Suchen Sie nach einem Google Bilder Scraper, um Google Images ohne das Schreiben von Code zu extrahieren? Oder benötigen Sie vielleicht eine Python-basierte Lösung, um in großem Maßstab Bildmaterial für KI Training zu sammeln?
Da Google keine offizielle Bildersuche-API anbietet, bleibt das Scraping der effektivste Weg, um Bilddaten in großen Mengen von Google Images zu sammeln. Octoparse untersucht die fünf besten Scraping-Tools, die wir 2026 getestet haben, und bietet klare Einblicke in ihre Stärken und Schwächen.
Kurzer Überblick:
Ein Google Bilder Scraper extrahiert automatisch wichtige Daten wie Bild-URLs, Alt-Texte, Abmessungen und Quellseiteninformationen aus den Google-Bildersuchergebnissen. Hier ist eine Aufschlüsselung der besten verfügbaren Tools:
- Octoparse ist die beste No-Code-Option für Benutzer ohne technischen Hintergrund.
- Apify ist perfekt für Entwickler, die mit APIs vertraut sind.
- Python mit Playwright ist ideal für Ingenieure, die volle, benutzerdefinierte Kontrolle benötigen.
- SerpAPI eignet sich hervorragend für strukturierte JSON-Ausgaben über eine API.
- Outscraper ist am besten für schnelles, Cloud-basiertes Scraping ohne Einrichtung geeignet.
Was ist ein Google Bilder Scraper?
Ein Google Bilder Scraper ist ein Tool, das den Prozess der Suche in Google Images automatisiert und strukturierte Daten aus den Ergebnissen extrahiert, wie z. B. Bild-URLs, Alt-Texte, Quellseiten-URLs, Bildabmessungen und Thumbnails.
Warum Scrapen statt einer offiziellen Suchmaschinen API JSON?
Google bietet keine dedizierte Bildersuch-API an. Die Custom Search JSON API, die der offiziellen Option am nächsten kommt, beschränkt die Bildergebnisse auf 10 pro Abfrage und berechnet 5 $ pro 1.000 Abfragen nach dem kostenlosen Limit von 100 Abfragen. Seit 2025 können neue Nutzer nicht mehr auf diese API zugreifen, und bestehende Nutzer müssen bis 2027 zu Vertex AI Search wechseln.
Web Scraper interagieren im Gegensatz dazu wie ein Browser mit Google Images und extrahieren die Ergebnisse in strukturierte Formate (CSV, Excel, JSON).
In unserem Test im Jahr 2026 hätte das Abrufen von 1.000 Bild-URLs über Googles Custom Search API 4,50 $ gekostet und neun separate Abrechnungszyklen erfordert. Die gleichen 1.000 URLs dauerten mit einem anderen kostenlosen Google Bilder Scraper nur 4 Minuten und kosteten 0 $.
Ist das Scrapen von Google Images legal?
In den USA ist das Scrapen öffentlich zugänglicher Daten im Allgemeinen legal, wie durch das Urteil hiQ Labs v. LinkedIn von 2022 klargestellt wurde. Dies gilt jedoch nur für den Computer Fraud and Abuse Act (CFAA) und setzt andere rechtliche Erwägungen wie das Urheberrecht oder die Nutzungsbedingungen einer Website nicht außer Kraft.
Das Scrapen von Metadaten (z. B. URLs, Alt-Texte, Abmessungen) unterscheidet sich vom Herunterladen und Weiterverbreiten von Bilddateien. Bilddateien sind in der Regel urheberrechtlich geschützt, sodass eine Weiterverbreitung ohne Erlaubnis gegen das Urheberrecht verstoßen kann.
Best Practices:
- Überprüfen Sie vor dem Scrapen immer die Nutzungsbedingungen und die robots.txt-Datei einer Website.
- Für die kommerzielle Nutzung sollten Sie einen Rechtsexperten konsultieren, um die Einhaltung der relevanten Gesetze sicherzustellen. Dieser Artikel stellt keine Rechtsberatung dar.
Was können Sie mit gescrapten Google-Bildern tun?
Wenn Sie einen Google Bilder Scraper auswählen, sollten Sie diese häufigen Anwendungsfälle berücksichtigen:
- KI- und ML-Datensätze: Forscher erstellen große, gekennzeichnete Datensätze für KI-Modelle und beschleunigen so den Prozess im Vergleich zur manuellen Datenerfassung.
- Visuelle Überwachung von Wettbewerbern: Marken verfolgen Produktbilder von Wettbewerbern, um ihre visuelle Strategie in den Bereichen E-Commerce, Mode und Konsumgüter zu verbessern.
- Marktforschung: Das Scrapen von Bildergebnissen hilft Unternehmen, Trends bei Verpackungen, Farben und Produktformaten zu erkennen.
- E-Commerce-Produktsammlung: Einzelhändler müssen produktdaten für onlineshops crawlen, um Kataloge und Preisvergleichsseiten zu erstellen.
- Akademische Forschung: Forscher sparen Zeit bei manuellen Downloads, indem sie Bilder für groß angelegte visuelle Analysen scrapen.
Die 5 besten Google Bilder Scraper im Jahr 2026
⭐ Wie wir getestet haben ⭐ Wir haben jedes Tool mit drei Suchbegriffen getestet: „product packaging design“, „modern office design“ und „cat breeds“. Unsere Bewertung konzentrierte sich auf die folgenden Schlüsselfaktoren:
- Einrichtungszeit: Zeit von der Anmeldung bis zum ersten Export.
- Bildabruf: Anzahl der innerhalb von 10 Minuten gescrapten Bilder.
- Fehlermodi: Alle während des Tests aufgetretenen Probleme.
Wir haben die Tools auch anhand von fünf Kriterien bewertet:
- Einrichtungskomplexität
- Umgang mit dynamischem JavaScript-Rendering
- Datenqualität (vollständige Metadaten vs. nur Bilddateien)
- Unterstützung für Cloud-Ausführung & Zeitplanung
- Preistransparenz
1. Octoparse: Der beste No-Code Google Bilder Scraper
Am besten für: Nicht-technische Anwender, Vermarkter, Ersteller von KI-Datensätzen, akademische Forscher
Octoparse ist eine No-Code-Web-Scraping-Plattform, die es Benutzern ermöglicht, in weniger als fünf Minuten einen Google Bilder Scraper zu erstellen, indem sie eine vorgefertigte Octoparse Web-Scraping-Vorlage verwenden.
Sie können es auf zwei Arten ausführen: direkt in Ihrem Browser über die Octoparse-Web-App oder indem Sie Octoparse für Windows und Mac herunterladen. Beide Optionen verwenden dieselbe Vorlage und erzeugen identische Ausgaben.
Die KI-Auto-Detect-Funktion analysiert die Seitenstruktur und identifiziert automatisch die erforderlichen Datenfelder. Exporte sind in CSV, Excel, Google Sheets oder über eine API verfügbar.
⭐ Testergebnisse: In unserem Test lieferte die Google Bilder Scraper Vorlage von Octoparse 459 Bildzeilen in 21 Minuten und 42 Sekunden für die Suchanfrage „cut dog“. Der Lauf erfolgte auf 20 Cloud-Knoten ohne jegliche CAPTCHA-Auslöser. Die exportierte CSV enthielt neun Spalten:
- Query, Title, Title_URL, Source, Full_image, Full_image_size, Thumbnail_image, Thumbnail_width, Thumbnail_height.
Hauptfunktionen:
- Unterstützung für dynamisches Rendering: Verarbeitet Infinite Scrolling und verzögert geladene Bilder (Lazy Loading) mit der integrierten Browser-Engine.
- Cloud-Modus: Führt Scraper auf den Servern von Octoparse für einen 24/7-Betrieb aus und spart lokale Ressourcen.
- Vorgefertigte Vorlagen: Kostenlose Vorlage für das Scraping von Google Images. Geben Sie ein Keyword ein, wählen Sie den lokalen oder Cloud-Modus und exportieren Sie die Ergebnisse. Unterstützt bis zu 10.000 Keywords für die Stapelverarbeitung.
- Umfassende Ausgabe: Extrahiert die vollständige Bild-URL, das Thumbnail, den Alt-Text, die Quelle und die Abmessungen in einem Durchlauf.
- Optionaler Proxy-Zugriff: Leitet Scraper über rotierende IPs für große Datenmengen oder eingeschränkte Regionen.
| Vorteile | Nachteile |
| ✅ Keine Programmierung erforderlich, funktioniert sowohl im Browser als auch im Desktop-Client, keine Installation nötig ✅ KI-Auto-Erkennung für Bild-URL, Alt-Text, Quelle und Abmessungen ✅ Verarbeitet dynamische Seiten und Infinite Scrolls nativ ✅ Cloud-basierte Zeitplanung mit 24/7-Scraping ✅ DSGVO- und CCPA-konform ✅ Vorgefertigte Vorlagen für schnellere Einrichtung ✅ Stapelverarbeitung unterstützt bis zu 10.000 Keywords pro Aufgabe | ❌ Cloud-Scraping verbraucht Plan-Credits ❌ Größere Scraping-Aufgaben können im Vergleich zu API-First-Tools langsamer sein |
- Kostenloser Plan verfügbar (lokales Scraping, begrenzte Cloud-Läufe)
- Kostenpflichtige Pläne beginnen bei 69 $/Monat, mit einer 5-tägigen Geld-zurück-Garantie auf alle kostenpflichtigen Pläne.
Was Benutzer auf Trustpilot sagen:
Ich habe Octoparse entdeckt, als ich nach einem besseren Weg suchte, große Mengen an Webdaten zu scrapen. Nachdem ich manuelle Methoden und grundlegende Tools ausprobiert hatte, stach Octoparse als die leistungsstärkste und zeitsparendste Option hervor. Es ist genau, flexibel und einfach zu bedienen, selbst für kleine oder persönliche Projekte. Das Support-Team war ebenfalls unglaublich reaktionsschnell.
Ehrliche Einschränkungen:
Octoparse eignet sich hervorragend zum Extrahieren strukturierter Metadaten wie URLs und Alt-Texte, ist jedoch nicht für Bildbearbeitungsaufgaben (z. B. Größenänderung oder Klassifizierung) geeignet. Dafür wären zusätzliche Tools erforderlich. Größere Batch-Jobs (Tausende von Keywords) erfordern einen kostenpflichtigen Plan für Cloud-Knoten, da der kostenlose Plan nur lokale Single-Thread-Läufe unterstützt.
Unser Fazit: Für das regelmäßige Scraping von Google Images ohne Programmierung ist Octoparse die praktischste Lösung im Jahr 2026. Seine KI-gesteuerte Felderkennung und Cloud-basierte Zeitplanung machen es ideal für nicht-technische Benutzer und sparen Zeit bei der Einrichtung und Konfiguration.
👉 Starten Sie eine kostenlose Octoparse-Testversion | https://www.octoparse.de/template/google-image-scraper
https://www.octoparse.de/template/google-image-scraper
2. Apify: Am besten für Entwickler und API-Workflows
Am besten für: Entwickler, die eine API-Integration benötigen und mit Actor-basierten Plattformen vertraut sind.
Der Google Bilder Scraper von Apify ist ein von der Community erstellter „Actor“ (containerisierte Scraping-Aufgabe) auf ihrer Cloud-Plattform. Er extrahiert Bild-URLs, Alt-Texte, Titel, Abmessungen, Thumbnail-URLs und Quellseitendaten und exportiert in JSON-, CSV-, Excel- oder HTML-Formate.
⭐ Testergebnisse
In unserem Test zog der Scraper von Apify 500 Bilder in 2 Minuten und 40 Sekunden und verbrauchte dabei etwa 0,14 Compute Units (CU). Zum Tarif des Scale-Plans von 0,25 $ pro CU kostet dies etwa 0,035 $ pro 500 Bilder (ohne die vom Actor-Betreuer festgelegten Gebühren pro Ereignis).
Apify verwendet ein Pay-per-Event-Preismodell, bei dem basierend auf den zurückgegebenen Bildergebnissen abgerechnet wird. Der kostenlose Plan enthält 5 $ an monatlichen Credits, was für kleine bis mittlere Extraktionen ausreicht.
Wichtige Stärken für Entwickler:
- API-Integration: Lösen Sie Scraper-Läufe programmgesteuert über eine REST-API aus.
- Actor-Verkettung: Verknüpfen Sie sich mit anderen Actors, wie z. B. „Download Images From Dataset“, um Bilddateien in großen Mengen herunterzuladen.
- Cloud-Service-Integration: Verbinden Sie sich über Webhooks mit anderen Cloud-Diensten.
| Vorteile | Nachteile |
| ✅ Flexible API für programmgesteuerte Kontrolle ✅ Kann mit anderen Actors für erweiterte Funktionalität verkettet werden ✅ Skalierbar über Webhooks und Cloud-Integrationen ✅ Unterstützt mehrere Ausgabeformate (JSON, CSV, Excel, HTML) | ❌ Erfordert Kenntnisse des Actor-Modells und der Compute Units von Apify ❌ Aufgrund der Komplexität nicht für nicht-technische Benutzer geeignet ❌ Von der Community erstellter Actor, Zuverlässigkeit hängt von einzelnen Entwicklern ab |
Preise:
- Kostenloser Plan mit 5 $ in Credits monatlich
- Pay-per-Event-Preise basierend auf der Extraktion pro Bild, mit vollständigen Preisdetails auf der Preisseite von Apify.
Was Benutzer auf Trustpilot sagen:
Der größte Reibungspunkt ist die Lernkurve, wie z. B. das Verständnis von Compute Units, das Navigieren in Actor-spezifischen Preisen und das Vertrautwerden mit dem Dashboard, was alles im Vorfeld echte Zeit in Anspruch nimmt.
Ehrliche Einschränkungen: Apify ist großartig für Entwickler, aber das Actor-Modell und die API-Integration können für nicht-technische Benutzer eine Herausforderung darstellen. Da der Google Bilder Scraper ein von der Community erstellter Actor ist, hängen seine Wartung und Zuverlässigkeit vom jeweiligen Entwickler ab, nicht von Apify selbst.
Unser Fazit: Wenn Sie über technische Ressourcen verfügen oder Entwickler sind, bietet Apify durch seine API- und Cloud-Integrationen eine hohe Flexibilität und Skalierbarkeit. Es ist jedoch nicht die beste Option für nicht-technische Benutzer, die nach einer einfacheren No-Code-Lösung suchen.
3. Python + Playwright (oder Selenium): Das Beste für Ingenieure, die volle Kontrolle benötigen
Am besten für: Software-Ingenieure, die mehr Kontrolle über den Scraping-Prozess benötigen, wenn Standard-Tools zu einschränkend sind.
Die Verwendung von Python mit Playwright (oder Selenium) bietet Ingenieuren die vollständige Kontrolle, ideal für benutzerdefinierte Lösungen wie spezifische Paginierungslogik, Auflösungsfilterung oder die Integration in ML-Pipelines. Beide Bibliotheken sind kostenlos und Open-Source.
⭐ Testergebnisse: In unserem Test extrahierte ein Baseline-Playwright-Skript 180 Bild-URLs, bevor bei Anfrage 85 ein Ratenbegrenzer ausgelöst wurde. Durch die Verwendung eines Residential Proxys (8 $/GB) haben wir die Sitzung auf 600+ URLs verlängert. Die Einrichtungszeit für einen Entwickler, der neu bei Playwright ist, betrug etwa 30 Minuten, einschließlich der Installation von Chromium und der Überprüfung von Selektoren.
Wie es funktioniert:
- Starten Sie einen Headless-Browser.
- Navigieren Sie mit Ihrer Suchanfrage zu Google Images.
- Warten Sie, bis der dynamische Inhalt geladen ist.
- Extrahieren Sie
img-Tags und zugehörige Metadaten (URLs, Alt-Texte usw.).
Warum Playwright statt Selenium im Jahr 2026? Playwright wird Selenium im Allgemeinen aufgrund seiner Async-Unterstützung und der zuverlässigeren Elementerkennung vorgezogen, was es zu einer stabileren Wahl für 2026 macht.
⚠️ Zwei häufige Fallstricke bei diesem Ansatz:
- Häufige Frontend-Änderungen: Die HTML-Struktur von Google wird oft aktualisiert, wodurch Selektoren wie img.YQ4gaf brechen. Untersuchen Sie die Seite immer zuerst.
- Base64-Thumbnails: Das
src-Attribut gibt oft Base64-Thumbnails anstelle von vollständigen URLs zurück. Klicken Sie auf jedes Ergebnis, um die vollständige URL zu extrahieren.
| Vorteile | Nachteile |
| ✅ Volle Kontrolle über die Scraping-Logik ✅ Kostenlos, Open-Source ✅ Anpassbar für komplexe Anforderungen ✅ Ideal für Pipeline-Integration | ❌ Hoher Wartungsaufwand aufgrund sich ändernder CSS-Selektoren ❌ Anfällig für Erkennung (Headless-Browser, CAPTCHAs) ❌ Kontinuierlicher technischer Aufwand für Zuverlässigkeit |
Ehrliche Einschränkungen: Während Python + Playwright (oder Selenium) leistungsstark ist, machen häufige HTML-Änderungen und Erkennungshürden es bei großen Mengen weniger praktisch. Für wiederkehrende Aufgaben sind verwaltete Tools oft zuverlässiger und kostengünstiger.
Unser Fazit: Großartig für einmalige Projekte oder Teams mit technischen Ressourcen. Für wiederkehrende Workflows bieten verwaltete Tools möglicherweise einen besseren langfristigen Wert.
4. SerpAPI: Am besten für saubere JSON-Ausgaben über eine API
Am besten für: Entwickler, die Google Images-Daten im strukturierten JSON-Format benötigen, ohne einen Browser zu verwalten.
SerpAPI bietet eine Suchmaschinen-Ergebnis-API mit einem dedizierten Endpunkt für Google Images. Mit einer einzigen HTTP-Anfrage können Sie strukturierte JSON-Daten abrufen und so die Notwendigkeit von Browser-Automatisierung, HTML-Parsing oder Selektor-Management umgehen. Es übernimmt die Proxy-Rotation, das Lösen von CAPTCHAs und das Rendering.
⭐ Testergebnisse:
- 1 Anfrage lieferte 100 Bildergebnisse in 1,3 Sekunden.
- Mittlere Antwortzeit über 20 Anfragen: 2,4 Sekunden.
- 75 $/Monat für 5.000 Suchen (~0,015 $ pro Abfrage).
- Zurückgegebene Daten: Original-Bild-URLs/Thumbnail-URLs/Titel /Quell-Domains/Bildabmessungen
| Vorteile | Nachteile |
| ✅ Saubere, strukturierte JSON-Ausgabe mit minimalem Einrichtungsaufwand ✅ Automatische Handhabung von Proxys, CAPTCHA und Rendering ✅ Einfache Integration mit Python, Node.js usw. ✅ Skalierbar für den produktiven Einsatz ✅ U.S. Legal Shield bei höheren Tarifen (bis zu 2 Mio. $) | ❌ Kein kostenloser Plan (beginnt bei 75 $/Monat) ❌ Begrenzte Metadaten (kein umgebender Seiteninhalt) ❌ Weniger kostengünstig für einmalige Recherchen |
Was Benutzer auf G2 sagen:
Das „Use it or lose it“-Credit-Modell wird oft kritisiert, da ungenutzte Suchen nicht in den nächsten Monat übertragen werden, was die effektiven Kosten für Projekte mit variablem Volumen erhöht.
Ehrliche Einschränkungen: SerpAPI eignet sich perfekt für die Extraktion strukturierter Daten, es fehlen jedoch die vollständigen kontextbezogenen Daten, die Full-Page-Scraper bieten. Die Preisgestaltung ist möglicherweise nicht ideal für den gelegentlichen Gebrauch.
⚠️ Rechtlicher Hinweis:
Im Dezember 2025 reichte Google eine DMCA-Klage gegen SerpAPI ein, weil das Anti-Scraping-System von Google umgangen wurde. Der Fall ist noch nicht abgeschlossen, eine Anhörung findet im Mai 2026 statt. Planen Sie in der Produktion einen Backup-Anbieter ein.
Unser Fazit: SerpAPI ist großartig für Entwickler, die zuverlässige, strukturierte Google Images-Daten benötigen. Das Fehlen eines kostenlosen Plans und der laufende Rechtsstreit machen es jedoch möglicherweise weniger geeignet für Gelegenheitsnutzer oder solche, die die Zuverlässigkeit eines einzigen Anbieters benötigen.
👉 Entdecken Sie die Google Images API von SerpAPI | Überprüfen Sie die Preisdetails
5. Outscraper: Am besten für schnelle Cloud-basierte Aufgaben ohne Einrichtung
Am besten für: Benutzer, die einen einfachen, browserbasierten Google Bilder Scraper ohne Installation benötigen.
Outscraper bietet einen Cloud-basierten Google Bilder Scraper, der keine Installation erfordert. Melden Sie sich einfach an, geben Sie Keywords ein und laden Sie die Ergebnisse als CSV oder Excel herunter. Ein kostenloser Tarif mit begrenzten Credits ist verfügbar.
⭐ Testergebnisse:
- Free-Tier-Credits deckten etwa drei Läufe mit jeweils 50 Bildern ab.
- Einrichtungszeit: Unter 2 Minuten bis zum ersten Export.
- Extraktionszeit: 35 Sekunden pro 50 Bilder.
- Zurückgegebene Daten: Bild-URLs/Quellseiten-URLs/Bildtitel/Thumbnail-Links
Hinweis: Outscraper extrahiert Alt-Texte nicht auf strukturierte Weise wie Octoparse oder Apify, was seine Verwendung für KI-Trainingsdatensätze einschränken könnte.
| Vorteile | Nachteile |
| ✅ Keine Installation erforderlich, läuft in der Cloud ✅ Einfache Benutzeroberfläche für schnelle, einmalige Scrapes ✅ Exporte in CSV oder Excel ✅ Kostenloser Tarif für begrenzte Nutzung verfügbar ✅ Ideal für gelegentliche Bildextraktion | ❌ Begrenzte Flexibilität für komplexe Scraping-Aufgaben (z. B. kein visueller Builder, eingeschränkte Zeitplanung) ❌ Keine vorkonfigurierte Vorlagenbibliothek ❌ Nicht ideal für wiederkehrendes oder Multi-Keyword-Scraping ❌ Inkonsistente Alt-Text-Extraktion im Vergleich zu anderen Tools |
Ehrliche Einschränkungen: Outscraper funktioniert gut für einmalige Aufgaben, es fehlen jedoch erweiterte Funktionen wie ein visueller Builder und komplexe Zeitplanung, was es für fortlaufende Scraping-Anforderungen ungeeignet macht.
Unser Fazit: Für schnelles, Cloud-basiertes Scraping ohne erforderliche Installation ist Outscraper eine großartige Wahl. Für komplexeres oder wiederkehrendes Scraping bieten Tools wie Octoparse oder Apify jedoch mehr Funktionen und Flexibilität.
👉 Starten Sie mit Outscraper | Entdecken Sie die verfügbaren Pläne
⭐ Erwähnenswerte Alternativen
Während die oben genannten fünf Tools die meisten Anwendungsfälle abdecken, sind hier einige weitere, die 2026 eine Überlegung wert sind:
- ScrapingBee’s Google Image Scraper API: Gibt strukturierte Bild-URLs, Metadaten und Alt-Texte zurück. Preise ab 49 $/Monat. Ideal für Entwickler, die einen einfachen HTTP-Endpunkt ohne umfassende Suchmaschinenabdeckung benötigen.
- ScraperAPI: Eine universelle Scraping-API mit Unterstützung für Google Images über ihren SERP-Endpunkt. Beginnt bei 49 $/Monat für 100.000 Credits. Großartig für Teams, die ScraperAPI bereits für andere Datenquellen verwenden.
- Scrapingdog’s Google Images API: Eine neuere Option mit Preisen pro Anfrage ab 0,001 $ pro Abfrage. Weniger ausgereifte Dokumentation als SerpAPI, aber kostengünstiger bei hohen Volumina.
Diese Optionen sind eine Erkundung wert, wenn Ihre Anforderungen nicht mit den fünf zuvor genannten Tools übereinstimmen.
Google Bilder Scraper Vergleichstabelle
| Tool | Am besten für | Einrichtungszeit | JS-Rendering | Startpreis | Kostenlose Option | Alt-Text-Erfassung |
| Octoparse | Nicht-Programmierer, geplante Läufe | 5 Min (Vorlage) | ✅ Nativ | 69 $/Mo | ✅ Kostenloser Plan (lokal) | ✅ Ja |
| Apify | Entwickler, API-Workflows | 10 Min + API-Schlüssel | ✅ Unterstützt | 29 $/Mo + pro Event | ✅ 5 $/Mo Credits | ✅ Ja |
| Python + Playwright | Ingenieure, eigene Logik | 30+ Min | Manuell | Kostenlos (Bibliotheken) | ✅ Komplett kostenlos | ✅ Wenn programmiert |
| SerpAPI | Sauberes JSON, Produktion | Unter 5 Min | ✅ Unterstützt | 75 $/Mo für 5K Abfragen | Begrenzt (100/Mo) | Teilweise |
| Outscraper | Einmalige Jobs, keine Install. | 2 Min | ✅ Unterstützt | Pay-as-you-go | ✅ Begrenzte Credits | ⚠️ Inkonsistent |
Wie man Google Images scrapt: Eine Schritt-für-Schritt-Anleitung
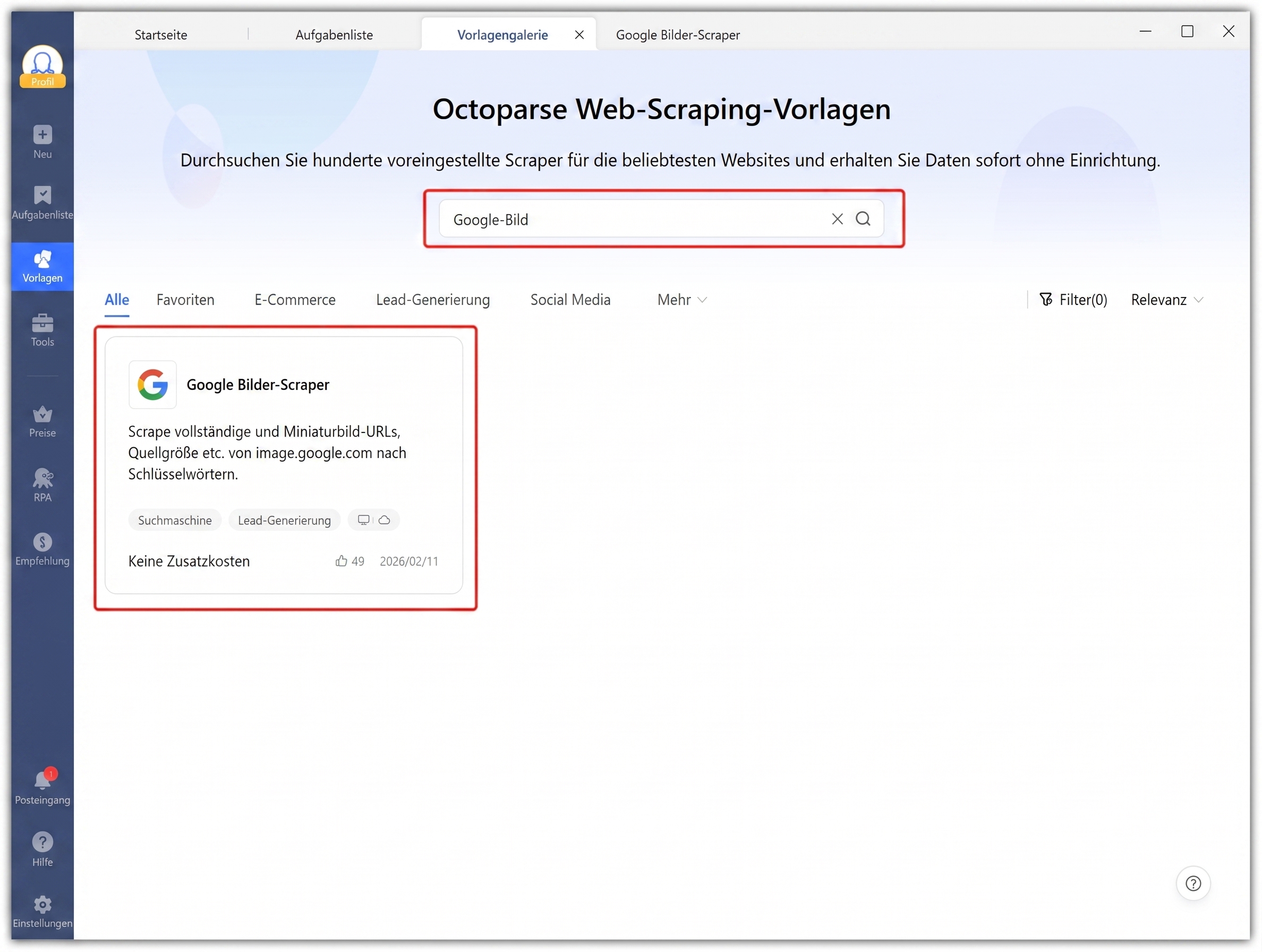
Der schnellste Weg, Google Images mit Octoparse zu scrapen, ist die Verwendung der vorgefertigten Google Bilder Scraper Vorlage. Es ist keine Einrichtung oder Selektorkonfiguration erforderlich. Geben Sie einfach Ihr Keyword ein und starten Sie den Lauf.
Schritt 1: Öffnen Sie die Vorlage
- Web: Besuchen Sie octoparse.de/template/google-image-scraper, melden Sie sich an oder erstellen Sie ein Konto und klicken Sie auf Try it!
https://www.octoparse.de/template/google-image-scraper
- Desktop: Öffnen Sie Octoparse, gehen Sie zu Templates > suchen Sie nach „Google image“ > wählen Sie die Vorlage aus.
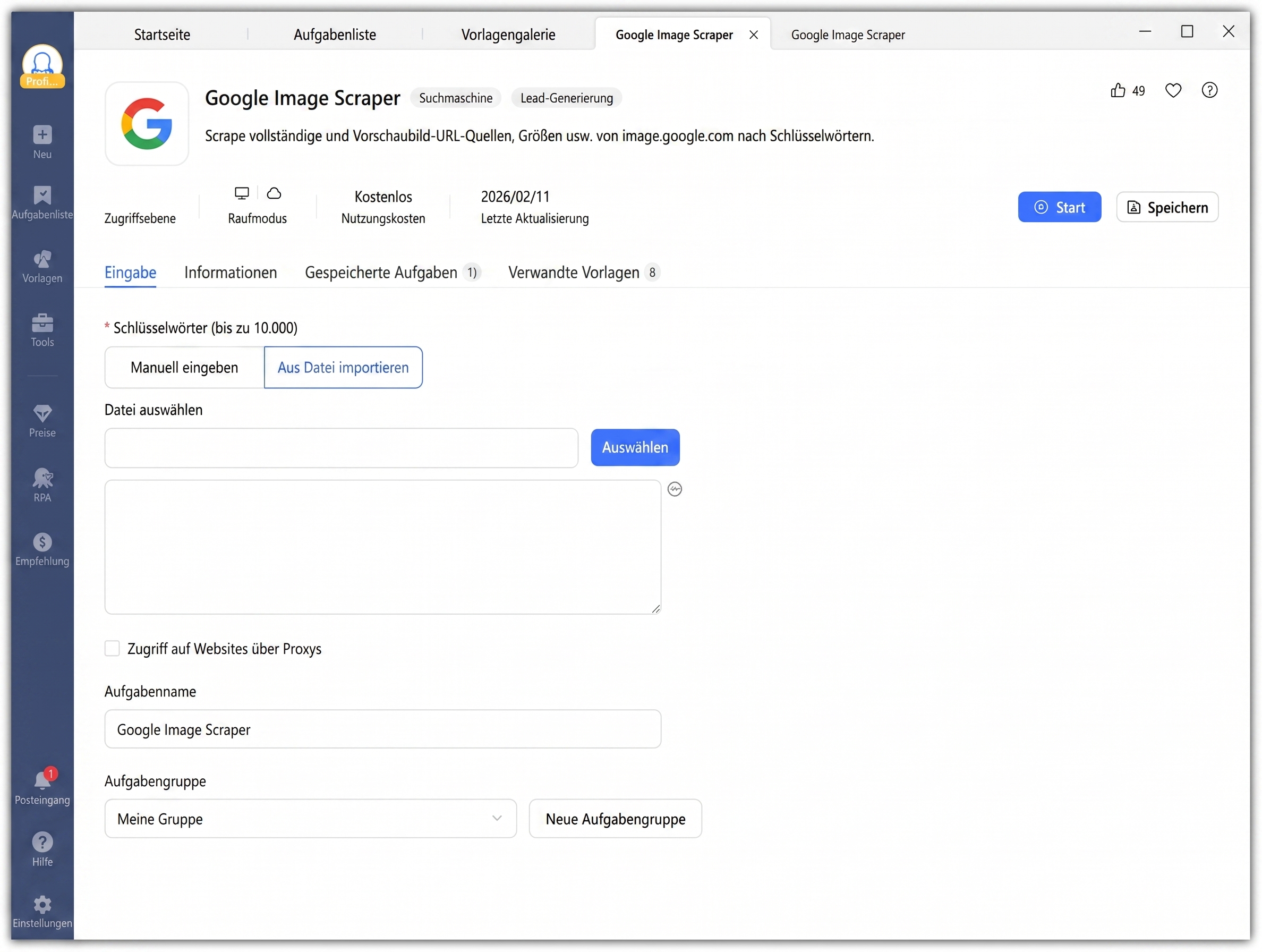
Schritt 2: Geben Sie Ihr Such-Keyword ein
Das Eingabefeld akzeptiert bis zu 10.000 Keywords. Sie haben zwei Optionen:
- Manuelle Eingabe: Geben Sie ein Keyword pro Zeile ein (z. B. „cut dog“ oder „product packaging design“).
- Datei-Import: Laden Sie eine TXT- oder CSV-Datei mit Keywords für große Stapel hoch.
- Optional: Aktivieren Sie „Access websites via proxies“ für rotierende IPs, um Drosselungen zu vermeiden.
Schritt 3: Aufgaben-Einstellungen konfigurieren (Optional)
Scrollen Sie nach unten zum Abschnitt Task Setting, um Ihre Aufgabe umzubenennen oder sie einer Gruppe zuzuweisen. Die Standardeinstellungen funktionieren für die meisten Anwendungsfälle gut.
Schritt 4: Führen Sie die Aufgabe aus
Klicken Sie auf Start und wählen Sie Ihren Ausführungsmodus:
- Run on Web / Run Locally: Läuft auf Ihrem Computer (gut für kleine Aufgaben).
- Run in Cloud: Läuft auf den Servern von Octoparse, ermöglicht geplante Aufgaben, verbraucht Plan-Credits.
Schritt 5: Überwachen Sie den Lauf
Verfolgen Sie den Fortschritt über die Seite Task Info: Status, Datenanzahl, aufgewendete Zeit, verwendete Cloud-Knoten und aufgetretene CAPTCHAs.
Schritt 6: Exportieren Sie Ihre Daten
Klicken Sie nach Abschluss auf Export Data und wählen Sie Ihr Format: CSV, Excel, Google Sheets oder JSON über API. Die Daten umfassen 9 Spalten wie Bild-URLs und Alt-Texte.
👉 Durchsuchen Sie die Octoparse-Vorlagenbibliothek Müssen Sie andere Google-Dienste scrapen? Octoparse bietet Vorlagen für das gesamte Google-Ökosystem:
- Google Maps Scraper: Firmennamen, Adressen, Bewertungen, Rezensionen, Telefonnummern und mehr für die Lead-Generierung und lokales SEO.
https://www.octoparse.de/template/google-maps-advanced-scraper
- Google Maps Email Finder: Kontakt-E-Mails, die aus Google Maps-Einträgen extrahiert werden, zum Preis von 0,5 $ pro 1.000 Zeilen.
https://www.octoparse.de/template/google-maps-contact-scraper
Für Entwickler, die Bilder mit Python scrapen möchten, lesen Sie unseren vollständigen Leitfaden darüber, wie man Daten mit Python crawlt.
Häufige Herausforderungen beim Scrapen von Google Images (und wie man sie löst)
Herausforderung 1: IP-Sperren und CAPTCHAs
Google blockiert IPs nach zu vielen Anfragen in kurzer Zeit.
Lösung:
- Verwenden Sie Cloud-basierte Scraper wie Octoparse, Apify oder Outscraper für die automatische Proxy-Rotation.
- Für Python-Skripte integrieren Sie Residential Proxies und fügen Verzögerungen hinzu (z. B. 1,5–4 Sekunden), um menschliches Verhalten nachzuahmen.
Herausforderung 2: Googles CSS-Selektoren ändern sich ohne Vorankündigung
Wenn Sie einen DIY-Python-Scraper verwenden, bricht die Selektor-basierte Extraktion stillschweigend ab, sobald Google ein Frontend-Update veröffentlicht. Diese Updates finden mehrmals im Jahr statt, und Ihr Skript liefert ohne Warnung leere Ergebnisse.
Lösung:
- Verwenden Sie visuelle No-Code-Scraper oder API-First-Dienste:
- Octoparse passt sich der Seitenstruktur mit einer Rendering-Engine an, anstatt sich auf statische Selektoren zu verlassen.
- Der Actor von Apify pflegt aktualisierte Selektoren, um mit den Änderungen von Google Schritt zu halten.
- Für Python überprüfen Sie, ob Ergebnisse zurückgegeben werden, und richten Sie Warnungen ein, wenn der Scraper nichts liefert.
Herausforderung 3: Headless Browser Fingerprinting
Google erkennt Headless Chromium-Browser anhand von Eigenschaften wie navigator.webdriver = true, fehlenden Plugins und inkonsistentem Viewport-Verhalten. Headless-Sitzungen werden schneller blockiert als reguläre.
Lösung:
- Verwenden Sie den Stealth-Modus von Playwright, um navigator.webdriver=false einzustellen, was die Erkennung erschwert.
- Verwenden Sie realistische Viewport-Abmessungen und einen plausiblen User-Agent-String.
- Cloud-Plattformen wie Octoparse erledigen dies unsichtbar und reduzieren so das Erkennungsrisiko im Vergleich zu DIY-Skripten.
Herausforderung 4: Urheberrecht und Bildnutzungsrechte
Während das Scrapen von Google Images Ihnen Metadaten liefern kann, sind Bilder oft urheberrechtlich geschützt. Das Herunterladen und Weiterverbreiten von Bildern ohne ordnungsgemäße Lizenzierung kann zu rechtlichen Problemen führen.
Lösung:
- Konzentrieren Sie sich auf das Sammeln von Bild-URLs und Metadaten, anstatt Bilddateien für Forschungszwecke oder KI-Trainingsdatensätze herunterzuladen.
- Verwenden Sie den Nutzungsrechte-Filter von Google für veröffentlichte Inhalte:
- Für Bilder mit Creative Commons-Lizenz verwenden Sie dieses Such-URL-Format:
- https://images.google.com/search?q=your+query&tbm=isch&tbs=il:cl
- Das
tbs=il:clfiltert nach Bildern mit Creative Commons-Lizenz. - Fügen Sie
&tbs=il:olhinzu, um Bilder zu erhalten, die eine kommerzielle Nutzung erlauben.
Häufig gestellte Fragen (FAQ)
Ist es legal, Google Images zu scrapen? In den USA ist das Scrapen öffentlich zugänglicher Daten im Allgemeinen unter dem hiQ v. LinkedIn Urteil (2022) legal, das klarstellte, dass Scraping nicht gegen den Computer Fraud and Abuse Act (CFAA) verstößt. Dies setzt jedoch das Urheberrecht, die Nutzungsbedingungen einer Website oder staatliche Ansprüche nicht außer Kraft.
Bei Google Images unterscheidet sich das Scrapen von Metadaten (z. B. URLs, Alt-Texte, Abmessungen) vom Herunterladen von Bilddateien. Da Bilder in der Regel urheberrechtlich geschützt sind, kann die Weiterverbreitung oder kommerzielle Nutzung ohne Erlaubnis dennoch zu rechtlichen Problemen führen.
Hat Google eine offizielle Bildersuch-API?
Nein. Die Custom Search JSON API von Google unterstützt die Bildersuche, beschränkt die Antworten jedoch auf 10 Ergebnisse pro Abfrage und ist nicht für die Massenextraktion geeignet. Die Google Photos API funktioniert nur mit persönlichen Bibliotheken, nicht mit der allgemeinen Bildersuche. Für die massenhafte Bildersammlung sind Web-Scraping-Tools praktischer.
Wie scrape ich Google Images ohne Python?
Verwenden Sie ein No-Code-Tool wie Octoparse. Öffnen Sie die Google Bilder Scraper Vorlage im Browser oder in der Desktop-App, geben Sie Ihr Such-Keyword ein, lassen Sie die Vorlage den Rest erledigen und exportieren Sie dann in CSV oder Google Sheets. Es sind keine Programmierkenntnisse erforderlich.
Welche Daten kann ich aus Google Images extrahieren?
Ein Google Bilder Scraper kann Folgendes sammeln:
- Bild-URL: Direkter Link zur Bilddatei
- Thumbnail-URL: Vorschauversion
- Alt-Text: Beschreibender Text
- Quellseiten-URL: Wo das Bild gefunden wurde
- Bildtitel: Das Titelattribut des Bildes
- Bildabmessungen: Breite und Höhe in Pixeln
Überprüfen Sie die Ausgabe Ihres Tools, um sicherzustellen, dass es die benötigten Daten erfasst.
Wie lade ich massenhaft Bilder von Google Images herunter?
Das Scraping liefert Bild-URLs, aber das Herunterladen der tatsächlichen Bilder ist ein separater Schritt:
- Exportieren Sie in Octoparse die URL-Liste nach CSV und verwenden Sie dann ein Batch-Download-Tool oder ein Python-Skript.
- Verketten Sie in Apify den Google Images Scraper Actor mit dem „Download Images From Dataset“ Actor zur Automatisierung.
- Für Python-Benutzer fügen Sie nach dem Scraping eine
requests.get(image_url)-Schleife hinzu, um jedes Bild herunterzuladen.
Welcher Google Bilder Scraper ist kostenlos?
Mehrere Tools bieten kostenlose Tarife an. Der kostenlose Plan von Octoparse umfasst die Google Bilder Scraper Vorlage mit bis zu 50.000 Zeilen pro Monat für lokale Läufe. Der kostenlose Plan von Apify bietet 5 $ an monatlichen Credits, genug für Hunderte kleiner Extraktionen. Python mit Playwright ist völlig kostenlos auszuführen, obwohl bei großen Volumina Residential Proxies (8–15 $/GB im Jahr 2026) erforderlich sind. Outscraper bietet begrenzte kostenlose Credits. SerpAPI bietet einen kostenlosen Tarif zum Testen, erfordert jedoch für den produktiven Einsatz einen kostenpflichtigen Plan ab 75 $/Monat.
Fazit
Die Wahl des richtigen Google Bilder Scrapers hängt von Ihren Anforderungen ab. Für nicht-technische Benutzer bietet Octoparse eine einfache No-Code-Lösung. Entwickler, die mehr Kontrolle benötigen, können sich für Apify oder Python mit Playwright entscheiden, wobei letzteres mehr Wartung erfordert. Wenn Sie nach einem einfachen, Cloud-basierten Tool ohne Installation suchen, ist Outscraper eine solide Option für schnelle Aufgaben. Wählen Sie letztendlich ein Tool basierend auf Ihrer Nutzungshäufigkeit, Ihren Anpassungsanforderungen und Ihrem technischen Fachwissen.

Scrapen Sie Daten einfach mit Auto-Detect-Funktionen, es sind keine Programmierkenntnisse erforderlich.
Voreingestellte Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Werden Sie dank IP-Proxys und erweiterter API niemals blockiert.
Cloud-Service zur Planung des Daten-Scrapings zu jeder gewünschten Zeit.