Durch mobile.de spielen sich Autokauf und Autoverkauf für die meisten Menschen in erster Linie im Internet ab. Hier werden Informationen eingeholt, Preise verglichen und Bewertungen studiert. Schließlich möchte man über das betreffende Fahrzeug sehr gut informiert sein. Möchte man ein Fahrzeug verkaufen, sind die derzeitigen Preise und der Verkaufswert sehr wichtig. Beim Autokauf geht es um den Verkaufspreis und die angebotenen Fahrzeuge. Auch der Zustand dabei spielt eine wichtige Rolle. Zudem liefern die Bewertungen anderer Nutzer den Verkäufer sehr viele wichtige Informationen.
Mobile.de ist der größte online Fahrzeugmarkt und bietet Neu- und Gebrauchtwagen von Privatpersonen und Händlern. Möchte man sehr viele Informationen sammeln und diese vergleichen, ist der vom Unternehmen angebotene Filter oder auch mobile.de Scraper sehr oft nicht ausreichend. Durch die Wahl der Suchparameter werden zwar gewünschte Modelle und Informationen angezeigt. Jeder einzelne Treffer muss danach jedoch extra geöffnet werden, um weitere Informationen zu erhalten. Mit Octoparse, dem Scraping Tool können Informationen schnell und zuverlässig ausgelesen und ausgegeben werden. Im Folgenden erfahren Sie, warum Octoparse die bessere Lösung ist.
Warum auf mobile.de Daten scrapen hilfreich ist?
Der größte Fahrzeugmarkt im Internet im europäischen Raum ist mobile.de. Er enthält eine enorm große Datenbank mit Informationen über Neu- und Gebrauchtfahrzeuge, Nutzfahrzeuge aller Art und Motorräder. Wird auf dieser Plattform ein Daten-Scraping durchgeführt, kann man wertvolle Daten für Preisstrategien, Marktanalysen und zur Bestandsoptimierung gewinnen. Aber auch Privatpersonen, Unternehmen und Marktforscher können von den Daten enorm profitieren. Privatpersonen können damit zum Beispiel einfacher das gesuchte Fahrzeug finden und damit leichter eine Kaufentscheidung treffen.
Unternehmen wiederum können die Konkurrenz beobachten und die Preise anpassen. Es ist auch möglich, die gefragtesten Modelle festzustellen, um sich einen Wettbewerbsvorteil zu verschaffen. Durch die gespeicherten historischen Daten ist es für Verkäufer und Käufer einfacher, Wertverluste der Fahrzeuge festzustellen. Die Preisgestaltung oder Preisverhandlungen bei einem Kauf oder Verkauf von Fahrzeugen können zum Beispiel durch diese fundierten Daten einfacher werden.
Die verfügbaren Daten, wie zum Beispiel Spezifikationen von Fahrzeugen, Preise, Kilometerstand, können noch mehr nutzen. Zum Beispiel tragen sie dazu bei, Versicherer, Finanzinstitute und Technologieunternehmen bei der Entwicklung der fahrzeugbezogenen Apps oder bei der Risikobewertung zu unterstützen. Mit dem mobile.de Scraper kann man sehr viel Zeit sparen. Gleichzeitig wird die Datenerfassung genauer und zuverlässiger. Die gesammelten Daten sind außerdem skalierbar. Damit bleibt man am ständig aktiven Automobilmarkt immer am laufenden.
Mit Octoparse Daten scrapen auf mobile.de
Octoparse macht es möglich, einfach benötigte Daten von mobile.de zu scrapen. Wenige Schritte reichen aus und Sie erhalten innerhalb von Minuten Ihre gewünschten Daten und können sie beliebig speichern.
Für Octoparse benötigen Sie keine Kenntnisse im Programmieren. Die Oberfläche ist benutzerfreundlich und übersichtlich gestaltet. Mit Octoparse erhalten Sie einen zuverlässigen Helfer, der Ihnen das mobile.de Scraping enorm erleichtert. Mit den angezeigten Schritten erhalten Sie Ihren eigenen mobile.de Scraper und können sofort Daten auslesen.
Schritt für Schritt Anleitung:
1. Schritt: Octoparse herunterladen, anmelden und URL eingeben
Laden Sie Octoparse auf Ihren PC oder Laptop herunter und installieren Sie sie. Wurde Octoparse installiert, können Sie sich ein kostenloses Benutzerkonto anlegen. Mit der Eingabe der ausgewählten mobile.de URL in die Octoparse Suchleiste kann das Scraping beginnen. Rufen Sie dafür einfach die mobile.de Seite auf und kopieren Sie die URL. Danach nur noch in die Suchleiste kopieren. Mit dem “Start” Button wird die Suche gestartet.
2. Schritt: Den automatischen Erkennungsmodus starten und den Workflow festlegen
Sobald der “Start” Button geklickt wurde, werden Sie in den automatischen Erkennungsmodus versetzt. Durch die Festlegung des Workflows können Sie die gesuchten Daten festlegen. Die vorgegebenen Datenfelder können sehr einfach angepasst bzw. verändert werden. Haben Sie alles angepasst, dann starten Sie die Suche mit dem Start-Button.
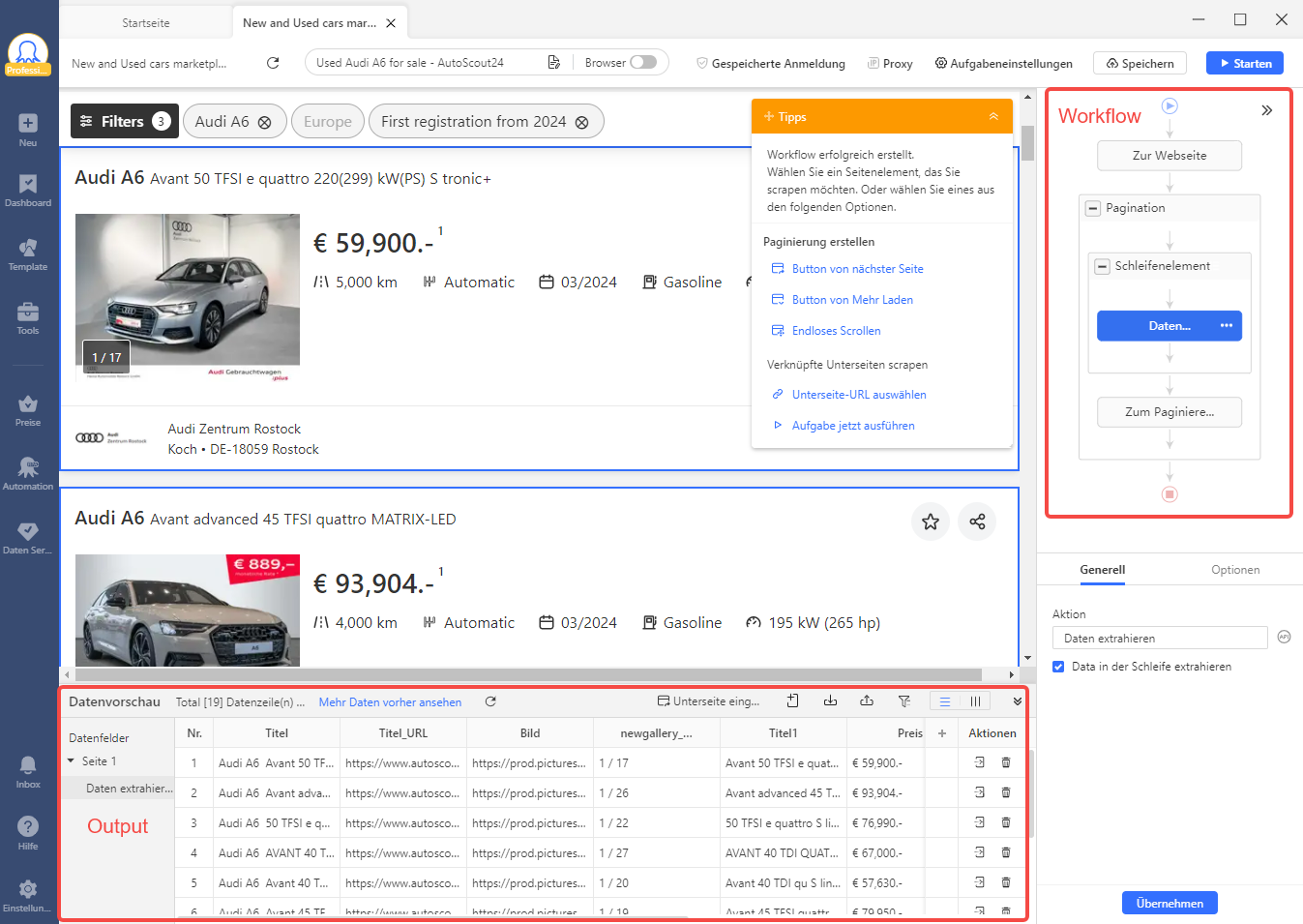
3. Schritt: Die erhaltenen Daten speichern
Wurden die Daten geliefert, können Sie sie überprüfen und danach können die Daten in einer beliebigen Datei gespeichert werden. Sie können frei wählen, welche Datei Sie bevorzugen. In der Regel handelt es sich dabei um JSON, eine Excel-Tabelle oder CSV. Jetzt stehen Ihnen die Daten jederzeit zur Verfügung, um sie auszuwerten.
Wenn Sie Daten von AutoScout sammeln möchten, können Sie sich der Artikel „Der AutoScout24 Scraper von Octoparse – rasch und einfach Daten sammeln“ als Referenz zu Rate ziehen.
Vereinfachung des mobile.de scrapen mit Octoparse
Octoparse macht das Daten-Scrapen enorm einfach. Besonders die Daten von Automobil Verkaufsplattformen können mit der passenden Vorlage sehr einfach ausgelesen werden. Sie können die AutoScout24 Vorlage als mobile.de Scraper verwenden! Diese Vorlage kann ganz einfach angepasst werden.
Octoparse bietet somit die Möglichkeit, einen Workflow wie bereits beschrieben, zu erstellen. Sie können aber auch die AutoScout24 Vorlage mit den eigenen Suchparametern konfigurieren. So erhalten Sie spielend leicht alle notwendigen Informationen. Zum Beispiel den Kilometerstand, den Preis oder die Kontaktdaten des Anbieters.
Vorgehensweise für die Verwendung der Vorlage für AutoScout24:
- Wählen Sie die Vorlage und passen Sie die Suchparameter an, dazu gehört auch die URL-Eingabe von mobile.de.
- Sobald die Suchparameter oder Suchbegriffe festgelegt wurden, kann mit dem Start-Button die Suche gestartet werden.
- Nach dem Drücken des Start-Button beginnt der Scraping-Prozess zu laufen. Die Daten werden dabei gesammelt und für die Ausgabe vorbereitet.
- Sobald die gesammelten Daten ausgegeben wurden, können Sie diese in unterschiedlichen Formaten nach Bedarf speichern. Zum Beispiel in einer Excel-Tabelle, JSON oder CVS. Sie können die Daten aber auch einfach herunterladen und in einer Datenbank abspeichern.
Daten die von mobile.de ausgelesen werden können
Mit Octoparse kann man in kurzer Zeit alle verfügbaren Daten über entsprechende Fahrzeuge erhalten. Haben Sie den Workflow mit den benötigten Suchparametern festgelegt oder die Vorlage entsprechend angepasst, dann kann das Datenauslesen beginnen.
Die folgenden Informationen können dadurch erhalten werden:
- den Kilometerstand der angebotenen Fahrzeuge
- die wichtigsten Informationen zum Fahrzeug
- die Preise der Fahrzeuge
- die Kontaktdaten des Fahrzeuganbieters
- die URL der Web-Anzeige zum einfachen Aufrufen
Diese Informationen sind nur ein kleiner Auszug aus der Fülle der Informationen, die ausgelesen werden können!
Kann man legal Daten von mobile.de auslesen?
Auf der Startseite von Mobile.de wird bereits die Möglichkeit geboten, mittels eines detaillierten Filters ein Fahrzeug einfach zu finden. In der Regel ist es jedoch so, dass oft mehrere Anbieter das gleiche Fahrzeug zu unterschiedlichen Preisen anbieten. Um hier das geeignete Angebot zu finden, eignet sich hervorragend Octoparse zum Daten auslesen. Das Daten-Scrapen ist wie bei anderen Webseiten so lange legal, solange man sich an die Vorschriften und Regelungen hält. Das bedeutet, dass man die Daten sorgfältig nutzt und personenbezogene Daten mit großer Sorgfalt nutzt. Zum Beispiel Kontaktadressen der Verkäufer bzw. Anbieter. Werden die Vorschriften eingehalten, ist das Scrapen von Daten bei mobile.de legal.
FAQs
Kann eine Vorlage von Octoparse zum Scraping auf mobil.de verwendet werden?
Octoparse bietet rund 500 Vorlagen, um das Daten Scrapen zu vereinfachen. Für mobile.de gibt es keine spezielle Vorlage! Es steht aber die Vorlage für AutoScout24 zur Verfügung, die auch für jede andere Fahrzeugmarkt-Plattform einfach angepasst werden kann!
Welche Daten können mit dem mobile.de Scraper ausgelesen werden?
Wie immer gilt hier für das Scrapen im Internet, dass nur öffentlich zur Verfügung gestellte Daten ausgelesen werden dürfen. Personenbezogene und persönliche Daten sind laut DSGVO besonders geschützt und dürfen nicht ausgelesen werden.
Ist das Daten Scraping mit Octoparse legal?
Octoparse hält sich an die Vorschriften und Richtlinien, die in der DSGVO enthalten sind. Werden diese Regelungen durch einen Nutzer von Octoparse eingehalten, ist das Web Scraping legal und nicht verboten!
Zusammenfassung
Der mobile.de Scraper von Octoparse, genau genommen die konfigurierte AutoScout24 Vorlage, macht es möglich, rasch und unkompliziert die gesuchten Daten auszulesen. Möchten Sie Informationen über Ihr zukünftiges Auto erhalten oder den Preis für Ihr Fahrzeug für den Verkauf ermitteln?
Mit Octoparse erhalten Sie alle gewünschten Informationen in kurzer Zeit. Sie können damit sehr viel Zeit sparen und erhalten eine enorme Hilfe bei der Entscheidungshilfe. Testen Sie das hilfreiche Tool von Octoparse gleich heute gratis! Lassen Sie sich von der Einfachheit und zuverlässig überzeugen. Einfacher geht das Daten-Scrapen nicht!
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



