ablauf des Web Scraping
Web Scraping ist im Grunde genommen nur einige einfache Schritte vorzunehmen. (Kurzbeschreibung der Vorgehensweise!)
- Nutzen Sie bei Octoparse die vorangefertigte Vorlage und geben Sie Ihre benötigten Daten zur Abfrage ein. Die benutzerfreundliche Oberfläche des Tools zeigt Ihnen, wo Sie Ihre Schlüsselwörter, URLs etc. eingeben können.
- Nach der Eingabe aller notwendigen Informationen kann das Tool gestartet werden. Sie erhalten alle gescrapten Daten aufgelistet.
- Die ausgelesenen Daten können danach beliebig von Innen zur weiteren Verwendung gespeichert werden.
Kurzer Überblick über den Unterschied zwischen Scrapern und Crawlern
Das Web Scraping kann einfach mit einem Zugpferd vor einem Pflug verglichen werden. Das Pferd ist dafür zuständig den Pflug zu ziehen und der Pflug öffnet den Boden, um in späterer Folge Saatgut aufzubringen. Gleichzeitig werden Rückstände der letzten Ernte und Unkraut unter die Erde gedrückt.
Beim Web Scraping übernimmt der Crawler die Funktion des Zugpferdes. Der Scraper hingegen übernimmt die Rolle des Pfluges. Er pflügt durch digitale Felder und filtert unnötiges aus.
Die Aufgaben von Crawler und Scraper:
Crawler:
- Der Crawler, oft auch “Spider” genannt, ist ein Programm, das das Internet durchsucht und Inhalte indiziert. Der Crawler wird dabei durch den Scraper geführt. Es steht aber nicht nur diese Vorgehensweise zur Verfügung. Internet-Suchmaschinen benutzen Crawler normalerweise, um Webseiten zu bewerten. Durch die Bewertung können sie indexiert werden. Nach der Indexierung erfolgt die Reihung im Ranking. Bei den Crawlern handelt es sich um Tools, bei denen man einen bestimmten Suchbegriff oder den URL einer Webseite eingeben kann.
Scraper:
- Der Scraper macht immer schmutzige Arbeit, wenn er Informationen aus dem Internet ausliest. Die meisten Webseiten sind mittels HTML strukturiert. Aus diesem Grund werden von Scraper Ausdrücke wie zum Beispiel CSS-Selektoren, XPath und weitere Locators verwendet, um gesuchte Inhalte rasch zu finden und zu kopieren. Geben Sie zum Beispiel einen normalen Ausdruck ein, der ein Schlüsselwort oder Markennamen enthält. Der Scraper wird diesen Begriff rasch finden und anzeigen.
Hinweis: Im Normalfall enthalten Tools für das Web Scraping Crawler und Scraper, die komplizierten Anforderungen spielend lösen können.
Was kann man aus dem Internet scrapen?
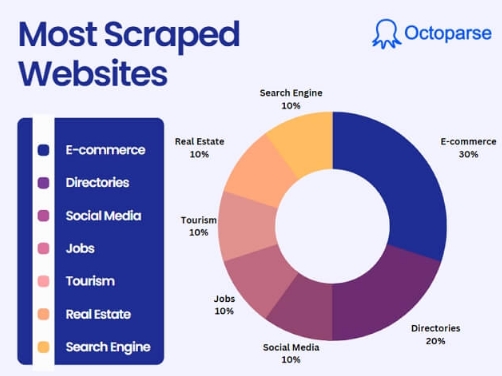
Sie haben die Möglichkeit, das Internet oder das Web nach allen Arten von Daten zu durchsuchen. Das beginnt bei Suchmaschinen über die RSS-Feeds bis zu Informationen von der Regierung. Der Großteil der Webseitenbetreiber stellt Daten für Crawler, Scraper und andere Varianten der Datenerfassung zur Verfügung.
1. Markt- und Wettbewerbsanalyse
Preisüberwachung und Wettbewerberanalyse leicht gemacht! Mit einem leistungsstarken Web Scraper können Sie Preise, Rabatte und Angebote von E-Commerce-Websites verfolgen sowie wichtige Daten wie Produktdetails und Kundenbewertungen Ihrer Wettbewerber extrahieren. Diese Informationen ermöglichen es Ihnen, eine Preisvergleichs-Website zu erstellen, die Käufern hilft, die besten Angebote zu finden. So erfüllen Sie ein wichtiges Bedürfnis und generieren Tausende von Zugriffen – Monat für Monat. Profitieren Sie von datenbasierten Einblicken und verschaffen Sie sich einen Wettbewerbsvorteil!
2. Lead-Generierung und Sales-Strategien
Die Extraktion geschäftlicher Kontaktdaten, etwa aus Gelbe Seiten, LinkedIn oder Unternehmensverzeichnissen, bildet die Grundlage für erfolgreiche B2B-Marketing-Kampagnen. Kombiniert mit der Analyse sozialer Netzwerke können Sie potenzielle Zielgruppen präzise identifizieren und personalisierte Angebote erstellen, die exakt auf deren Bedürfnisse abgestimmt sind. Diese datengetriebene Herangehensweise ermöglicht es Ihnen, relevanter und effektiver mit Ihren Kunden zu kommunizieren – der perfekte Weg, um Ihre Kampagnen auf das nächste Level zu heben und messbare Erfolge zu erzielen.
3. Immobilien- und Job-Marktplätze
Die Überwachung des Immobilienmarkts durch automatische Datensammlung von Immobilienportalen ermöglicht es, Preise, Verfügbarkeit und Standortinformationen stets im Blick zu behalten. Gleichzeitig bietet das Scraping von Stellenanzeigen eine ideale Grundlage, um Trends im Arbeitsmarkt zu erkennen oder schneller auf neue Jobmöglichkeiten zu reagieren. Beide Ansätze liefern wertvolle Einblicke, die Sie dabei unterstützen, fundierte Entscheidungen zu treffen und sowohl beruflich als auch privat einen Wettbewerbsvorteil zu erzielen.
4. Content-Aggregation und Recherche
Die Zusammenstellung von Nachrichtenartikeln zu spezifischen Themen durch Scraping von Nachrichten-Websites ermöglicht eine gezielte Content-Kuration, die aktuelle und relevante Informationen bereitstellt. Gleichzeitig eröffnet die Extraktion aus Open-Access-Datenbanken eine Fülle wissenschaftlicher Daten, die als Basis für Forschungsprojekte dienen. Beide Ansätze schaffen einen strukturierten Zugang zu Wissen und fördern datengetriebene Entscheidungsprozesse in verschiedenen Bereichen.
5. Finanzanalysen und Investitione
Das Live-Tracking von Aktienkursen und Finanzdaten liefert entscheidende Informationen für fundierte Investitionsentscheidungen. Ergänzend dazu ermöglicht das Sammeln von Finanzberichten und geschäftsrelevanten Daten eine gründliche Due-Diligence-Prüfung, um Unternehmensbewertungen präzise durchzuführen. Diese datenbasierte Herangehensweise bietet eine solide Grundlage für strategische Finanzentscheidungen und minimiert gleichzeitig Risiken bei Investitionen oder Geschäftsabschlüssen.
6. E-Commerce-Optimierung
Die Analyse von Kundenbewertungen auf Plattformen wie Amazon oder eBay bietet wertvolle Einblicke, um eigene Produkte kontinuierlich zu verbessern und an den Bedürfnissen der Zielgruppe auszurichten. Gleichzeitig ermöglicht das Verfolgen von Bestsellern, Neuheiten und Kategorien, aktuelle Markttrends zu erkennen und proaktiv auf Veränderungen zu reagieren. Diese datengetriebenen Strategien helfen dabei, wettbewerbsfähig zu bleiben und Produkte sowie Angebote optimal an die Anforderungen des Marktes anzupassen.
7. Reise- und Tourismusbranche
Durch das Scraping von Flug- und Hotelpreisen lassen sich Reisevergleichsplattformen erstellen, die Nutzern helfen, die besten Angebote zu finden. Ergänzt durch die Analyse von Bewertungen und Empfehlungen auf Plattformen wie TripAdvisor oder Google Maps können die attraktivsten Reiseziele und zuverlässigsten Dienstleistungen identifiziert werden. Mit diesen datenbasierten Insights wird die Reiseplanung einfacher, transparenter und garantiert die besten Erlebnisse für Ihre Kunden.
8. Automotive Website erstellen
Das Web Scraping kann auch verwendet werden, um eine Automotive Website zu erstellen, auf der aggregierte Auto-Listings angezeigt werden. Ein Scraping Car Listing würde bedeuten, dass Web-Crawler bestimmte Daten aus relevanten Quellen wie Websites von Fahrzeugunternehmen und anderen Automobil-Websites kratzen. Alle Informationen über verschiedene Autos zu haben, würde dazu beitragen, das Einkaufserlebnis Ihrer Nutzer zu verbessern.
9. Sportdatenservice anbieten
Die Sportdaten-Dienstleister sind Websites, die Sportdaten wie Spielerprotokolle, Spielverlauf und Sportagenturen in jeder Sportsaison verkaufen. Auch Sie können eine Website mit demselben Ziel erstellen. Es ist ein großer Markt mit wenig Wettbewerb.
Der Grund dafür ist, dass Sportdaten riesig sind. Sie können auf verschiedene Arten von verschiedenen Unternehmen mit unterschiedlichen Zielen interpretiert werden. Die Sportwetten-Buchmacher verwenden beispielsweise Sportdaten, um Wettquoten festzulegen.
10. Job Aggregator Website erstellen
Ein Job Aggregat ist eine Website, die Stellenangebote von verschiedenen Websites in einer durchsuchbaren Online-Benutzeroberfläche zusammenfasst. Menschen gehen online, um nach Jobs zu suchen. Wenn Sie also Stellenanzeigen von Indeed, LinkedIn und anderen relevanten Quellen durchsuchen können, sollten Sie in der Lage sein, eine Website zu erstellen, die Arbeitssuchenden hilft, einen guten Job zu finden.
Daten sind nicht immer verfügbar
Es kommt beim Web Scraping immer wieder vor, dass Daten nicht verfügbar sind. Bei einigen Webseiten ist es notwendig, weitere Tools oder auch Tricks anzuwenden, um die benötigten Daten zu erhalten. Einige Webseitenbetreiber blockieren das Web Scraping auch. Das bedeutet, sie stellen Daten nicht zum scrapen zur Verfügung.
Einige Web Scraping Tools können aus visuellen Inhalten zum Beispiel keine Daten auslesen. Mit dem Web Scraper von Octoparse haben Sie damit keine Probleme. Dieses Web Scraping Tool findet die gesuchten Daten schnell und unkompliziert und ist sehr einfach zu bedienen!
Ist das Web Scraping legal?
Das Web Scraping macht es möglich, Daten auszulesen und für weitere Zwecke zu nutzen. Dabei entsteht aber immer wieder die Frage: “Ist das Web Scraping legal?”. Diese Frage ist verständlich. Manchmal fühlt man sich beim Auslesen von Daten wie ein Dieb.
Es ist auf keinen Fall Diebstahl und somit legal Daten aus dem Internet für weitere Zwecke zu nutzen. Aber nur dann, wenn diese Daten öffentlich zugänglich sind! Jeder Webseitenbetreiber, der Daten öffentlich auf seiner Webseite der Öffentlichkeit zur Verfügung stellt, erlaubt gleichzeitig, dass Daten scrapen.
Ein gutes Beispiel ist hier Amazon oder auch Webseiten, die Urlaubsreisen anbieten. Diese Webseiten zeigen die Preise ihrer Produkte und es ist absolut legal, diese Daten für Vergleichszwecke zu scrapen. Vergleichsportale zum Beispiel nutzen das Web Scraping, um Ihnen die günstigsten Anbieter aufzuzeigen.
Es sind aber nicht immer alle Daten auf Webseiten für die Allgemeinheit verfügbar. Aus diesem Grund können diese Daten nicht ausgelesen und kopiert werden. Das ist vor allem bei geistigem Eigentum und persönlichen Daten der Fall!
Werden persönliche Daten und Daten aus geistigem Eigentum ausgelesen und verwendet, wird das rasch zu bösartigen oder illegalem Scraping! Für illegales Web Scraping drohen hohe Strafen, weil damit die DSGVO verletzt wird!
Wo wird das Web Scraping häufig genutzt?
Web Scraping wird in der Regel für notwendige oder nützliche Zwecke eingesetzt. Daten aus verschiedenen Webseiten auszulesen und zu vergleichen, wird häufiger benötigt, als Sie denken.
Die häufigsten Bereiche des Web Scraping:
- in der Marktforschung
- zur Geschäftsautomatisierung
- um Inhalte von Nachrichten zu erhalten
- zur Lead-Generierung im Geschäftsbereich
- zur Überwachung der eigenen Marke
- im Immobilienbereich
- zum Preise verfolgen
FAQs
Können Webseiten erkennen, dass Web Scraping vorgenommen wurde?
Ja, Webseiten können Web Scraping erkennen! Server können Verkehrsmuster und IP-Adressen erfassen und analysieren. Spezielle Erkennungssysteme, die auf Webseiten installiert werden, können Unregelmäßigkeiten erkennen und Bots blockieren.
Kann Web Scraping erkannt und blockiert werden?
Durch spezielle Mechanismen können Webseiten das Scraping wahrnehmen. Das kann zur Folge haben, dass zu viele Abfragen in kurzer Zeit eine Sperre der IP auslösen können.
Was sagt für DSGVO zum Web Scraping?
Solange die Vorschriften der DSGVO betreffend die personenbezogenen Daten und dem geistigen Eigentum eingehalten werden, ist es erlaubt. Benötigen Sie jedoch Daten aus geistigem Eigentum oder personenbezogene Daten, die nicht zur freien Verfügung stehen, muss eine ausdrückliche Zustimmung für das Scraping eingeholt werden!
Fazit
Die modernen Tools für das Web Scraping von Octoparse rationalisieren das Scraping enorm. Die Erfassung der benötigten Daten erfolgt rasch und unkompliziert. Durch die Möglichkeit, automatisierte Aufgaben nach Ihren eigenen Bedürfnissen zu planen, ist das Tool als sehr flexibel zu bezeichnen.
Sie können Abfragen zum Beispiel monatlich, wöchentlich, täglich oder stündlich vollkommen automatisch durchführen. Dadurch erhalten Sie die benötigten Daten immer aktuell. Sie können sie zum Beispiel als Grundlage für Ihre Entscheidung im Geschäftsbereich nutzen.
In Zukunft werden die zur Verfügung stehenden Tools für das Web Scraping sicherlich noch mehr Vorteile bieten. Zum Beispiel wird der Einsatz von KI bei der Datensuche sicherlich noch verbessert werden. Die angebotenen Tools werden dadurch noch einfacher zu bedienen und noch schneller im Datenauslesen werden.
Zusammenfassend kann gesagt werden, dass Web Scraping eine große Macht besitzt und sehr hilfreich ist. Gleichzeitig stellt es für einige Webhoster eine hohe Gefahr dar. Egal ob Sie Web Scraping nutzen oder eine Webseite betreiben. Der sorgsame und vor allem verantwortungsvolle Umgang mit Daten sollte immer an erster Stelle stehen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



